
国際特許分類[G06F17/28]の内容
物理学 (1,541,580) | 計算;計数 (381,677) | 電気的デジタルデータ処理 (228,215) | 特定の機能に特に適合したデジタル計算またはデータ処理の装置または方法 (34,028) | 自然言語データの取扱い (7,890) | 自然言語の処理または翻訳 (1,147)
国際特許分類[G06F17/28]に分類される特許
71 - 80 / 1,147
言語変換装置、言語変換方法及び言語変換プログラム
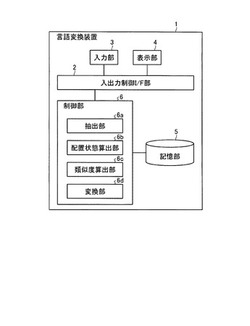
【課題】トレーサビリティマトリクスを容易に作成すること。
【解決手段】抽出部は、文字ファイルに含まれる文字列を相互の関連性に従って解析することで求めた文字ファイルの木構造において、各ノードに配置された文字列から第1の言語で示された所定の文字列群である第1文字列群と第2の言語で示された所定の文字列群である第2文字列群とをそれぞれ抽出する。配置状態算出部は、第1文字列群及び第2文字列群に含まれる文字列それぞれについて、木構造における配置状態から文字列相互の影響度を算出する。類似度算出部は、影響度に基づいて、第1文字列群に含まれる第1文字列に対する第2文字列群に含まれる第2文字列の関連性の高低を示す類似度をそれぞれ算出する。変換部は、文字ファイルにおける第1文字列を類似度が最も高い第2文字列に変換する。
(もっと読む)
機械翻訳装置、方法およびプログラム

【課題】翻訳結果を得るまでの時間を短縮できるとともに、信頼度の高い機械翻訳結果を得ることができる機械翻訳装置を提供する。
【解決手段】言い換え文生成手段81は、入力されたテキスト文と同一の言語でそのテキスト文の内容を示す別の表現へ言い換えた1つまたは複数の言い換え文を生成する。機械翻訳手段82は、言い換え文を翻訳後の言語である目的言語へと機械翻訳する。翻訳信頼度決定手段83は、目的言語へ翻訳された言い換え文の信頼度を示す翻訳信頼度を決定する。言い換え文特定手段84は、言い換え文生成手段81が生成した言い換え文の中から、翻訳信頼度に基づいて言い換え文の候補を抽出し、候補の中から翻訳の対象とする言い換え文である翻訳対象言い換え文を特定する。
(もっと読む)
フォレンジックシステム及びフォレンジック方法並びにフォレンジックプログラム
【課題】
翻訳済に関するデジタル文書情報を提出するに際し、訴訟の証拠資料作成のための作業負荷の軽減を図ることができる。
【解決手段】
デジタル情報を記録部に記録し、記録されたデジタル情報と利用者情報とを表示し、デジタル文書情報に含まれる少なくとも1以上の文書ファイルの指定を受け付け、該指定された文書ファイルをいずれの言語に翻訳するかの指定を受け付け、指定を受け付けた文書ファイルを、記指定を受け付けた言語に翻訳し、記録部に記録されたデジタル文書情報から、指定された文書ファイルと同一の内容を示す共通文書ファイルを抽出し、多言語に対応した全文検索機能を実行する。
(もっと読む)
情報検索翻訳システム、情報検索サーバ、通信端末、情報検索翻訳方法及び情報検索翻訳装置
【課題】情報の検索機能と翻訳機能との連携を実現し、使用頻度の高い質問についての翻訳文を、検索結果を反映させた態様で、正確かつ迅速に提供できるようにする。
【解決手段】 地図検索サーバから提供された検索結果情報を含む翻訳文の作成指示を、キー操作部411を通じて受け付ける。この場合に、穴埋め翻訳処理部434が、翻訳DB431から目的とする翻訳文を読み出し、当該目的とする翻訳文の所定の位置に、選択された検索結果情報に対応する翻訳情報を挿入して、翻訳文を完成させる。この完成させた翻訳文を、表示制御部412を通じて表示部413の表示画面に表示する。
(もっと読む)
情報機器、情報処理方法および情報処理プログラム
【課題】外部機器への接続時にユーザが容易に理解できる文字列を外部機器に表示させることができる情報機器、情報処理方法および情報処理プログラムを提供する。
【解決手段】デジタルカメラ1は、外部機器100に表示される文字列を含み、外部機器100への接続時に外部機器100により読み出されるファイルを記憶する記憶部6と、前記ファイルに含まれる前記文字列を、変換前と異なる言語で表現され、かつ、変換前と同じ意味を持つ文字列に変換する変換手段12と、を備える。
(もっと読む)
例文検索装置、処理方法およびプログラム
【課題】複数の異なる言語の入力キーワードに基づいて特定言語の例文を検索する例文検索装置、処理方法およびプログラムを提供する。
【解決手段】複数の例文を記憶する例文データベースと、所定言語と異なる特定言語の語句ごとに、その語句と、その語句の訳語である所定言語の語句と、を互いに対応付けて記憶する辞書データベースと、所定言語のキーワードと、特定言語のキーワードと、をそれぞれ受け付ける入力部と、辞書データベース内の所定言語の語句のうち、特定言語のキーワードに対応付けられた訳語を訳語キーワードとして検出する検索式生成部と、例文データベース120内の例文の中から、所定言語のキーワードと訳語キーワードとの少なくとも一方を含む例文を検索し、その検索結果を出力する検索部と、を含む。
(もっと読む)
文章生成装置及び文章生成方法
【課題】文章の作成を適切に支援する技術を提供する。
【解決手段】文章生成装置10は、文の一部に取替部分を有するテンプレートを格納した管理テーブル60と、取替部分に代入すべき文字列をユーザから受け付ける際に、代入すべき文字列の内容を問う質問をユーザに提示する質問提示部42と、ユーザから受け付けた文字列を取替部分に代入したときに文の意味が通るようにするために、テンプレートにおける取替部分の前後の文脈に応じて、代入すべき文字列を入力するための領域の直前及び直後に直前文字列及び直後文字列をそれぞれ提示する前後文字列提示部44と、入力された文字列を取得して記録する記録部46とを備える。
(もっと読む)
対訳情報検索装置、翻訳装置及びプログラム
【課題】入力文の特性をより反映した目的言語構成情報を選択する対訳情報検索装置および翻訳装置を提供する。
【解決手段】対訳情報検索装置は、原言語で入力された文である入力文を取得する入力文取得手段と、原言語の文の構成を示す複数の原言語構成情報であってそれぞれが当該文の固定文字列を示す固定項目と可変の文字列を示す可変項目とを含む原言語構成情報のうちから、前記入力文に対応する原言語構成情報を選択する原言語構成情報選択手段と、前記選択された原言語構成情報に対応する目的言語の文の構成を示す複数の目的言語構成情報のうちから1つを、前記原言語構成情報と前記目的言語構成情報とに関連づけられる評価情報に基づいて選択する目的言語構成情報選択手段と、を含む。
(もっと読む)
トピック作成支援装置、トピック作成支援方法およびトピック作成支援プログラム
【課題】トピック作成の作業負担を軽減し、且つ、トピックの質を均質化すること。
【解決手段】トピック作成支援装置1は、ニュース記事情報記憶手段2から見出しを構成する見出し情報を抽出し、抽出された見出し情報を文節で区切って、複数の文節要素に分割する。そして、トピック作成支援装置1は、分割された各文節要素に対して、少なくとも品詞の特性或いは品詞の活用に応じて予め定められた重み付け判定データに基づいて、重み付けを行い、重み付けされた文節要素のうち、重み付けの度合いが大きい文節要素を抽出する。そして、トピック作成支援装置1は、抽出された文節要素の文字数が13文字以下である場合には、抽出された文節要素を文章情報のトピック候補としてディスプレイ3に出力する。
(もっと読む)
双対分解を用いた組み合わせモデル型アライナ
【課題】機械翻訳において用いる、並列翻訳文中の単語を対応付けるための方法、システムおよび装置。
【解決手段】トレーニング時間中に動作するコンポーネントを備え、コンポーネントは、一対の言語の、正しく翻訳された文対よりなる並列コーパス402を含む。他のトレーニング時間コンポーネントは、対応付けモデルコンポーネント404であり、並列コーパス402から文対を受信し、対応付けされた並列コーパスを生成する。該並列コーパスは、句抽出コンポーネント406により受信され、句抽出器は、翻訳された句および対応するスコアのスニペットを含む、句テーブル408を生成する。翻訳時間コンポーネントは、句テーブル408のデータから生成される翻訳モデル422を含み、言語モデル420、および、言語モデル420や翻訳モデル422を用い、入力テキスト426から翻訳済み出力テキスト428を生成する機械翻訳コンポーネント424を含む。
(もっと読む)
71 - 80 / 1,147
[ Back to top ]