
国際特許分類[G06F19/24]の内容
物理学 (1,541,580) | 計算;計数 (381,677) | 電気的デジタルデータ処理 (228,215) | 特定の用途に特に適合したデジタル計算またはデータ処理の装置または方法[6,8,2011.01] (2,326) | バイオインフォマティクス,すなわち計算分子生物学において遺伝子または蛋白質関連データの処理を行うための方法またはシステム (90) | 機械学習,データマイニングまたは生物統計学に関するもの,例.パターン検出,知識発見,ルール抽出,相関,クラスタリング,分類 (19)
国際特許分類[G06F19/24]に分類される特許
1 - 10 / 19
情報処理装置および情報処理システム
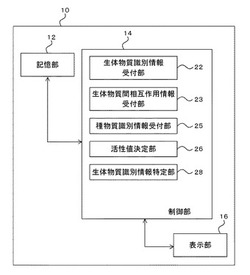
【課題】ある生体物質と相互作用を有する生体物質を抽出する情報処理装置および情報処理システムを提供する。
【解決手段】情報処理装置は、複数の生体物質の識別情報と、前記複数の生体物質間の相互作用の情報とを受け付ける手段と、前記複数の生体物質の識別情報のうち指定された1以上の種物質の識別情報を受け付ける手段と、前記種物質の識別情報および前記複数の生体物質間の相互作用の情報に基づいて活性伝搬処理を実行して、前記複数の生体物質の活性値を(時刻tにおける)決定する手段と、前記決定する手段により決定された前記複数の生体物質の活性値のうち閾値以上の活性値を有する生体物質の識別情報を特定する手段と、を含む。
(もっと読む)
生物学的特徴を検出するためのシステムおよび方法
【課題】生物学的特徴を検出するシステムおよび方法の提供。
【解決手段】メモリを有するコンピュータが、データを受け取るための命令を記憶し、このデータは、ある1つの種の試験生物内または種の生物の試験生体標本内で測定された複数の細胞成分のうちのそれぞれの細胞成分の1つまたは複数の特性を含む。このメモリは、複数のモデルのうちのある1つのモデルを演算するための命令を記憶しており、試験生物内または試験生体標本内の生物学的特徴の存在の有無を表すモデルスコアによって特性づけられる。このモデルの演算は、複数の細胞成分のうちの1つまたは複数の細胞成分の1つまたは複数の特性を使用してモデルスコアを決定することを含む。このメモリはさらに、演算するための命令を1回または数回繰り返すための命令を記憶しており、それによって複数のモデルが演算される。このメモリはさらに、演算されたモデルスコアを通信するための命令を記憶している。
(もっと読む)
皮膚関連遺伝子の検出方法、並びに該遺伝子を用いた肌情報の提供方法、化粧品の販売システム、化粧品の販売方法及び化粧品成分のスクリーニング方法
【課題】皮膚関連遺伝子を、被験者の遺伝子多型、年齢、性別及び肌の部位別の症状または各部位の症状の平均の相関関係を共分散構造分析により分析することにより検出する方法の提供。
【解決手段】被験者の遺伝子多型、年齢、性別及び肌の部位別の症状または各部位の症状の平均の相関関係を、相関係数rを下記式1により計算し、(式1)r=Σ(Xi−<X>)(Yi−<Y>)/sx/sy(式中、Xi、Yiは各々各サンプルの値を表し、<X>、<Y>は各々平均値を表し、sx、syは各々標準偏差を表す)、XとYに対するZの影響を下記式2の一次回帰式(式2)X=aZ+ex、Y=bZ+eyで捉え、exとeyの相関係数を求めることによりXとYの偏相関係数を計算して、共分散構造分析により分析する。
(もっと読む)
主成分算出方法、トランスクリプトーム解析方法、遺伝子、老化判定方法、コンピュータプログラム、記憶媒体、及び解析装置

【課題】多数の測定項目からなるデータに対応する、解析装置を用いた主成分算出方法を提供する。
【解決手段】
解析装置を用いてデータ行列から主成分を算出する主成分方法である。そして、解析装置は、主成分を、その主成分の算出に用いたサンプル数又は測定項目数の平方根で除することでスケーリングする。また、解析装置は、スケーリングした前記主成分から、所定の閾値で前記発現量が変化したサンプルを選択する。これにより、測定項目がある程度異なる、しかし測定項目が多いようなデータに対応することができる。
(もっと読む)
遺伝子のコドン情報に基づいて生物種を分類する方法およびシステム
【課題】 従来行われてきた遺伝子配列の相同性に基づく系統解析は、同じ種類の分子の進化速度が一定であるとの前提に基づいているので、同じ種類の遺伝子間での分析しかできないという欠点がある。
【解決手段】 本発明者は、各遺伝子におけるコドンに対応するアミノ酸の物性値とコドンの組成比を分析することで新たな遺伝子の進化的性質を見出した。
第一に、G+Tの対称性によるコドンに対応するアミノ酸の親水性疎水性指標値の期待値は、真正細菌、古細菌および真核生物の指標となる。
第二に、G+Cの対称性によるコドンの組成比の遺伝子集合における標準偏差は、高次機能を有する生物種の指標となる。
第三に、G+Aの対称性によるコドンに対応するアミノ酸の分子量の期待値は、極限環境で生育できる生物種の指標となる。
以上の知見に基づいて、遺伝子集合のコドン情報に基づいて生物種を分類する方法を完成させた。
(もっと読む)
発現データ予測システム
【課題】個々の実験の遺伝子パターンを分析し機能特異的な遺伝子を特定するのではなく、過去の発現実験データをもとに、化合物や疾患に代表される表現型等を予測する発現データ予測システムを提供する。
【解決手段】S11〜S14のステップが、参照データを作成するフローに相当する。一方、S1〜S4は、新しい実験の遺伝子発現データ(予測したい発現データ)を利用して実際に予測処理を行うフローに相当する。このように、化合物又は疾患に代表される表現型等の予測対象を予測するには、遺伝子発現の特徴又は遺伝子発現のパターンが類似しているかどうかを評価する基準となる参照データをあらかじめ作成しておく必要がある。これは、蓄積された既存の遺伝子発現データを用いて作成される。
(もっと読む)
遺伝子の配列情報に基づいて生物種を分類する方法およびシステム
【課題】 従来行われてきた遺伝子配列の相同性に基づく系統樹による解析は、同じ種類の分子の進化速度が一定であるとの前提に基づいているので、同じ種類の遺伝子間での分析しかできないという欠点がある。
【解決手段】 本発明者は、複数の生物種が有する遺伝子集合の塩基組成比を遺伝子別に分析することで、第一に、すべての生物の遺伝子のG+Tは、ほぼ0.5であるという普遍的な分子の性質を、第二に、遺伝子のG+Cは多様であり、高次機能を有する真核生物の遺伝子のG+Cの分布のばらつきは大きいという進化的性質を、第三に、極限環境で生育している古細菌の遺伝子は、ピリミジン残基(C+T)に比べて分子の大きさの大きいプリン残基(G+A)の比率が大きいという進化的性質をそれぞれ見出した。この知見に基づいて、任意の種類の遺伝子集合の配列情報に基づいて生物種を分類する新たな方法を完成させた。
(もっと読む)
帰納的アルゴリズムを使用することによる、DNA配列決定データにおける位相不一致エラーを補正するためのシステムおよび方法
Notice: Undefined index: from_cache in /mnt/www/gzt_ipc_list.php on line 285
ラベルフリー統合的薬理学を用いる分子薬理学的測定方法
Notice: Undefined index: from_cache in /mnt/www/gzt_ipc_list.php on line 285
クラスタリングを用いて生物学的持続状態の存在を検出するためのシステムおよび方法
生物学的実体の存在を決定するための方法。該方法は、デジタルコンピュータに、複数の試料と関連する、少なくとも、第1の遺伝子エレメント(例えば、mecA)と関連する複数の第1の入力値、第2の遺伝子エレメント(femA)と関連する複数の第2の入力値、および第3の遺伝子エレメント(例えば、orfX)と関連する複数の第3の入力値を入力するステップを包含しうる。各試料は、該複数の第1の入力値中の第1の入力値、該複数の第2の入力値中の第2の入力値、および該複数の第3の入力値中の第3の入力値を包含する。 (もっと読む)
1 - 10 / 19
[ Back to top ]