
国際特許分類[G06F7/00]の内容
物理学 (1,541,580) | 計算;計数 (381,677) | 電気的デジタルデータ処理 (228,215) | 取扱うデータの順序または内容を操作してデータを処理するための方法または装置 (915)
国際特許分類[G06F7/00]の下位に属する分類
デジタル値の比較 (26)
個々の記録担体上のデータを分類,選別,組合せ,または別々の記録担体上のデータを比較するための装置
連続的記録担体,例.テープ,ドラム,ディスク,上のデータを分類または組合せる装置 (51)
位取り記数法を用いて計算を行なうための方法または装置,例.2進,3進,10進法を用いるもの (331)
乱数または擬似乱数発生器 (209)
デジタルな非位取り記数法,すなわち.基数を用いない数表現を用いて計算を行うための方法または装置;位取り記数法と非位取り記数法の組合せを用いる計算装置 (35)
1語内の,指定値を有する1以上のビットの位置を選別または符号化すること,例.最上位または最下位の有意な0または1の検出,プライオリティ・エンコーダ (6)
データ内容から独立して定められたルールによるデータの再配置,並べ替え,または選別のための装置 (42)
国際特許分類[G06F7/00]に分類される特許
51 - 60 / 215
複数のコアを含むプロセッサを有するコンピュータ・システムの制御
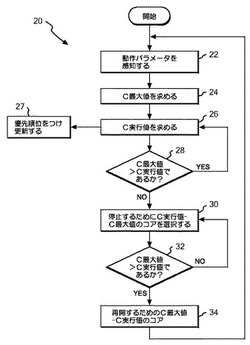
【課題】 複数のコアを含むプロセッサを有するコンピュータ・システムを制御する方法を提供すること。
【解決手段】 複数のコアを含む少なくとも1つのプロセッサを有するコンピュータ・システムの制御が、動作条件に基づいて、所定の期間に動作する複数のコアの最大数を設定するコア最大値を確立することと、所定の期間に動作する少なくとも1つのプロセッサの複数のコアの数と関連したコア実行値を求めることと、所定の期間においてコア実行値がコア最大値を上回る場合には、複数のコアの少なくとも1つを停止させることと、を含む。
(もっと読む)
プロセッサにおける効率的なパラレル浮動小数点例外処理

【課題】SIMD命令を実行するプロセッサにおいて浮動小数点例外を効率的に処理する。
【解決手段】SIMD命令を実行するプロセッサにおいて浮動小数点例外を処理する方法であって、前記SIMD演算の第1Packed部分結果を生成するため、第1SIMDマイクロ演算を開始するステップと、前記SIMD演算の第2Packed部分結果を生成するため、第2SIMDマイクロ演算を開始するステップと、前記第1及び第2Packed部分結果を合成し、前記合成された第1及び第2Packed部分結果の第1要素を非正規化して非正規化要素を有する第3Packed結果を生成するため、SIMD非正規化マイクロ演算を開始するステップと、前記SIMD演算の第3Packed結果を格納するステップと、前記第3Packed結果の非正規化要素を特定するフラグを前記第1Packed部分結果に設定するステップとを有する方法。
(もっと読む)
メモリ・論理共役システム
【課題】規模の増大をクロスバースイッチで対応するためバンド幅ネックになるという課題がある。
【解決手段】本発明に係るメモリ・論理共役システムは、メモリ回路を有する基本セル10をクラスタ状に配置した複数のクラスタメモリ20をそれぞれ含む複数のクラスタメモリチップと、複数のクラスタメモリを制御するためのコントローラチップと、を3次元的に積層したシステムであって、複数のクラスタメモリチップ及びコントローラチップの積層方向に沿って位置する複数のクラスタメモリ20が、貫通ビアを含んで構成されるマルチバス11を介してコントローラチップに電気的に接続されており、コントローラチップからマルチバス11を通して任意の基本セル10に直接アクセスして真理値データを書き込むことにより、任意の基本セル10を論理回路に切り替えることを特徴とする。
(もっと読む)
半導体装置、および、半導体装置によるデータ処理方法
【課題】パイプライン型に接続した複数のリコンフィギュラブル回路が、データを演算していない時間がより少なくなるように実行回路を構築できること。
【解決手段】コントローラ10と、後段に複数段直列に接続された演算ユニット12とを備えた半導体装置であって、コントローラ10は、データと再構成情報とを初段の演算ユニット12に入力し、演算ユニット12は、再構成情報により特定される回路情報による実行回路で構築され入力されたデータを演算する演算器120と、再構成情報を次の演算に必要な回路情報を特定するように更新する回路情報識別子更新部123と、演算器120による演算を繰り返すかを判断し、回数分の演算を完了したと判断した場合、データと再構成情報とを次段の演算ユニット12に入力し、完了していないと判断した場合、データと再構成情報とを再度自身に入力するように制御する繰り返し制御部126と、を備えた。
(もっと読む)
プログラマブル論理回路
【課題】 コンフィギュレーションに際して容易に上位機器と接続でき、一旦基盤に実装した後も再利用が可能なプログラマブル論理回路を提供すること。
【解決手段】 FPGA1に上位機器10,基盤30とUSB接続するUSBI/F1aを設ける。USBI/F1aにより上位機器10と接続されたとき、上位機器10にコンフィギュレーションデータを作成するためのソフトウェアを起動せしめる。このソフトウェアにより作成されたコンフィギュレーションデータが、USBI/F1aを介して受信されたことに応じて、当該コンフィギュレーションデータに基づく論理回路を論理回路部2のユーザ領域6に設計する。その後、USBI/F1aにより基盤30と接続されたとき、ユーザ領域6に設計した論理回路に基づいて入力信号を処理する。
(もっと読む)
再構成可能電子回路装置
【課題】回路構成情報を効率的に保持、転送する再構成可能電子回路装置を提供する。
【解決手段】複数のPE10と、複数のPE10のそれぞれに電子回路を実現させるための回路構成情報を複数記憶するDRAM50、複数のPE10のいずれかにロードされた回路構成情報をキャッシュする二次キャッシュ60、複数のPE10のそれぞれにロードすべき回路構成情報を選択し、選択された回路構成情報が二次キャッシュ60に記憶されていなければDRAM50から二次キャッシュ60に読み出し、選択された回路構成情報を二次キャッシュ60からPE10にロードするキャッシュ制御部70、を備える。
(もっと読む)
動的再構成回路およびデータ送信制御方法
【課題】コンテキストの切り換え内容に応じた最適なクラスタ間のデータ送信を実現する。
【解決手段】リコンフィグ回路100は、再構成可能なPE(プロセッシングエレメント)の集合からなるクラスタ110を複数備え、PEの処理内容とPE間の接続内容が記述されたコンテキストに応じて、クラスタ110の構成を動的に切り換え可能である。そして、各クラスタ110は、コンテキストの切り換え指示を受け付けると、当該切り換え指示をあらわす報知信号であるインヒビット信号を生成するインヒビット信号生成回路340と、クラスタ110から他のクラスタ110へ送信する出力データに生成された報知信号を付加するインヒビット信号付加回路350と、他のクラスタ110によって生成された報知信号が付加された出力データが送信されてきた場合に、この出力データのクリア処理をおこなう入力データクリア回路360とを備えている。
(もっと読む)
半導体集積回路
【課題】累積加算又は積和演算等を行う場合にビット精度を向上させ、無駄なリソースの発生を防止することができる半導体集積回路を提供することを課題とする。
【解決手段】第1のビット幅のデータを入力し演算を行う複数の再構成可能な第1の論理ブロック(111)と、前記複数の第1の論理ブロック間を動的再構成可能に接続する第1のネットワーク(112)と、前記第1のビット幅とは異なる第2のビット幅のデータを入力し演算を行う複数の第2の論理ブロック(121)と、前記複数の第2の論理ブロックの出力に接続される第2のネットワーク(122)と、前記第1の論理ブロックに含まれる演算器のキャリビット出力を、前記第2の論理ブロックに含まれる演算器の入力に動的再構成可能に接続する第3のネットワーク(120)とを有することを特徴とする半導体集積回路が提供される。
(もっと読む)
処理回路
【課題】 処理能力を維持したまま回路面積の削減化が図られた処理回路を提供する。
【解決手段】 128ビット幅のパラレル信号(平文)を入力し、分周器10からの低速のクロックCLK_Gに同期して128ビット幅全幅についてパラレルに処理を実行するレジスタ11,シフトロウズ演算器13,ミックスコラムズ演算器14,アドラウンドキー演算器15,レジスタ16と、128ビット幅をNに分割したときの128/Nビット幅単位で、クロックCLK_Gよりも高速のクロックCLK_Lに同期して処理を実行する共有型S―Boxを具備し、128ビット幅のパラレル信号を128/Nビット幅ずつに分けて上記共有型S―Boxに処理を複数回繰り返させるサブバイト演算器12とを備えた。
(もっと読む)
積和演算回路、その設計装置、プログラム
【課題】行列の積和演算の技術に関し、回路の利用効率および演算性能を向上させることが可能な積和演算回路を提供することにある。
【解決手段】乗算器102〜107は、行列Aの行を分割した部分行ベクトルと行列Bの列を分割した部分列ベクトルとの乗算を並列に実行し、加算器108〜112は乗算結果を加算し、部分積和演算結果を出力する。12個の部分積和演算結果は、レイテンシ=12の加算器116に順次溜め込まれた後、その出力側から入力側にフィードバックされながら、次のタイミングにおける新たな12個の部分積和演算結果に順次加算される。上記レイテンシに対応する12進カウンタ113と上記分割の数に対応する22進カウンタ114のカウント動作に従って、加算器116にて累算された積和演算結果が、12×22=264クロック毎に12個ずつ出力される。
(もっと読む)
51 - 60 / 215
[ Back to top ]