
国際特許分類[G06N3/00]の内容
物理学 (1,541,580) | 計算;計数 (381,677) | 特定の計算モデルに基づくコンピュータ・システム (1,616) | 生物学的モデルに基づくコンピュータ・システム (1,008)
国際特許分類[G06N3/00]の下位に属する分類
ニューラル・ネットワーク・モデルを用いるもの (314)
遺伝的モデルを用いるもの (19)
国際特許分類[G06N3/00]に分類される特許
1 - 10 / 675
情報処理方法、情報処理装置、および記憶媒体
Notice: Undefined index: from_cache in /mnt/www/gzt_ipc_list.php on line 285
意味ラベル付与モデル学習装置、意味ラベル付与装置、意味ラベル付与モデル学習方法、及びプログラム
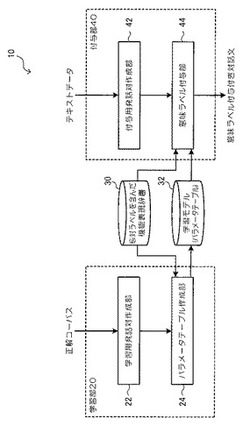
【課題】会話の流れによって疑問表現になったり、断定表現になったりする述部の機能表現に対しても、適切な意味ラベルを付与する。
【解決手段】学習用発話対作成部22で、形態素解析結果に対して、機能表現及び応対表現の正解ラベルが付与された正解コーパスに基づいて、学習用発話対を作成する。パラメータテーブルに、素性として、発話対の前の発話の終わりに表れる機能表現の意味ラベルと、それに対する後の発話の初めに表れる応対表現の意味ラベルとの並びの素性を用い、複数種類の素性各々について、重みの初期値を設定する。パラメータテーブル作成部24で、発話対の形態素情報と機能表現辞書30とを用いて、各形態素について候補となる意味ラベルを全て含んだラティスを構築し、ラティス構造からパラメータテーブルの素性毎の重みに基づいて最尤パスとして探索する。最尤パスが正解の意味ラベル列となるようにパラメータテーブルの重みを学習する。
(もっと読む)
学習装置、学習方法、プログラム

【課題】SVMによる識別器を学習させるための学習装置について、その学習時間を有効に短縮する。
【解決手段】学習データを分割した分割学習データをそれぞれ入力して初段の学習を行う複数のサポートベクターマシンを備える学習部と、前段の複数のサポートベクターマシンごとの学習結果として出力されるサポートベクター群を入力して所定数ごとに結合し、当該結合されたサポートベクター群を入力して次段における学習を行うサポートベクターマシンを構築する、2段目から最終段までの学習の各々に対応するSVM結合部と、前段の複数のサポートベクターマシンから出力されたサポートベクター群におけるサポートベクターを削減し、当該サポートベクターが削減されたサポートベクター群を次段のSVM結合部に対して出力するサポートベクター削減部とを備えて学習装置を構成する。
(もっと読む)
拡張重み更新型自己組織化マップを構築するためのプログラム、および構築した拡張重み更新型自己組織化マップを用いて特性値を推定するためのプログラム、ならびに拡張重み更新型自己組織化マップを用いる特性値の推定装置
【課題】より多くのデータを学習に用いて拡張重み更新型自己組織化マップを構築するためのプログラムを提供することを目的とする。
【解決手段】物質を測定して得られる特徴量が入力されると、該特徴量とは性質の異なる特性値を定量的に演算し出力するための拡張重み更新型自己組織化マップを構築するためのプログラムは、異なる条件で測定された特徴量の複数の測定値および特性値の複数の測定値の入力を受け付け(ステップS1)、測定値の分散を算出して分散が所定の閾値以上となる測定値を除外し(ステップS3)、さらに測定値のうち外れ値を除外し(ステップS4)、残った特徴量および特性値の測定値を統計解析により対応づけた学習用サンプルを作成し(ステップS5)、作成した学習用サンプルにより自己組織化マップに拡張重み更新学習をさせ、特徴量間の関係性を写像した競合層を有する拡張重み更新型自己組織化マップとして構築する(ステップS6)ことをコンピュータに実行させる。
(もっと読む)
消費電力推定装置、方法及びプログラム
【課題】ネットワークに接続されている装置の個々の消費電力を特殊な機器を用いずに推定する。
【解決手段】測定対象機器における電力量及び入出力パケットを受け付けるデータ受信部32と、データ受信部32に受け付けられた電力量と入出力パケットとを対応づけた学習モデルを生成するモデル演算部34と、モデル演算部34にて生成された学習モデルを保存するモデル保存部35とを有し、モデル演算部34は、データ受信部32にて入出力パケットのみが受け付けられた場合に、モデル保存部35に保存された学習モデルに基づいて、当該パケットを入出力した測定対象機器の電力量を推定する。
(もっと読む)
クラスタリング装置、方法、及びプログラム
【課題】時系列データが与えられたときに、クラスタ数を自動的に決定すると共に、時刻のクラスタリングに寄与する真の特徴量と、時刻のクラスリングに寄与しないノイズ特徴の影響を自動的に推定・分離して、時刻のクラスタリングを行うことができるようにする。
【解決手段】入力部1により観測値の時系列データの入力を受け付けて、クラスタ割り当て変数更新部23、特徴選択変数更新部24、特徴選択パラメータ更新部25、特徴観測パラメータ更新部26、ノイズ観測パラメータ更新部27、クラスタ遷移パラメータ更新部28、混合比パラメータ更新部29、及びハイパーパラメータ更新部210による更新を、解析終了条件を満たすまで繰り返す。
(もっと読む)
システムパラメータ最適化装置、方法、及びプログラム
【課題】高速かつ高精度に、システムパラメータの最適化を行うことができるようにする。
【解決手段】粒子更新部23によって、粒子の速度を正規化して更新し、更新された粒子の速度に基づいて、粒子の位置を正規化して更新する。システム処理部24に、粒子の現在の位置が示すシステムパラメータの値が設定され、予め用意された入力文に対して翻訳処理を行い、翻訳文を出力する。粒子更新部23は、出力された翻訳文に対して評価関数の値を計算する。粒子更新部23によって、計算された評価関数の値に基づいて、粒子の自己ベスト位置を更新する。全体ベスト更新部25によって、各粒子について更新された自己ベスト位置に基づいて、全体ベスト位置を更新する。収束判定部26によって、全体ベスト位置が収束したと判定したときに繰り返し処理を終了し、最適化された全体ベスト位置が示すシステムパラメータの値を出力する。
(もっと読む)
情報処理装置、情報処理方法、及びプログラム
【課題】報酬推定機を自動構築できるようにすること。
【解決手段】エージェントの状態を表す状態データと、当該状態においてエージェントがとった行動を表す行動データと、当該行動の結果としてエージェントが得た報酬を表す報酬値とを含む行動履歴データを学習データとして用い、入力された状態データ及び行動データから報酬値を推定する報酬推定機を機械学習により生成する報酬推定機生成部を備え、前記報酬推定機生成部は、複数の処理関数を組み合わせて複数の基底関数を生成し、前記行動履歴データに含まれる状態データ及び行動データを前記複数の基底関数に入力して特徴量ベクトルを算出し、前記特徴量ベクトルから前記行動履歴データに含まれる報酬値を推定する推定関数を回帰/判別学習により算出する。前記報酬推定機は、前記複数の基底関数と前記推定関数とにより構成される、情報処理装置が提供される。
(もっと読む)
誤分類検出装置、方法、及びプログラム
【課題】検出に利用する統計的分類器の学習に誤分類されたサンプルが与える悪影響を抑制して、カテゴリが複数ある一般的な分類問題で誤分類されたサンプルを検出することができるようにする。
【解決手段】確率モデル生成部22によって、各サンプルnのコンテンツxnとカテゴリynの同時確率モデルp(xn、yn)のパラメータ値Θを、一点除外交差検定法に基づく同時確率モデルp(xn、yn)の予測尤度を最大化させるように、サンプルnごとに設定した重みwnを用いて計算する。誤分類サンプル検出部24によって、確率モデル生成部22によって計算された同時確率モデルp(xn、yn)のパラメータ値Θに基づいて、各サンプルnについてコンテンツxnが分類されているカテゴリynの予測クラス事後確率P(yn|xn)を計算し、各サンプルnの予測クラス事後確率P(yn|xn)に基づいて、誤分類サンプルを検出する。
(もっと読む)
分散計算機システム及び分散計算機システムの制御方法
【課題】計算機クラスタを増やすことなく、機械学習を低コストで実現する。
【解決手段】第2の計算機が複数の第1の計算機に学習のメタパラメータと素性インデックスの組を送信してMap処理部を割り当て、学習処理を行うストレージのデータを割り当てて第1のワーカーとして学習処理を実行させ、少なくとも1つの第1の計算機にMap処理部の出力を受信してモデルパラメータを更新するReduce処理部を割り当てて第2のワーカーとして学習処理を実行させ、第1のワーカーは特徴量を読み込む度に複数モデル管理部のメタパラメータと素性インデックスに対して素性選択とMap関数を実行して中間結果を算出して第2のワーカーに送信し、第2のワーカーはReduce関数を実行して中間結果から学習結果を生成し、第2の計算機は生成された学習結果が所定の基準を満たすまで第2のワーカーへ学習結果を送信して学習処理を繰り返す。
(もっと読む)
1 - 10 / 675
[ Back to top ]