
国際特許分類[G10L11/00]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 15/00〜21/00のグループ中のどれか一つに限定されない音声または音響の特徴量の測定または検出 (1,940)
国際特許分類[G10L11/00]の下位に属する分類
音声信号の有無の検出 (242)
音声信号のピッチの抽出 (206)
音声信号の有声音と無声音の部分の弁別 (36)
国際特許分類[G10L11/00]に分類される特許
41 - 50 / 1,456
音響信号における特徴抽出方法及び当該特徴を用いた音響信号の処理方法
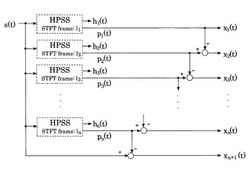
【課題】調波打楽器音分離に用いられるHPSS分析を多重的に用いることで音響信号の特徴を取得する。
【解決手段】
音響信号をn種の異なるフレーム長を用いて時間周波数領域へ変換することで得られたn個の音響信号のスペクトログラムを用意するステップと、各スペクトログラム上でHPSS分析を適用することでn個のH成分分離信号セットあるいはn個のP成分分離信号セットを取得するステップと、前記取得した分離信号セットにおける分離信号間の差分信号を当該音響信号の特徴として取得するステップと、を備えている。
(もっと読む)
音処理装置および音処理方法

【課題】日常音のモデルの自動的な更新を可能とする。
【解決手段】日常音を特性に基づきクラスタに分類し、クラスタに基づき異常音の判定を行う。クラスタをガウス分布の表現に変換したガウス分布を決定するパラメータを、新たに採取した採取音の特性を用いて更新する。更新の際に、採取音の特性がガウス分布に含まれる確率が、パラメータに決定されるガウス分布に含まれる確率を示す値で表される学習閾値の範囲内にある場合に、パラメータの更新を行う。また、採取音の特性がガウス分布に含まれる確率が、学習閾値よりも低い確率を表す異常音検出閾値未満である場合に、採取音が異常音であると判定する。
(もっと読む)
音響信号の符号化方法および装置
【課題】 ヒトの聴覚特性を利用することにより、子音成分を限定された数の周波数で再生される音源を用いて忠実に再現することが可能な音響信号の符号化方法および装置を提供する。
【解決手段】 時系列のサンプル列により構成されるデジタル音響信号に対して、単位区間ごとに解析を行って複数の周波数に対するスペクトル強度を得た後、周波数を帯域別に複数のグループに分割し、帯域ごとに、下限音高から上限音高の範囲内で強度が最大となる周波数を探索し(S22)、強度が最大となる周波数以外の周波数についての強度を減衰する(S23)。各帯域ごとに最大強度以外を減衰した結果を用いて符号化を行う。
(もっと読む)
ノイズ検出装置、ノイズ低減装置及びノイズ検出方法
【課題】
時間的な定常性が高い定常ノイズ成分を、精度良く検出する。
【解決手段】
時間周波数変換部121が、入力信号INDに対して、フレーム期間ごとに時間周波数変換を施して、変換結果を、振幅スペクトル情報FQDとして、パワースペクトル算出部122へ送る。また、時間周波数変換部121は、最新フレーム期間における入力信号INDの各周波数成分の位相情報PHDを算出する。そして、パワースペクトル算出部122が、振幅スペクトル情報FQDに基づいて、パワースペクトル分布PSDを算出する。引き続き、推定部124が、周波数毎に、記憶部123に記憶された最近の所定期間で得られたパワースペクトル分布において最小値であったパワースペクトルを抽出し、抽出されたパワースペクトルに基づいて、定常ノイズ成分のパワースペクトル分布NSDを推定する。
(もっと読む)
ノイズレベル検出装置、受信装置及びノイズレベル検出方法
【課題】
信号成分の周波数帯のノイズ成分のレベルを精度良く検出する。
【解決手段】
帯域内ノイズ成分のパワースペクトルに関する予測周波数分布における値が未知なパラメータの値を、フレーム期間における検波信号DTDの音声信号帯域内のパワースペクトル分布と当該予測周波数分布とが高い一致性を有するように選ぶことができるか否かを、評価部142Aが判定する。これにより、評価部142Aは、当該フレーム期間における検波信号DTDに音声信号成分が含まれていないと判断できるか否かを評価する。この評価の結果が肯定的であった場合には、ノイズレベル算出部145が、パワースペクトル分布における各周波数のパワースペクトルの総和を算出することにより、帯域内ノイズ成分のパワーレベルを算出する。
(もっと読む)
歌唱評価装置
【課題】歌唱の対象となる曲に対して予め決められた基準から乖離している度合いである乖離度に応じて前記歌唱者の歌唱を評価するときの、当該乖離度を表すパラメータを変更可能にすることを目的とする。
【解決手段】評価基準が選択されると(ステップS104;Yes)、制御部10は、選択された評価基準に相当するパラメータデータをRAMに読み込む(ステップS108)。一方、ステップS104でNoの場合、制御部10は、パラメータデータ記憶領域25から、検索キーに設定された曲番号と紐付く曲別パラメータデータを評価基準として検索し、検索結果のパラメータデータをRAMに読み込む(ステップS108)。楽曲の再生が終了すると、制御部10は、ユーザ歌唱音声データ記憶領域24に記憶されたユーザ歌唱音声データとRAMに記憶されたパラメータデータとに基づいて、歌唱の採点を行う(ステップS114)。
(もっと読む)
歌唱音声評価装置
【課題】歌唱音声の評価において、歌唱すべき構成音の音高に応じた歌唱難易度を反映すること。
【解決手段】本発明の実施形態におけるカラオケ装置は、楽曲データにより指定される歌唱すべき構成音に対応する歌唱難易度を、楽曲の音階の種類に対応する音高と構成音の指定音高との関係に基づいて設定する。カラオケ装置は、楽曲データの再生中に入力された歌唱音声を取得し、歌唱すべき構成音の評価値を、歌唱音声の歌唱音高、構成音の指定音高、設定された歌唱難易度に基づいて算出する。
(もっと読む)
楽曲再生制御装置、楽曲再生制御方法およびコンピュータプログラム
【課題】複数の楽曲を切れ目なく連続再生させる際に、楽曲が不自然に切り替わることを防ぐ。
【解決手段】楽曲に分割点を設定し、再生区間に分割する楽曲分割部と、再生区間の音楽特徴量を算出する音楽特徴量算出部と、再生楽曲について、いずれかの分割点を楽曲切替ポイントとして設定し、所定数連続する再生区間を類似基準区間として設定する再生楽曲処理部と、他の楽曲について、連続する所定数の再生区間を評価対象区間として順次設定し、類似基準区間と対応する順番の再生区間同士を順次対比させることで類似度を算出し、最も類似度の高い評価対象区間を抽出し、その評価対象区間を含む楽曲を次楽曲として設定する評価楽曲処理部と、再生楽曲を楽曲切替ポイントまで再生したら、次楽曲の最も類似度の高い評価対象区間から再生を開始させる再生制御部と、を備えた楽曲再生制御装置。
(もっと読む)
口唇動作パラメータ生成装置及びコンピュータプログラム
【課題】実音声に基づいて、アバターの口唇を見る人に違和感なく動かせる口唇動作パラメータの生成装置を提供する。
【解決手段】生成装置は、発話者の音声から得られる音声信号をフレーム化し、各フレームから第1フォルマントF1及び第2フォルマントF1を抽出するフォルマント抽出部80と、F1及びF2について、話者による母音空間の相違を補償するようにフォルマント空間の原点を移動させる原点移動処理部84と、F1及びF2の線形写像により、F1を補正するよう、フォルマント空間を原点周りに回転させる回転処理部86と、各フレームに対し、回転処理部86が出力する補正後の第1フォルマントの値の関数として、発話者の音声と同期して口唇形状を上下方向に変化させるためのパラメータを生成して出力する形状推定部88を含む。
(もっと読む)
コンテンツ分類装置、コンテンツ分類方法およびコンテンツ分類プログラム
【課題】多数のコンテンツを、指標化された特徴量に基づいて複数のグループに分類する際に、グループ間のコンテンツ数の偏りを小さくする。
【解決手段】複数のコンテンツを所定数のグループへとグループ分けするコンテンツ分類装置において、分類対象のコンテンツそれぞれにおける指標化された特徴量を取得し、複数のコンテンツが所定数のグループよりも多い数のグループにグループ分けされている状態から、グループに属するコンテンツの特徴量に基づいて各グループの特徴量の代表値を算出し、その代表値が近いグループ同士を1のグループへと結合する結合処理を行なうグループ作成部を備え、グループ作成部は、結合処理を、グループ数が所定数となるまで繰り返す。
(もっと読む)
41 - 50 / 1,456
[ Back to top ]