
国際特許分類[G10L13/00]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 音声の合成;テキストを音声に変換するシステム (2,199)
国際特許分類[G10L13/00]の下位に属する分類
合成音作成の方法;音声合成器 (464)
音声合成器で使われる音声素片;結合規則 (315)
テキストから音声を合成するための,テキストの分析,またはパラメータの生成,例.表記素から音素への変換,韻律の生成または強勢またはイントネーションの決定 (495)
国際特許分類[G10L13/00]に分類される特許
101 - 110 / 925
記録再生装置
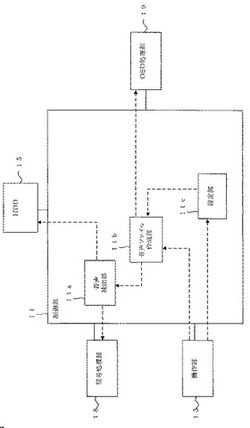
【課題】所定の楽曲を録画データから抽出して音声ファイルを作成する処理を、抽出の開始点/終了点の手動指定を必要とすることなく実施できる記録再生装置を提供する。
【解決手段】本発明の記録再生装置は、音声情報を含む再生情報の再生を行う再生処理部と、再生情報に含まれる音声情報の一部を抽出した部分音声情報を生成する音声抽出部とを備えている。また、音声抽出部を制御する抽出制御部を備えている。抽出制御部は、再生情報の再生時間軸の中から任意の再生位置の指定を受け付ける。そして指定された再生位置から所定範囲の再生時間内において、再生音量が閾値を越える再生位置を始点位置とする。さらに、始点位置の後方において所定の再生音声が検出された再生位置を終点位置とする。そして始点位置と終点位置とに挟まれた範囲の音声情報を抽出するよう、音声抽出部を制御する。これにより、部分音声情報を生成する。
(もっと読む)
文書校正支援装置

【課題】従来技術では、校正前文書を合成音声で読み上げながら、校正すべき箇所を記憶することはできない。
【解決手段】作成した文書を合成音声で読み上げさせ、読み上げ音声の抑揚やアクセントが文書の前後関係から違和感のある場合に、所定の操作を行なうことで、校正すべき箇所を記憶し、表示する文書校正支援装置により、解決できる。
(もっと読む)
情報提供装置および情報提供方法
【課題】現在提供中の音声情報の中断方法を工夫することで、優先情報をわかりやすく、かつ効果的に提供できる情報提供装置および情報提供方法を提供する。
【解決手段】品詞単位の音声情報Wを所定の順序で並べることで文章単位の音声情報セットSを作成する。複数の品詞単位の音声情報Wに当該音声情報Wを再生した後に優先割込情報Y1の再生が開始できる“再生後割り込み可能”の属性または当該音声情報を再生した後でも優先割込情報Y1の再生が開始できない“再生後割り込み不可能”の属性を設定する。現在再生中の音声情報セットSより優先度の高い優先割込情報Y1が入力された際に、その時点で再生中の音声情報が“再生後割り込み可能”であれば、当該音声情報を再生した後で優先割込情報Y1を再生し、一方、“再生後割り込み不可能”であれば、次に再生される予定の“再生後割り込み可能”な音声情報の再生が完了した後に優先割込情報Y1を再生する。
(もっと読む)
読み決定装置、読み決定方法、読み決定プログラム、音声合成装置、音声合成方法、及び、音声合成プログラム
【課題】テキストを表す読みとして決定された読みが不適切な読みを含むことを回避しながら、テキストを表す読みとして自然な読みを決定することが可能な読み生成装置を提供すること。
【解決手段】読み決定装置900は、テキストを表す形態素列の候補である形態素列候補のそれぞれが有する読みを受け付けるとともに、当該受け付けられた読みのうちの、予め定められた不適切な読みである禁止読みを含む読み以外の読みの中から、当該テキストを表す読みを決定する読み決定部901を備える。
(もっと読む)
音声素片データベース作成装置、代替音声モデル作成装置、音声合成装置、音声素片データベース作成方法、代替音声モデル作成方法、プログラム
【課題】音声波形データベースから全ての音声モデルを生成できなかった場合にも、代替音声モデルを生成することにより完全な音声素片データベースを生成することができる。
【解決手段】音声波形データを入力としダイフォン区間とダイフォンラベルを出力する音素−ダイフォン区間変換部1200と、音声波形データを入力とし音声パラメータ系列を出力する音声パラメータ系列変換部1300と、音声パラメータ系列を入力とし音声モデルを出力する音声モデル生成部1400と、ダイフォンラベルと定義済ダイフォンラベルリスト1500とを入力とし欠落ダイフォンラベルを出力する欠落ダイフォンラベル出力部1600と、音声モデルとダイフォンラベルとを入力としハーフフォンを出力するハーフフォン生成部1800と、ハーフフォンと欠落ダイフォンラベルとを入力とし、代替音声モデルを出力する代替音声モデル生成部1900とを備える。
(もっと読む)
音声読上装置
【課題】文章読み上げ時に、知りたい情報に直ぐにアクセスすることができ、また同じ情報を繰り返し聞きたい場合には始めから聞き返す必要がなく、さらに今読み上げている箇所が全体のどのあたりであるか容易に把握することができる音声読上装置を提供する。
【解決手段】制御部105は、テキストデータTDの文字数をカウントし、予め設定された文字数で段落を区切り、各段落の先頭位置をインデックスとして記憶部106に記憶するとともに、各インデックスに規則性を持った音データ(ドレミ音等の順序を想起させるような音データ)MDを割り当てて記憶部106に記憶し、ユーザによる入力操作によりテキストデータTDの各段落の任意のインデックスが指定されたときに、該当するインデックスに対応した音データMDを再生するようにした。
(もっと読む)
情報提示システム
【課題】携帯端末の機能に従って表示される情報に相当する情報を、車両を運転中のドライバがより容易に確認することを可能にする。
【解決手段】車載ナビゲーション装置の車載側BT通信部44が、携帯電話機からBT通信によって音声認識結果を受信し、車載側BT通信部44で受信した音声認識結果をもとに、車載側制御部45が当該音声認識結果についてのトークバック音声を車載側音声出力部42から出力させる。
(もっと読む)
音声編集装置
【課題】収録音声の不具合箇所を検出し、不具合箇所を合成音声により修正することにより、再度音声を収録する必要のない音声編集装置を提供する。
【解決手段】音声編集装置100は、編集情報生成部200と音声合成部300と音声編集部400とから構成される。編集情報生成部200は、収録音声700の不具合箇所を検出し、不具合箇所の修正に用いる合成音声を生成するのに必要な音声合成情報500と、不具合箇所の位置情報を含む収録音声変更情報600とを生成する。音声合成部300は、音声合成情報500に基づいて合成音声を生成する。音声編集部400は、収録音声変更情報600に基づいて、収録音声700の不具合箇所を上記合成音声により修正する。
(もっと読む)
音声エミュレーション機能を備えた電子書籍
【課題】様々なテキストから音声機能及び音声認識機能を有する、電子書籍を表示するためのビューアを提供することである。
【解決手段】このビューアは、ユーザが、表示された電子書籍においてテキストを選択し、対応する音声に変換することを可能にする。更に、ユーザは、表示された電子書籍の全体又は該電子書籍の特定のページに対するテキストから音声への変換をビューアに自動的に実行させることができる。また、このビューアは、ユーザが音声コマンドを入力することを可能にする。
(もっと読む)
直感型仮想対話方法
【課題】電子装置を用いて行われ、電子装置を介して使用者が対話しやすくなる直感型仮想対話方法を提供する。
【解決手段】電子装置を用いて行われる直感型仮想対話方法であって、対話者に対応する対話者情報に基づいて生成される対話者画像を少なくとも一つ有する複数の画像を含む仮想環境画面を表示するステップと、前記対話者から送信された音声信号に基づいて生成される対話音声信号を出力するステップと、を含み、前記複数の画像は、慣用形態で前記仮想環境画面に配置され、前記仮想環境画面において互いに関連性を有することを示している直感型仮想対話方法。
(もっと読む)
101 - 110 / 925
[ Back to top ]