
国際特許分類[G10L13/06]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 音声の合成;テキストを音声に変換するシステム (2,199) | 音声合成器で使われる音声素片;結合規則 (315)
国際特許分類[G10L13/06]に分類される特許
1 - 10 / 315
音声合成装置および音声合成プログラム
Notice: Undefined index: from_cache in /mnt/www/gzt_ipc_list.php on line 285
目標話者学習方法、その装置及びプログラム
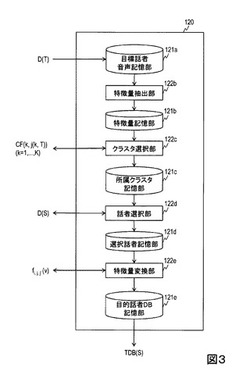
【課題】目的話者の合成音声の自然性劣化を抑制する。
【解決手段】事前に得られた複数話者の音声データの特徴量が特徴ごとに独立にクラスタリングされることで、特徴ごとに複数個のクラスタが設定される。目標話者の音声データの特徴量の組み合わせが属するクラスタの組み合わせが選択され、それに対応する音声データが複数話者の音声データから選択される。目標話者の音声データの特徴量の組み合わせが属するクラスタの組み合わせと、選択された音声データの特徴量の組み合わせがクラスタの組み合わせとが異なる場合に、選択された音声データの特徴量の一部の特徴量を変換する。
(もっと読む)
合成辞書作成装置および合成辞書作成方法

【課題】音声合成辞書の作成効率を向上させる合成辞書作成装置を提供することである。
【解決手段】実施形態の合成辞書作成装置は、提示手段と録音手段と要否判別手段と辞書作成手段と音声合成手段とを備える。提示手段は、文記憶手段に記憶されたN個(Nは自然数、N≧2)の文から順次選択された第1の文をユーザに提示する。録音手段は、前記第1の文を読上げたユーザの音声を録音し、この録音波形を前記第1の文と対応付けて記憶する。要否判別手段は、前記録音手段においてM個(Mは自然数、1≦M<N)の前記第1の文の録音波形が記憶された状態において、音声合成辞書の作成要否を判別する。辞書作成手段は、音声合成辞書の作成が必要と判別された場合、音声合成辞書を作成する。音声合成手段は、前記辞書作成手段で作成された音声合成辞書を用いて、第2の文を合成波形に変換する。
(もっと読む)
音声合成装置、音声合成方法および音声合成プログラム
【課題】計算処理性能が限られた環境でも、十分な音声合成処理や混合励振を可能にする音声合成装置、音声合成方法および音声合成プログラムを提供する。
【解決手段】入力された時系列の音源制御情報およびスペクトル特性情報を基に、音声波形を合成する音声合成装置100であって、音源波形を複数の周波数帯域に分割して蓄積されたサブバンド分割音源波形ベクトルに基づいて、入力された音源制御情報に対応するサブバンド分割音源波形ベクトルを生成するサブバンド分割音源生成部120と、生成されたサブバンド分割音源波形ベクトルに対して、入力されたスペクトル特性情報に応じたサブバンド毎の振幅調整を行なうサブバンドパワー調整部130と、振幅調整がなされたサブバンド分割音源波形ベクトルを単一の音声波形に合成するサブバンド合成部140とを備える。
(もっと読む)
音声合成用の隠れマルコフモデル学習装置及び音声合成装置
【課題】HMMを用いる音声合成装置であって,合成音声波形にひずみが生じることを抑えることが可能な音声合成装置,及びそのためのHMM学習装置を提供する。
【解決手段】学習装置110は,音声データベース60と,音声の各フレームから基本周波数(F0)を抽出するF0抽出処理部62と,各フレームからMFCCを算出するMFCC算出部64,MFCCの算出のための時間領域のサンプリングと双対をなす,周波数領域のサンプリングを行なうことにより,各フレームについてMFCCを所定の角度量に変換するMFCC変換部120と,各フレームについて求められたF0とMFCCとを学習用データ122としてHMMの学習とHMMのいずれかを選択するための決定木の学習とを行なうHMM学習部124とを含む。
(もっと読む)
音声処置装置、音声合成装置、音声特徴量の生産方法、およびプログラム
【課題】従来、音声合成において、高い品質の出力音声が得られる特徴量を取得できなかった。
【解決手段】音声を格納し得る音声格納部と、1以上の特徴量を格納し得る特徴量格納部と、前記音声格納部に格納されている音声のスペクトルまたはスペクトル包絡を取得するスペクトル取得部と、前記スペクトル取得部が取得したスペクトルまたはスペクトル包絡に対して、予め決められた閾値以上の周波数のスペクトルを切り詰める処理を行う切詰処理部と、前記切り詰める処理を行ったスペクトルまたはスペクトル包絡から1以上の特徴量を取得する特徴量取得部と、前記特徴量取得部が取得した1以上の特徴量を前記特徴量格納部に蓄積する特徴量蓄積部とを具備する音声処置装置により、音声合成において、高い品質の出力音声が得られる特徴量を取得できる。
(もっと読む)
音声合成装置
【課題】フレームを反復する場合でも聴感的に自然な合成音を生成する。
【解決手段】記憶装置14は、相異なる音素に対応する音素区間S1と音素区間S2とを含む音声素片Vの素片データDを音声素片V毎に記憶する。限界設定部42は、音声素片Vの音素区間S2のうち音素区間S1の音素から当該音素区間S2の音素に遷移する遷移区間EA内で当該音声素片Vの音素区間S1の音素の種別Cに応じた時点を限界時点TAとして設定する。境界設定部44は、音素区間S2のうち限界時点TAの後方に位置する可変の時点を境界時点TBとして設定する。合成処理部46は、音声素片Vを区分した複数のフレームのうち境界時点TBに対応するフレームの単位データUを反復した単位データ群Z2を、音声素片Vのうち境界時点TBの前方のフレームの各単位データUの単位データ群Z1に後続させて音声信号VOUTを生成する。
(もっと読む)
音声合成用音声データベース構築のための通信システム、中継装置および中継方法
【課題】個人の音声の特徴を再現する本人性を重視した音声合成用音声データベースを容易に構築のための通信システム、中継装置および中継方法を提供すること。
【解決手段】中継装置20は、通話中の通信端末間で送受信される音声データを複製する。複製された音声データは、メディア処理装置40に送信され蓄積される。メディア処理装置40は、蓄積された音声データを基に音声合成用データベースを構築する。
(もっと読む)
音声合成装置
【課題】音声素片の記憶に必要な記憶容量を削減する。
【解決手段】記憶装置14は、音声素片の各フレームの振幅スペクトルSMを示す音声素片データDを記憶する。位相算定部32は、音声素片データDが示す振幅スペクトルSMに対応する最小位相を音声素片の位相スペクトルSPとしてフレーム毎に算定する。音声合成部34は、音声素片データDが示す各フレームの振幅スペクトルSMと位相算定部32による算定後の各フレームの位相スペクトルSPとを利用して音声信号VOUTを生成する。
(もっと読む)
音声合成装置
【課題】既存の素片データとはピッチが相違する合成音を自然な音色で生成する。
【解決手段】記憶装置14は、音声素片の素片データVをピッチP毎に記憶する。素片データVは、有声音を含む区間内の各フレームについてスペクトル形状の特徴を示す形状パラメータRを含み、無声音を含む区間内の各フレームについてスペクトルデータQを含む。素片補間部24は、素片データV1およびV2の補間で目標ピッチPtの素片データVを生成する。具体的には、素片データV1およびV2の双方が有声音を示すフレームについては形状パラメータRが目標ピッチPtに応じた補間比率αで補間され、素片データV1およびV2の片方または双方が無声音を示すフレームについては、音量Eが補間比率αで補間され、素片データV1のスペクトルデータQが補間後の音量Eに応じて補正される。音声合成部26は、補間後の素片データVを利用して音声信号VOUTを生成する。
(もっと読む)
1 - 10 / 315
[ Back to top ]