
国際特許分類[G10L15/08]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 音声認識 (6,879) | 音声の識別または探索 (1,500)
国際特許分類[G10L15/08]の下位に属する分類
未知音声と標準パタンとの距離または歪みを用いるもの (838)
動的計画法を用いるもの,例.動的時間伸縮[DTW] (22)
統計的モデルを用いるもの,例.隠れマルコフモデル[HMM] (175)
ニューラル・ネットワークを用いるもの (24)
自然言語モデルを用いるもの (322)
国際特許分類[G10L15/08]に分類される特許
1 - 10 / 119
音声認識方法とその装置とプログラム
【課題】認識対象の音声品質を事前推定して音声品質の変動に対する認識処理時間の増減の影響を少なくした音声認識方法を提供する。
【解決手段】スコアレンジ計算部は、音声特徴量系列を入力として当該音声特徴量系列に対するモノフォン最尤スコアと最もスコアの低いモノフォン最低スコアを求め、その差分をフレーム毎の音響スコアレンジとして計算し、当該音響スコアレンジを時間方向に平均した音響スコアレンジRを出力する。そして、認識処理制御部は、外部から入力されるスコアレンジ基準R0と音響スコアレンジRを入力として、音響スコアレンジRをスコアレンジ基準R0で除した値に基づくスコアビーム変動係数kを計算して出力する。音声認識処理部は、音声特徴量系列とスコアビーム変動係数kを入力として、スコアビーム変動係数kの値に応じて探索ビーム幅を可変して音声認識処理を行う。
(もっと読む)
音声認識装置、自動応答方法及び、自動応答プログラム

【課題】音声認識での応答を行う際に、正解の厳密度を調整することが可能な音声認識装置、自動応答方法及び、自動応答プログラムを提供する。
【解決手段】ユーザから音声入力された音声データをテキスト化する音声端末10であって、ユーザの応答を正解とするか否かの判断基準となる厳密度と、ユーザの応答である応答データに対して、厳密度毎に異なる一以上の回答データを、当該厳密度に対応付けて記憶しておく。そして、質問を出力し、ユーザからの音声による応答データを受付け、応答データと予め記憶された回答データとをテキスト文字で比較し、応答データが正解か否かを判断して結果データを出力する際に、厳密度に基づいて結果データを出力する。
(もっと読む)
音声認識装置、音声認識方法、及び音声認識プログラム
【課題】音声認識精度を向上させる。
【解決手段】本発明に係る音声認識装置100は、音データに含まれる単語を抽出し、各単語の信頼度を算出する音声処理部130と、各単語に対応する音データの発話者の音声らしさを示す各単語の発話者度を算出する発話者度算出部140と、音声処理部130により算出された各単語の信頼度、及び発話者度算出部140により算出された各単語の発話者度に基づいて、各単語のスコアを算出するスコア算出部150と、所定の閾値を設定する閾値設定部160と、各単語のスコアと所定の閾値とに基づいて、音声認識結果として採用する単語を選定する単語選定部170とを備える。
(もっと読む)
音声認識装置、音声認識方法及びプログラム
【課題】設定された音声認識率と実際の音声認識率との間で大きな誤差が生じないようにする。
【解決手段】音声認識装置10は、複数の単語それぞれの特徴量を記録した記憶部12と、外部から入力された音声の特徴量と記憶部12に記録された複数の単語の特徴量とから各単語の類似度を算出し、算出した各単語の類似度から類似度の最大値を取得する類似度最大値取得部11bと、類似度最大値取得部11bが取得した類似度の最大値と所定値とを用いて類似度の範囲を決定する類似度範囲決定部11cと、類似度範囲決定部11cが決定した類似度の範囲に含まれる類似度を有する単語を選択し、選択した単語を認識結果として表示部15に表示する制御を行う表示制御部11dとを備える。
(もっと読む)
対話装置
【課題】音声認識の認識結果を早期確定して逐次認識結果を出力することができるとともに、早期確定するフレームの間隔を短くした場合であっても、認識率の低下を抑制することができる対話装置を提供する。
【解決手段】対話装置1は、音声認識の認識区間を設定する認識区間設定手段20と、音声認識を行う音声認識手段30と、音声認識の認識結果の中に所定のキーフレーズが含まれる場合、これに対応した応答行動を決定する応答行動決定手段40と、決定された応答行動を実行する応答行動実行手段50と、を備え、認識区間設定手段20が、既に設定された認識区間の認識終了位置を、当該認識終了位置から所定の時間長だけ進んだ位置のフレームに繰り返し更新することで複数の認識区間を設定し、音声認識手段30が、認識終了位置の異なる複数の認識区間のそれぞれについて音声認識を行う。
(もっと読む)
音認識装置および音認識方法
【課題】観測音が認識対象とする音であるか否かの判定を漏れなく行う。
【解決手段】HMMを用いて、観測音から抽出した特徴量の、目的音に基づく第1の認識モデルおよび非目的音に基づく第2の認識モデルに対する尤度と、観測音が目的音および非目的音のうち何れであるかを示す認識結果とを認識部で求め、認識結果が示す認識モデルに対応する尤度を用いて信頼度算出部で認識結果の信頼度を算出する。認識結果と信頼度とを用いて、認識結果の正解率を、観測音が目的音と仮定した場合と、観測音が非目的音と仮定した場合とについて正解率算出部で算出する。警報出力処理部は、認識結果と正解率と基づき、認識結果が目的音を示し、正解率が第1の閾値以下の場合と、認識結果が非目的音を示し、正解率が第2の閾値以下の場合とにおいて、観測音が目的音と非目的音の何れにも属さない未知音であることを示す情報を出力する。
(もっと読む)
音声認識用WFST作成装置とそれを用いた音声認識装置と、それらの方法とプログラムと記憶媒体
【課題】状態数、状態遷移数を削減したサイズの小さな音声認識用WFSTを作成する音声認識用WFST作成装置と、その音声認識用WFSTを用いた音声認識装置を提供する。
【解決手段】音素モデル構造表作成部は、音響モデルの要素である音素環境と状態位置と状態数で特定されるHMM状態にHMM状態IDを付与し、そのHMM状態IDの表を音素モデル構造表として作成して音素モデル構造表記憶部に記憶する。構造合致照合部は、複数の音響モデル間において同一の音素環境と状態位置と状態数である複数の状HMM態IDを併合させて新たに併合したHMM状態IDを付与し、そのHMM状態IDと対応する音素環境と状態位置と状態数とから成る表になるように音素モデル構造表を更新する。音響モデルWFST作成部は、その併合されたHMM状態IDを入力とし、出力を音素環境とする併合音響モデルWFSTを作成する。
(もっと読む)
音声認識装置、音声認識方法及び音声認識プログラム
【課題】計算コストや計算の際に使用するメモリ量の増加を抑えつつ、ロバスト性の高い音声認識を行うことが可能な音声認識技術を提供する。
【解決手段】音声認識装置は、同一の構造を有する複数の音響モデルと、複数の音響モデルに共通の探索ネットワークとを記憶し、音声の入力を受け付け、当該音声を用いて、音響特徴量を抽出し、抽出した音響特徴量と、複数の音響モデルと、探索ネットワークとを用いて、探索ネットワーク上で始端ノードから終端ノードに至るまでに経由するノードの系列を示す各経路に対して、複数の音響モデルのそれぞれに対応してスコアを計算し、各経路のうちスコアが最大である第1経路を選択することにより、探索ネットワーク上で始端ノードから終端ノードに至る最適な経路である第1経路を探索し、音声の認識結果である第1経路を示す情報を出力する。
(もっと読む)
音声認識方法、音声認識装置及び音声認識プログラム
【課題】音声認識処理を行うこと無く短い処理時間で信頼度スコアを計算し、言語モデルに依存しない信頼度スコアを出力する音声認識装置と音声認識方法と、音声認識プログラムを提供する。
【解決手段】フレーム毎の音声特徴量系列を用いて、その音声特徴量系列に対するモノフォンHMMの各状態に属するGMMから得られる出力確率bs(ot)と、その各状態sの出現確率P(s)との積が最も高いものを求め、最も高い積P(s^)bs^(ot)の対数または出力確率bs^(ot)の対数と、その入力に対する音声モデルの状態に属するGMMまたはポーズモデルHMMの各状態に属するGMMから得られる最も高い出力確率bg^(ot)の対数との差を当該フレームの事前信頼度とし、その事前信頼度を平均化して音声ファイル単位の信頼度スコアを求め、音声特徴量系列を用いて、信頼度スコアに基づき音声認識処理を行う。
(もっと読む)
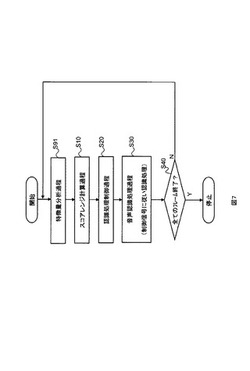
音声認識方法とその装置とプログラム
【課題】音声認識結果の認識信頼度の精度を向上させる。
【解決手段】この発明の音声認識方法は、音声認識過程と、音声文書認識信頼度計算過程と、を含む。音声認識過程は、入力される音声文書を音声認識処理した単語毎に単語認識信頼度を付与した音声認識結果を出力する。音声文書認識信頼度計算過程は、単語認識信頼度から求めた音響信頼度と、音声認識結果を構成する単語間の関連度を示す関連度テーブルを参照して単語毎に当該単語とその他の単語との関連性を表す関連度から求めた文脈信頼度を求め、音響信頼度と文脈信頼度を統合した音声文書認識信頼度を音声文書毎に求める。
(もっと読む)
1 - 10 / 119
[ Back to top ]