
国際特許分類[G10L17/00]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 話者の同定または識別 (337)
国際特許分類[G10L17/00]に分類される特許
101 - 110 / 337
話者交替推定装置、話者識別装置、及びコンピュータプログラム
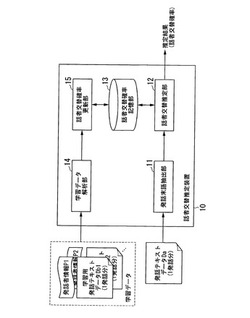
【課題】発話者が交替したか否かを推定することが可能な話者交替推定装置を提供する。
【解決手段】無音区間で区切られた発話の内容を表すテキスト情報Daから発話の末尾部分である発話末語を抽出する発話末語抽出部11と、抽出された発話末語に基づいて発話者が交替したか否かを推定する話者交替推定部12と、を備える。
(もっと読む)
録音装置

【課題】出席者の発言区間や非発言区間を区分して表示するとともに、各区間の雰囲気を一覧表示することができる録音装置を提供する。
【解決手段】録音端末1では、収音部10が収音した音声を、解析部11が会議出席者の発言ごとの区間に区分するとともに、各区間の情況を解析する。再生端末2では、各発言者の発言区間および非発言区間をタイムチャート形式で表示するとともに、各区間の情況を示すマークを表示し、そのマークに基づいて区間を選択して個別に再生できるようにする。
(もっと読む)
複数信号区間推定装置、複数信号区間推定方法、そのプログラムおよび記録媒体
【課題】音声の収録中に話者位置の移動が生じても、同一話者には同一インデックスを付与することを可能とする。
【解決手段】周波数領域変換部110が観測信号を所定長のフレームに順次切り出して当該フレームごとに周波数領域に変換し、音声区間推定部120が周波数領域の観測信号に基づき、各フレームが音声区間に該当するか否かを推定し、到来方向推定部130が周波数領域の観測信号に基づき、当該周波数領域の観測信号の到来方向を各フレームごとに推定し、到来方向分類部140が音声区間に該当すると推定された各フレームを、到来方向の類似性に基づき話者ごとのクラスタに分類する。そして、話者同定部250が所定の時刻までに同一クラスタに分類された各フレームの周波数領域の観測信号に基づき、当該クラスタに係る話者のモデルをクラスタごとに作成し、当該所定の時刻以降の観測信号の話者を各話者のモデルに基づき推定する。
(もっと読む)
映像音声出力装置
【課題】同一人物の発話中にシーンチェンジが発生しても、違和感が生じない音声定位技術を提供する。
【解決手段】映像音声出力装置1は、映像を解析して、話者の位置を特定するとともに、シーンチェンジの有無を検出し、特定された話者がシーンチェンジの前後で同一人物であるか否かを判定する映像解析部11と、特定した話者の位置に音声を定位させるように話者音声定位パラメータの値を設定する話者音声定位パラメータ設定部12と、特定された話者がシーンチェンジの前後で同一人物であると判定された場合には、話者音声定位パラメータ設定部12で設定された話者音声定位パラメータの値に対して、定位位置の変更を小さくするように話者音声定位パラメータの値を調整する話者音声定位パラメータ調整部14と、調整された話者音声定位パラメータの値に従って音声の定位変更処理を行う定位処理部15と、定位変更された音声を出力する音声出力部17と、を備える。
(もっと読む)
発話区間話者分類装置とその方法と、その装置を用いた音声認識装置とその方法と、プログラムと記録媒体
【課題】事前の話者登録を無くす。
【解決手段】この発明の発話区間話者分類装置は、音量音声区間分割部と、特徴量分析部と、代表特徴量抽出部と、セグメント分類部と、セグメント統合部と、を具備する。音量音声区間分割部は、離散値化された音声信号の音声区間検出を行い音声区間セグメントを出力する。特徴量分析部は、音声区間セグメントの音響特徴量分析を行い音響特徴量を出力する。代表特徴量抽出部は、音響特徴量から音声区間セグメントの代表特徴量を抽出する。セグメント分類部は、代表特徴量のそれぞれの間の距離を計算して距離に基づいて音声区間セグメントをクラスタに分類する。セグメント統合部は、隣接する上記音声区間セグメントが同一クラスタに属する場合に、隣接する音声区間セグメントを1個のセグメントとして統合する。
(もっと読む)
情報処理装置、および情報処理方法、並びにコンピュータ・プログラム
【課題】不確実で非同期な入力情報に基づく情報解析により、精度の高いユーザ識別処理を実行する構成を実現する。
【解決手段】カメラやマイクの取得する画像や音声情報に基づいてユーザ識別データを含む観測値を入力し、複数のユーザ確信度を設定したターゲットデータを更新してユーザ識別を行う。各ターゲットと各ユーザとを対応づけた候補データの同時生起確率(Joint Probability)を、観測値に含まれるユーザ識別情報により更新し、更新された同時生起確率値を適用してターゲット対応のユーザ確信度を算出する。本構成により、異なるターゲットが同一ユーザであるとするような誤った推定を排除した精度の高いユーザ識別処理か実現される。
(もっと読む)
車両用飲酒検知装置及び車両用飲酒検知方法
【課題】運転者に煩わしさを感じさせずに当該運転者の飲酒状態を検知することができる車両用飲酒検知装置を提供する。
【解決手段】車両用飲酒検知装置は、運転者が発話した音声を音声認識部11によって検出し、検出した個人認識用の文言に対応する音声データと、話者モデルデータベース13bに発話者毎に記憶されている音声データのうち個人認識用の文言に対応する音声データとを話者照合部12によって比較し、その類似性に基づいて、発話した運転者に対応した話者モデルデータベース13bに発話者毎に記憶されている音声データを選択し、検出した飲酒判断用の文言に対応する音声データと、選択した飲酒判断用の文言に対応する音声データとを飲酒判定部14によって比較し、その類似性に基づいて、飲酒の有無を判定する。
(もっと読む)
会議音声録音システム
【課題】打ち合わせ参加者の作業を最小にしつつ、参加者が適切な権限で容易に自身の発言を検索・修正できる枠組みを提供する。
【解決手段】打ち合わせの発話音声の話者音響特徴量や方向情報などからそれぞれの発話の話者を識別し、修正権設定部107で、その際の信頼度に応じた適切な音声修正権を発話ごとに付与する。また録音後に、音声を容易に検索・修正できる音声データ検索部111、音声修正部112を備えることにより、会議参加者が会議後に容易かつ適切な権限でもって会議音声を修正することができるようにする。このことにより、適切な会議音声の記録・共有を最低限の作業で行いつつ、参加者が自由に議論を行うことを可能とする。
(もっと読む)
スピーチ分析による話者の特徴化
話者の現在の発話を分析することによって所与の状況および場面における話者の現在の行動的、心理的、およびスピーチスタイル上の特徴を判断するためのコンピュータ実装方法、データ処理システム、装置、およびコンピュータプログラム製品。この分析により、第1のピッチから導出された一意の第2の導出結果から成る発話の異なる韻律パラメータと振幅スピーチパラメータとを算出し、これらのパラメータを、様々な行動的、心理的、およびスピーチスタイル上の特徴を表す事前取得済み参照スピーチデータと比較する。この方法は、所与の状況におけるその話者の現在の行動的、心理的、およびスピーチスタイル上の特徴を判断するために、話者の発話の分析に加え、分類スピーチパラメータ参照データベースの形成も含む。  (もっと読む)
(もっと読む)
話者認識装置と話者認識方法およびプログラム
【課題】簡単かつ容易に話者認識を行うことができるようにする。
【解決手段】係数蓄積部40には、音声波形を予測するための予測係数を話者毎に蓄積させておく。予測波形生成部33は、入力音声の音声データと予測係数を用いた演算を行い、話者毎に予測波形を生成する。予測誤差算出部34は、入力音声の音声波形に対する予測波形の誤差を話者毎に算出する。話者特定部35は、算出された話者毎の誤差に基づいて、入力音声の話者を特定する。予測係数は、話者の音声データに対して線形予測分析を行って得られた線形予測係数を用いる。時間領域を周波数領域に変換する処理等を行う必要がなく、時間領域で話者認識を行えるようになる。
(もっと読む)
101 - 110 / 337
[ Back to top ]