
国際特許分類[G10L17/00]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 話者の同定または識別 (337)
国際特許分類[G10L17/00]に分類される特許
111 - 120 / 337
選択式情報提示装置および選択式情報提示処理プログラム
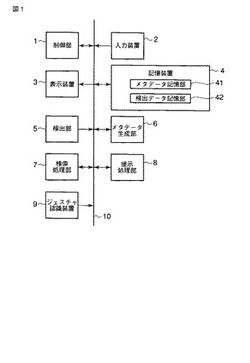
【課題】ユーザの作業や会話の支援に適した情報を提示する。
【解決手段】会議を行なっているユーザが新たな発話を行なった場合、検出部5は、発話情報の音声認識を行なって発話者、対話者、発話内容の文章などを抽出する。メタデータ生成部6は、抽出済みの発話内容の特徴を示す検出データを生成する。検索処理部7は、作成済みファイルのそれぞれのメタデータを読み出し、当該メタデータと検出データとを照合し、作成済みファイルのうち、当該ファイルの特徴情報と検出データ中の各種情報との一致割合が基準値以上である複数のファイルを提示対象のファイルとして決定する。提示処理部8は、提示対象のファイルのうち、一度に提示可能な一定数のファイルを纏めて提示する。
(もっと読む)
データ処理装置、音声変換方法および音声変換プログラム

【課題】外部から入力される音声に含まれる内容が外部に出力される範囲を制限する。
【解決手段】MFPは、外部から入力される音声を取得する音声取得部と、取得された音声を文字情報に変換する音声変換部と、文字情報のうちからユーザを識別するためのユーザ識別情報を抽出するユーザ抽出部と、抽出されたユーザ識別情報に基づいて、文字情報を出力する出力制御部とを備える。
(もっと読む)
音声認識装置と音声認識方法とコンピュータ・プログラムおよびコマンド認識装置
【課題】容易に音声認識を行うことができるようにする。
【解決手段】特徴量抽出部31は、入力音声の波形形状の特徴と該特徴の関係性を特徴量として抽出する。音韻判別部34は、特徴量から音韻を判別する。音韻判別データベース32は、音韻毎の特徴量を不特定話者と話者毎に記憶する。音韻判別部34は、話者判別部37によって話者が判別されるまで、特徴量抽出部31で抽出した特徴量を、音韻判別データベース32に記憶されている不特定話者の音韻毎の特徴量と比較することによって音韻の判別を行う。話者判別部37によって話者が判別されたとき、音韻判別部34は、特徴量抽出部31で抽出された特徴量を、音韻判別データベース32に記憶されている判別された話者の音韻毎の特徴量と比較することによって音韻の判別を行う。
(もっと読む)
画像再生装置及び画像再生処理プログラム
【課題】 複数の画像を順次切換えながら連続的に表示する場合において個々の画像の表示時間を鑑賞者の反応に応じて制御することができる画像再生装置を提供する。
【解決手段】 複数の画像データを記憶する画像データ記憶部8と、複数の画像データにそれぞれ基づく複数の画像を順次表示する画像表示部10と、周囲環境の音声を入力する音声入力部4と、音声入力部4により入力された音声が所定状態であるか否かの判定を行う音声判定部6と、複数の画像を画像表示部10に、画像毎に予め設定されている初期表示時間おきに順次切換えながら連続的に表示している場合において、音声判定部6による判定時に画像表示部10に表示されている画像の表示時間を、音声判定部6による判定結果に基づいて制御する制御部12とを備える。
(もっと読む)
生体認証システム及び認証方法
【課題】本発明は、生体の同一性の判断を、顔認証システムと声紋認証システムとの特徴を考慮して、顔認証システムの弱点を声紋認証システムの長所によって補い、声紋認証システムの弱点を顔認証システムの長所によって補って、総合的に認証速度が高く、他人受け入れ率が低い生体認証システム及び認証方法を提供することを目的とする。
【解決手段】被認証生体が、予め登録された生体をメンバーとする登録生体グループに属する1の生体と同一か否かを、生体の顔情報と声紋情報によって判断する生体同一性認証システムにおいて、予め、登録生体グループに属する各生体の顔情報と声紋を取得して、登録顔情報データベースと、登録声紋データベースを作成し、被認証生体顔情報と登録顔情報データベースに属する各顔情報とを比較することによって、顔の類似度が高い数人に絞り込んでから声紋を比較することによって、被認証生体と同一性を有する生体か否かを認証する。
(もっと読む)
監視制御端末装置
【課題】ICタグやIDカード等の認証機器を携帯する煩わしさや不便さがなく、高い認証精度が得られる、安全性の高い監視制御端末装置を提供する。
【解決手段】顔認証手段、音声認証手段、及び体重認証手段を有するユーザ認証手段5を備え、監視制御端末装置の操作を開始しようとする者が操作を許可された正当な操作員であるかどうかを判定する。これにより、顔画像データと声紋データの2つの生体情報による認証と、さらに体重データによる認証を行うので誤認識率が低く、また、ICタグやIDカード等の認証機器を携帯する必要がないため、これらの認証機器を紛失したり盗難されて不正使用されたりする危険性もない。従って、操作員にとって便利であり、高い認証精度が得られ、安全性の高い監視制御端末装置を提供することができる。
(もっと読む)
認証サーバ、サービス提供サーバ、認証方法、通信端末、およびログイン方法
【課題】より高いセキュリティでユーザ認証を行うことができる認証サーバ、サービス提供サーバ、認証方法、通信端末、およびログイン方法を提供すること。
【解決手段】認証サーバ300は、通信端末から受信した発話データの特徴量をユーザIDに対応付けて登録する声紋抽出登録部330と、特徴量から暗号鍵を生成して通信端末に送信する暗号鍵生成部と340と、通信端末からユーザIDに対応する発話データおよび暗号化されたパスワードが送られてきたとき、その発話データの特徴量がそのユーザIDに対応付けて登録された特徴量と同一か否かを判断する照合部350と、同一であるとき、特徴量から暗号鍵生成部340で生成される暗号鍵により、暗号化されたパスワードを復号し、ユーザIDと対応付けて、情報サービスを提供するサービス提供サーバ200に送信するパスワード復号部360とを有する。
(もっと読む)
人物名付与装置および方法
【課題】受信した映像だけから所望の出演者が登場しているシーンを特定する。
【解決手段】話者名を示す情報で特定された話者名と話者の発話時間とを含む話者時間を第1区間として取得する手段103と、映像中の有音区間から発話を含む第2区間を取得する手段101と、第2区間が第1区間に含まれる場合に第2区間の音声波形から話者を特徴付ける第1特徴量を抽出し第1区間に対応する話者名と特徴量とを対応付ける手段105と、話者毎の特徴量から話者の話者モデルを作成する手段106と、認識対象となる発話時間である第3区間を取得する手段108と、第2区間が第3区間に含まれる場合に第2区間の音声波形から話者を特徴付ける第2特徴量を抽出する手段109と、話者毎の話者モデルの特徴量と第2特徴量との類似度を計算する手段110と、類似度のうち、設定条件の話者モデルの話者名を出演者として認識する手段111と、を具備する。
(もっと読む)
重要語を抽出するサーバ、システム、方法、およびプログラム
【課題】会話の中の重要語を抽出してテキストデータとして提示することのできる装置を提供すること。
【解決手段】サーバ10は、会話の音声データを受信し、受信した音声データを、発言者毎に分離し、分離された音声データのそれぞれを、テキストデータに変換し、変換されたテキストデータのうち、発言時刻が新しいものから所定数のテキストデータを選択し、選択されたテキストデータに含まれる各語の出現頻度に関する指標に基づいて重要語を抽出する。
(もっと読む)
関連付け装置、関連付け方法及びコンピュータプログラム
【課題】夫々の通話に基づく複数の音声データの内で、要件が継続する音声データを一連の音声データとして関連付ける関連付け装置、関連付け方法及びコンピュータプログラムを提供する。
【解決手段】関連付け装置1は、選択した複数の音声データに対する音声認識処理の結果に基づいて、各音声データ間で共通し、かつ要件の内容に関する要件語句の出現率に係る数値を、要件類似度として導出する(S102)。また関連付け装置1は、複数の音声データから抽出した夫々の音声の特徴の比較結果を示す類似度を、話者類似度として導出する(S103)。そして関連付け装置1は、要件類似度及び話者類似度に基づいて、選択した複数の音声データが関連している可能性を示す関連度を導出し(S104)、関連度が予め設定されている閾値以上となる場合に、選択した複数の音声データを関連付ける(S105)。
(もっと読む)
111 - 120 / 337
[ Back to top ]