
国際特許分類[G10L17/00]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 話者の同定または識別 (337)
国際特許分類[G10L17/00]に分類される特許
201 - 210 / 337
音声翻訳装置及びその方法
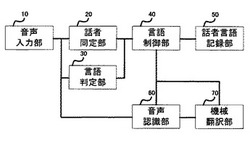
【課題】3人以上が参加する会話で、対話の流れに応じて言語変換方向を決定する音声翻訳装置を提供する。
【解決手段】音声入力部10、話者同定部20、言語判定部30、言語制御部40、話者言語記録部50、音声認識部60及び機械翻訳部70から構成され、発話者と発話言語の対応関係を保持しておき、発話者と発話言語の対応関係を記録して、現在対話を進める話者対を動的に切り替えながら、対話の流れに応じて言語変換方向を自動的に決定できる。
(もっと読む)
話者顔画像決定方法及び装置及びプログラム

【課題】話者名が分からない場合においても、映像を視聴することなく話者を特定する。
【解決手段】本発明は、教師なし話者認識技術により入力された映像の音声を認識し、当該映像の開始・終了時刻からなる話者区間及び該話者区間に対応する話者毎に話者IDを付与し、話者認識結果として話者認識結果記憶手段に格納し、入力された映像から顔の位置を検出する手法により話者IDに対応する話者区間に含まれる顔画像を検出し、話者IDと共に話者ID毎顔画像記憶手段に格納し、話者ID毎画像記憶手段に記憶されている各話者IDの各顔画像に対する個人特徴を抽出し、顔画像に対する個人特徴から話者ID毎に最も相応しい個人特徴を決定し、話者個人特徴決定結果記憶手段に格納する。
(もっと読む)
個人認証装置、個人認証装置の制御方法、個人認証システム、個人認証装置制御プログラム、ならびにそれを記録した記録媒体
【課題】従来の生体認証が抱える問題点を生じることなく、プライバシーを容易に、かつ堅固に保護することができる個人認証装置を実現する。
【解決手段】個人認証装置10は、利用者の顎関節運動による顎関節振動を検出する検出部1と、利用者の生体情報として、上記顎関節振動から上記利用者の頭蓋骨の共振周波数および該共振周波数の振動振幅を解析する解析部2と、解析部2から与えられた上記共振周波数および上記振動振幅を、登録装置4に予め登録されている上記利用者の生体情報と比較照合し、認証を行う認証部3とを備えている
(もっと読む)
音声合成出力装置
【課題】本発明は、発話者に対して意識的な入力作業を強いることなく、複数の発話者の音声データを収集可能な音声合成出力装置の提供を目的とする。
【解決手段】音声入力部10を介して入力された発話者の音声が音声認識部14によって文字列の音声データに分解され、音声合成部15によってその文字列の音声データを用いて音声合成処理された合成音を出力する音声合成出力装置であって、発話者を自動的に特定するユーザ認証部11を備え、ユーザ認証部11によって自動的に特定された発話者毎にその文字列の音声データが音声データベース13に格納されることを特徴とする、音声合成出力装置。
(もっと読む)
電子機器
【課題】各ユーザに最適な音響モデルを選択し、より確実に音声認識を行うことができる電子機器を提供することである。
【解決手段】ディジタルテレビ受像機100において、音響モデルパターン取得手段(CPU121、音響モデルパターン取得プログラム123d)によって、識別情報抽出手段(CPU121、識別情報抽出プログラム123c)により抽出された識別情報に対応する音響モデルパターンを取得し、コマンド情報抽出手段(CPU121、コマンド情報抽出プログラム123e)によって、取得された音響モデルパターンを用いて、音声情報取得部11により取得された音声情報の音声認識を行い、コマンド情報を抽出し、制御手段により、抽出したコマンド情報に基づいて制御を行う。
(もっと読む)
話者認証登録及び確認方法並びに装置
【課題】話者認証登録及び確認方法並びに装置を提供する。
【解決手段】話者の登録発声から音響的特徴ベクトルシーケンスを抽出することと、音響的特徴ベクトルシーケンスを使って話者テンプレートを生成することとを備え、音響的特徴ベクトルシーケンスを抽出する上記ステップは、登録発声に基づいて、登録発声のスペクトルにおけるフォルマントの位置とエネルギーをフィルタリングする、話者の登録発声のためのフィルタバンクを生成することと、生成されたフィルタバンクによって登録発声のスペクトルをフィルタリングすることと、フィルタリングされた登録発声から音響的特徴ベクトルシーケンスを生成することとを備える話者認証登録方法。
(もっと読む)
話者認証確認方法及び装置
【課題】話者登録認証方法を提供する。
【解決手段】話者によって発話されるパスワードを含む音声を入力し、入力音声から音響特徴ベクトルシーケンスを抽出し、抽出音響特徴ベクトルシーケンスと登録話者によって登録された話者テンプレートとをDTW整合し、DTM整合の音響特徴ベクトルシーケンスと話者テンプレートとの複数の局部距離の各々を計算し、小さい局部距離に多くの重みを与えるために算出された前記各局部距離を非線形変換し、複数の非線形変換局部距離に基づいてDTW整合点数を算出し、入力音声が前記登録話者によって発話されたパスワードであるかを決定するため前記整合点数を所定の識別閾値と比較する。
(もっと読む)
音声処理装置、音声処理方法および音声処理プログラム
【課題】誤動作の発生を低減する音声処理装置を提供する。
【解決手段】操作者または操作者以外の者の発声を含む音声を入力するマイク104と、入力された音声のうち音声処理の対象とする区間として操作者により指定された指定区間の入力を受付ける指定区間受付部204と、入力された音声から発声が存在する区間である発声区間を検出する発声区間検出部202と、入力された音声に基づいて、操作者または操作者以外の者のいずれが発声の発話者であるかを判断する話者判断部203と、指定区間受付部204が受付けた指定区間と発声区間検出部202が検出した発声区間とが重複する部分を検出し、重複する部分が検出された場合であって、話者判断部203により話者は操作者以外の者であると判断された場合に、重複する部分が含まれる発声区間を処理区間として決定する処理内容判断部205と、を備えた。
(もっと読む)
ユーザ認証システム、不正ユーザ判別方法、およびコンピュータプログラム
【課題】再生機で再生される声を用いて認証を得ようとする不正者を容易に検知する。
【解決手段】
パーソナルコンピュータ1に、音声認証技術によるユーザ認証の対象者が声を発する前の時間帯にその対象者の周囲の音である周囲音を集音する音声データ取得部132と、その時間帯を複数に区切った区間ごとの、集音された周囲音の所定時間当たりの強さを表わす強さレベルを算出し、算出した2つの強さレベルのうち後の区間に係る強さレベルが前の区間に係る強さレベルと所定の値との和よりも大きい場合に、その対象者を再生音で認証を得ようとする不正なユーザであると判別する、偽装判別部134と、を設ける。
(もっと読む)
位置検出装置、自律移動装置、位置検出方法および位置検出プログラム
【課題】音源物体の検出成功率を向上させるとともに安定させること。
【解決手段】ロボット装置100において、画像入力部112によって入力された画像と、音源情報の適用視覚情報とに基づいて画像処理手順を実行して音源物体102の視覚特徴を検出し、音源物体102の少なくとも方位を示す視覚定位情報を出力する視覚特徴検出定位部114と、音声入力部113によって入力された音声と、音源情報の適用聴覚情報とに基づいて音声処理手順を実行して音源物体102の聴覚特徴を検出し、音源物体102の少なくとも方位を示す聴覚定位情報を出力する聴覚特徴検出定位部115と、検出戦略情報に基づいて、視覚特徴検出定位部114または聴覚特徴検出定位部115を制御し視覚定位情報または聴覚定位情報から音源物体102の存在する位置を検出する音源物体検出部116とを備えた。
(もっと読む)
201 - 210 / 337
[ Back to top ]