
国際特許分類[G10L21/02]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 他の可聴信号,または不可聴信号への音声信号変換処理,例.特性や明瞭性を修正するための視覚,触覚 (2,017) | 音声の強調,例.雑音低減またはエコー除去 (1,255)
国際特許分類[G10L21/02]に分類される特許
1,221 - 1,230 / 1,255
音声認識方法、その装置およびプログラム、その記録媒体
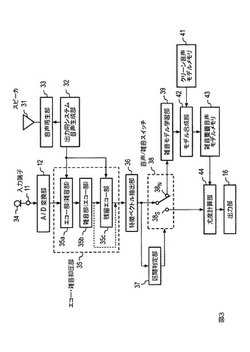
【課題】 音声応答装置の音声認識においてガイダンス音(音声)がエコーとして混入しても高い認識率とする。
【解決手段】 システム音声生成部32からのガイダンス音を用いてスピーカ31からマイクロホン34に回り込むエコー信号を、マイクロホン34よりの入力信号に対し抑圧処理し、更に背景雑音の抑圧処理を行い、その後、残留エコーを抑圧する。エコー及び雑音抑圧された入力信号の特徴ベクトルを抽出し、特徴ベクトルより、入力信号が音声区間か雑音区間かの判定を行い、雑音区間であれば、その特徴ベクトルについて雑音モデルを学習し、雑音モデルとクリーン音声モデルとを合成して雑音重畳音声モデルとする。入力信号が音声区間と判定された特徴ベクトルに対し、雑音重畳音声モデルの尤度を計算し、尤度が最も高いモデルの認識カテゴリを認識結果として出力する。
(もっと読む)
調波ノイズの減法キャンセル方法

【課題】抑制されるべき一つ以上の正弦波ノイズ(9)によって有用信号(8)が擾乱されるといった可聴処理における一般的な問題を解決することを目的とする。
【解決手段】本発明は、擾乱された有用信号(1)における未知の周波数の正弦波外乱(9)をキャンセルする方法であって、振幅、位相、および周波数といった正弦波外乱(9)の3つのパラメータを推定(2)するステップと、推定されたパラメータに基づいて基準信号(5)を生成(4)するステップと、擾乱された有用信号(1)から基準信号(6)を減算(6)するステップとを有する方法を提供する。推定は、拡張形カルマンフィルタによって行われる。
(もっと読む)
音声入力装置
【課題】 仕分け担当者が各ラインに直交する方向に一列に並んでいる場合において、対応する仕分け担当者の発声についての音声強調や雑音低減の効果が期待できる音声入力装置を提供する。
【解決手段】 音源の周りに並べられ、かつ、音源から同一距離だけ離間した位置に設けられた3つのマイクロフォンで構成されているマイクロフォン群100を備え、各マイクロフォンにおける周波数帯域毎のパワースペクトルを算出し、各マイクロフォンにおける周波数帯域毎のパワースペクトルの最大値及び最小値をそれぞれ求め、パワースペクトルの最大値に対するパワースペクトルの最小値の比率を、音源の周りに並べられた前記3つのマイクロフォンの中で2つのマイクロフォン間に設けられたマイクロフォンにおける周波数帯域毎のパワースペクトルに乗算するようにした。
(もっと読む)
残響サウンド信号のコーディング
本発明は、オーディオエンコーダ及びデコーダ並びにオーディオ符号化及び復号化のための方法に関する。エンコーダでは、オーディオ信号が、エコーの無い信号部分と、オーディオ信号に関連する残響場についての情報とに分割され、好ましくは、残響時間及び残響振幅のようなほんの僅かなパラメータを用いる表現によって分割される。その後、エコーの無い信号が、オーディオコーデックを使用して符号化される。デコーダでは、エコーの無い信号部分が、オーディオコーデックを使用して復元され、この復元されたエコーの無い信号部分が、残響場に関する情報に従って残響を付与することによって、好ましくは、残響場情報に基づいて生成された室内インパルス応答による畳み込みによって、実質的に元のオーディオ信号に変換される。本発明によれば、エコーの無いオーディオ信号を符号化することができるだけのニーズに関係のあるオーディオコーデックは、このように、残響オーディオ信号に対して不十分なパフォーマンスをもたらすパラメトリックオーディオコーデックの問題を解決する。 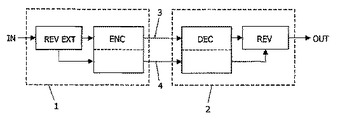 (もっと読む)
(もっと読む)
メッセージを変更するための方法及びシステム
本発明は、音声コンテンツを有する入力メッセージ(IM)を変更するための方法及びシステムについて記載する。当該方法は、入力メッセージ(IM)の音声コンテンツ(A)をテキスト表示(TR)の要素に変換するステップと、入力メッセージ(IM)の音声コンテンツ(A)をテキスト表示(TR)に関連する構成音声要素(As)に分割するステップと、編集入力に従って、テキスト表示(TR)を編集するのに適した形式でテキスト表示(TR)をレンダリングするステップと、出力メッセージ(OM)の変更された音声コンテンツ(A’)を与えるように、編集されたテキスト表示(TR’)に従って、音声コンテンツ(A)の関連する音声要素(As)を改変するステップとを有する。 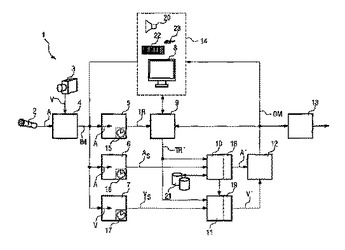 (もっと読む)
(もっと読む)
会議システム
会議システム(1)は、中央ユニット(2)及び、前記中央ユニットに接続可能なスピーカユニット(3)を備える。スピーカユニット(3)からのスピーチ信号を合成し、当該合成されたスピーチ信号を前記ユニットに供給するように動作する中央ユニット(2)は、フィードバックを抑制する適合型フィルタ(36)を備える。各スピーカユニット(3)は、マイク(33)、スピーカ(34)、有効化スイッチ(35)、及びマイク(33)とスピーカ(34)との間に接続される適合型フィルタ(36)を備える。該スピーカユニットが有効化されていない場合、適合型フィルタ(36)は、エコーキャンセラとして動作する一方で、該スピーカユニットが有効化されている場合フィードバック抑制器として動作する。スピーカ(34)を恒久的にオンに維持することによって、フィルタ(36)の誤適合によるいかなる過渡信号も回避される。 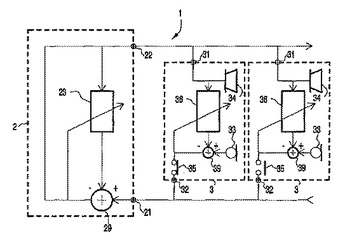 (もっと読む)
(もっと読む)
バーク帯域ワイナ・フィルタリング及び修正されたドブリンガ雑音評価に基づく雑音抑制
雑音抑制装置において、入力信号は、離散フーリエ解析によって周波数領域に変換され、バーク帯域に分割される。雑音は、それぞれの帯域(85)において評価される。雑音を評価する回路は、雑音の間の方が音声の間よりも遅い時定数で雑音評価を更新する平滑化フィルタを含む。この雑音抑制装置は、入力信号のそれぞれのフレームの信号対雑音比と逆比例する雑音抑制ファクタ(89)を調整する回路(86)を更に含む。雑音評価は、それぞれの帯域において信号から減算される。離散フーリエ変換によって信号は時間領域に再変換され、重複し合成されたウィンドウが、処理の間に生じうる歪みを除去する。 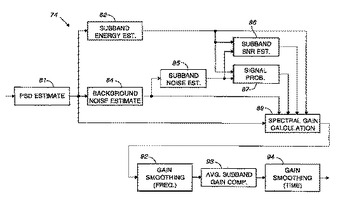 (もっと読む)
(もっと読む)
適応ビームフォーマ、サイドローブキャンセラ、ハンズフリー通話装置
適応ビームフォーマユニット191は、夫々のマイクロホン101,103の配列からの入力音声信号u1,u2を処理するよう配置され、入力音声信号の第1の信号u1に第1の適応フィルタf1(−t)によりフィルタをかけ、且つ、入力音声信号の第2の信号u2に第2の適応フィルタf2(−t)によりフィルタをかけることにより所望の音源160からの音に大部分は対応する第1の音声信号zを出力として生ずるよう配置され、第1のフィルタf1(−t)及び第2のフィルタf2(−t)の係数は夫々第1のステップサイズα1及び第2のステップサイズα2に適応性があるフィルタ和ビームフォーマと、第1のノイズ測度x1及び第2のノイズ測度x2を入力音声信号u1,u2から導出するよう配置されるノイズ測度導出手段と、第1のステップサイズα1に関して第1のノイズ測度x1を、及び、第2のステップサイズα2に関して第2のノイズ測度x2を夫々分母に有する式により前記第1及び第2のステップサイズα1,α2を決定するよう配置される更新ユニットとを有する。これは、相関性がある音の干渉の影響に対して比較的ビームフォーマにローバスト性を持たせる。ビームフォーマは、また、よりノイズを除去された所望の音の推定をもたらすサイドローブキャンセラトポロジーに組み込まれても良い。これは、関連する、より高度な適応フィルタf1(−t),f2(−t)を更新する際に使用可能である。このようなビームフォーマは、通常、ハンズフリー通話システムでの用途に有効である。 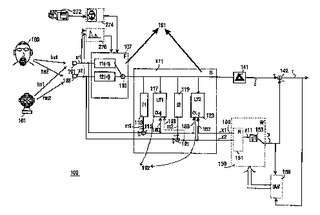 (もっと読む)
(もっと読む)
音声妨害を検出および除去する方法および装置
マイクロフォンによって受信された音声信号に関連するノイズ妨害を低減する方法が提供される。この方法は、前記音声信号のノイズ妨害を前記音声信号の残りの成分に対して強調する操作から開始する。次に、前記音声信号のサンプリングレートが下げられる。次に、検出信号を定義するために、前記サンプリングレートを下げた前記音声信号に偶数次の導関数が適用される。次に、前記音声信号の前記ノイズ妨害が、前記検出信号の統計平均に従って調整される。音声信号に関連する妨害をキャンセル可能なシステム、ビデオゲームコントローラ、および音声信号に関連するノイズ妨害を低減する集積回路が含まれる。 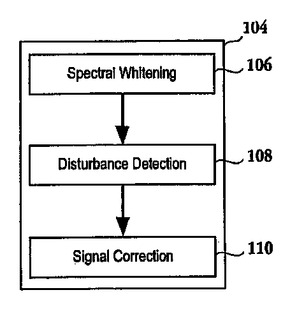 (もっと読む)
(もっと読む)
周波数領域で多重経路多チャネル混合信号のブラインド分離のための方法及びその装置
本発明は、周波数領域で正規化された多チャネルブラインドデコンボリューションを用いてブラインド原信号を分離するための方法及びその装置を提供する。本発明における多チャネル混合信号は、Mサンプルのr連続ブロックからなってNサンプルのフレームを形成する。混合信号のフレームは、DFT(Discrete Fourier Transform)を用いたオーバーラップ−セーブ(overlap-save)方式によって、周波数領域で分離フィルタを用いて分離される。分離された信号は、非線形関数に適用するために逆DFTを用いて時間領域に再び変換する。分離された信号と非線形に変形された信号との間の相互電力スペクトルが計算され、分離された信号の電力スペクトル及び平らなスペクトルを有する非線形に変形された信号の電力スペクトルによって正規化される。本発明では、最初のL相互相関係数を抽出するために、時間領域の制限条件を適用した。 (もっと読む)
1,221 - 1,230 / 1,255
[ Back to top ]