
臨床データから得られるシグネチャに対する信頼度インジケータを決める方法、及びあるシグネチャを他のシグネチャより優遇するための信頼度インジケータの使用
本発明は、サンプル群から集められた臨床データから得られるシグネチャの少なくとも1つの組に対する信頼度インジケータを決めるための方法及び装置に関する。これらシグネチャは、前記サンプル群から臨床データの特徴を検出することにより得られ、これらシグネチャの各々は、前記サンプル群を層別する層別値の第1の組を生成する。前記サンプル群から得られる前記シグネチャに少なくとも1つの追加の及び並列する層別ソースを供給し、前記少なくとも1つの追加の及び並列する層別ソースは、前記シグネチャから独立し、層別値の第2の組を生成する。各夫々のサンプルに対し、第1の層別値は真の基準層別値と比較され、前記第2の層別値は前記真の基準層別値と比較される比較が行われる。前記シグネチャは、前記第1及び第2の層別値が前記真の基準層別値と一致するかを示す類似度インジケータを割り当てられる。前記シグネチャの類似度を決めるとき、前記類似度インジケータは、入力として実行する。

【発明の詳細な説明】
【技術分野】
【0001】
本発明は、サンプル群から集められた臨床データから得られるシグネチャ(signature)の少なくとも1つの組に対する信頼度インジケータを決めるための方法及び装置に関する。前記シグネチャは、前記サンプル群から前記臨床データの特徴を検出することにより得られ、これらシグネチャの各々は、前記サンプル群を層別(stratify)する層別値の第1の組を生成する。
【背景技術】
【0002】
高スループット(high-throughput)分子測定はしばしば、生体試料(サンプル)を層別するのに役立つデータセットにおけるパターンを特定するために、臨床応用の目的で分析される。そのような応用は、例えば患者の特定のカテゴリーの診断シグネチャとして使用されることができる、例えば遺伝子発現データ(gene expression data)からの特徴サブセットの選択である。このような診断シグネチャは、病気の臨床診断、病期分類及び/又は治療の選択(例えばある病気に対する治療レジメントの肯定応答及び否定応答)に用いられてもよい。患者の臨床状態は一般に、上記シグネチャの発見中に分かることに注意されるべきである。この"グランドトルース(ground truth)"は、それからサンプルが得られる臨床研究の一部としてしばしば利用可能である、又は(例えばDNAメチル化、プロテオミクス及びSNPのような)シグネチャの発見に使用される以外の何らかの分子特性を分子測定を用いて検出することにより分かってもよい。診断に用いる、すなわち臨床状態を識別するのに使用されることができるこれら測定値の中からパターンを発見するために、様々な統計及び機械学習アルゴリズムがこのようなデータセットに適用されるのが一般的である。さらに単変量(univariate)シグネチャは、関心のある殆どの病気及び状態に対し発見されるとは考えにくいという認識が生物学者及び臨床医の間で増えていて、前記シグネチャの発見の組合せチャレンジを増やす多変量(multivariate)シグネチャが必要であると信じられている。この領域を悩ませる1つの問題は、前記データセットが測定値は多いが事例は少ないと必ず特徴付けられる、すなわち患者よりもかなり多くの測定値が存在していることである。結果として、パターン発見方法は、偽のパターン、すなわち所与のデータでは上手く予測するが、新しい事例では上手く予測しないパターンを発見する傾向がある。これは、過剰適合(overfitting)とも呼ばれる。低品質である又は臨床問題に関連していなさそうと信じられる幾つかの測定値を処分することにより測定値の数を減少する様々な方法、例えば再サンプリング及び相互検証は、過剰適合を克服するために利用されていたが、これらの方法でも前記問題は完全に克服されることができない。
【発明の概要】
【発明が解決しようとする課題】
【0003】
本発明の目的は、このような過剰適合の問題を克服する改良した方法を提供することである。
【課題を解決するための手段】
【0004】
ある態様によれば、本発明はサンプル群から集められた臨床データから決められるシグネチャの少なくとも1つの組に対する信頼度を決める方法に関し、前記シグネチャは前記サンプル群から前記臨床データの特徴を検出することにより得られ、これらシグネチャの各々は、前記サンプル群を層別する層別値の第1の組を生成する。前記方法は、
前記サンプル群から得られる前記シグネチャに少なくとも1つの追加の及び並列する層別ソース(stratification source)を供給するステップであり、この少なくとも1つの並列する層別ソースは、前記シグネチャから独立し、前記サンプル群に対する層別値の第2の組を生成しているステップ、
各夫々のサンプルに対し、層別値の第1の組を真の基準層別値と、及び層別値の第2の組を真の基準層別値と比較するステップ、
これら第1及び第2の層別値が前記真の基準層別値と一致するかを示す類似度インジケータ(similarity measure indicator)をシグネチャに割り当てるステップ、並びに
前記シグネチャの信頼度を決めるとき、前記類似度インジケータを入力として実行するステップ
を有する。
【0005】
それ故に、シグネチャの"整合(アライメント)"のために、これらシグネチャを特定の並列する層別基準と比較し、それ故に偽のパターンを削除するのに役立つことが可能である。
【0006】
ある実施例において、前記類似度インジケータを入力として実行するステップは、
それらの層別値が前記真の基準層別値と一致しないことを示す類似度インジケータをどのシグネチャが持っているかを特定するステップ、及び
これら特定されたシグネチャに対し、これらシグネチャの層別値が少なくとも1つの並列する層別ソースの層別値とどの位整合しているかを示す整合インジケータを決めるステップであり、この整合インジケータはシグネチャの信頼度を示しているステップ、
を有する。
【0007】
明確にするために、詳細な説明において表1及び表2を参照すると、これはあるシグネチャに対し、このシグネチャが間違って分類したサンプルが真の基準層別値と比較されたことに対して判断される(この場合、偽陰性(FN)又は偽陽性(FP))ことを意味する。この第2のステップは、これらの誤分類を並列する層別ソースと比較すること、すなわち他の"信頼度ステップ"が行われることである。この比較は、これら誤分類の2つが並列する層別ソースと一致していることを示す。表1及び表2は、(誤)分類の全ての起こり得る組合せをリストにすることを主目的とし、例えば100又は200個のサンプルを用いた実施例を表しているのではないことに注意すべきである。
【0008】
ある実施例において、整合インジケータを決める前記ステップは、シグネチャの層別値が少なくとも1つの並列する層別ソースにより生成される層別値とどの位の割合で一致するのかを決めるステップを有し、この数は、シグネチャの信頼度を示している。
【0009】
表3を参照すると、前記実施例は、3つのシグネチャ、つまりシグネチャ1、シグネチャ2及びシグネチャ3から選択する利点を持つ。これは単に明確にするためであり、サンプル数は一般にこれよりも多い実際のシナリオを反映していないことに再度注意すべきである。このシナリオにおいて、全てのシグネチャは、(真の値に比べ)50%しか正しい分類を示さない。この追加の1つ以上の並列する層別値がないとき、これら3つのシグネチャを区別することは不可能である。しかしながら、表を詳しく見ることにより、シグネチャ1に対しては、これら誤分類の2つが並列する層別値と一致し(サンプル2及び4)、シグネチャ2に対しても、これら誤分類の2つが並列する層別値と一致し(サンプル4及び5)、しかしシグネチャ3に対しては、これら誤分類の3つが並列する層別値と一致している(サンプル2、5及び7)。この特定の事例において、整合インジケータは単に"計数"(又はパーセンテージ)、すなわち前記並列基準と一致する数、すなわち"2"、"2"及び"3"である。それ故に、シグネチャ3は、4つの誤分類の3つが前記並列する層別値と一致しているので、残りのシグネチャよりも信頼できるシグネチャであるとみなされる。
【0010】
さらに明確にするために、癌患者を侵攻性(アグレッシブ)又は非侵攻性(ノンアグレッシブ)として層別しようとする、例えば遺伝子発現から得られる2つのシグネチャS1及びS2が存在すると仮定する。このシグネチャ(基本モダリティ、遺伝子発現)を単に使用することにより、両方のシグネチャが例えば4つの誤分類を行っていると言うことだけが可能であり、それ故にシグネチャが臨床的又は生物学的に関連している可能性が高いことに関して確信を持って進めることは不可能である。並列する層別ソース(例えば臨床予後インデックス)は、同じ患者の別々の層別を侵攻性及び非侵攻性にもする。この並列する層別は、S2は、S1と比較した臨床予後インデックスに比べ、多くの誤分類をすることに気付くことを可能にする。これに基づいて、S1は、並列する層別とより合致(in line)しているので、S2よりも"良好な"シグネチャであると結論を下すことができる。それ故に、S1はS2に比べより高い信頼度インデックスを持つ。
【0011】
ある実施例において、並列する層別は、以下の測定値、
臨床情報、
撮像データ、
高スループット分子測定から得られるデータ、又は
この分子測定の生物学的注釈
の1つ以上に基づいている。
【0012】
ある実施例において、前記方法はさらに、前記比較するステップ、前記割り当てるステップ及び前記実行するステップを、既定の基準が満たされるまで連続して繰り返すステップを有する。
【0013】
ある実施例において、既定の基準が満たされるまで前記比較ステップの繰り返しは、1回のステップでシグネチャをランク付けするためであり、どのシグネチャが後続するステップで考慮されるべきかを選ぶための選択基準として、信頼度インジケータを実行することに基づいている。
【0014】
それ故に、この信頼度インジケータのこのような繰り返しの利用を用いることにより、過剰適合の影響は、並列する基準の層別能力に依存して低下又は少なくとも減少する。
【0015】
ある実施例において、既定の基準は、以下の
−固定の繰り返し数、
−所望する整合性能、
−所望する信頼度性能
の少なくとも1つ以上に基づいて、前記繰り返しを終わらせるための1つ以上の基準を含む。
【0016】
これが排他的なリストではないことを注意しておく。
【0017】
他の態様によれば、本発明は、コンピュータプログラムプロダクトがコンピュータ上で実行されるとき、上述した方法のステップを実施するように処理ユニットに命令するためのコンピュータプログラムプロダクトに関する。
【0018】
さらに他の態様によれば、本発明は、サンプル群から集められた臨床データから得られるシグネチャの少なくとも1つの組に対する信頼度インジケータを決めるための装置に関し、これらシグネチャは、これらサンプル群から臨床データの特徴を検出することにより得られ、これらシグネチャの各々は、サンプル群を層別する層別値の第1の組を生成する。前記装置は、少なくとも1つの追加及び並列する層別ソースを前記サンプル群から得られるシグネチャに供給する手段であり、この少なくとも1つの並列する層別ソースは、前記シグネチャから独立し、前記サンプル群に対する層別値の第2の組を生成する手段、
各夫々のサンプルに対し、層別値の第1の組を真の基準層別値と、及び層別値の第2の組を真の基準層別値と比較するための処理器、
前記第1及び第2の層別値が前記真の基準層別値と一致しているかを示す類似度インジケータを前記シグネチャに割り当てるための処理器、並びに
前記シグネチャの信頼度を決めるとき、前記類似度インジケータを入力として実行するための処理器
を有する。
【0019】
本発明のこれら態様は、如何なる他の態様と各々組み合わされてもよい。本発明のこれら及び他の態様は、以下に記載の実施例から明らかあり、これら実施例から説明される。
【図面の簡単な説明】
【0020】
【図1】本発明による方法のフローチャート。
【図2】並列基準をシグネチャ発見処理に加える図。
【図3】本発明による装置。
【発明を実施するための形態】
【0021】
本発明の実施例は、図面を参照して単に例として説明される。
【0022】
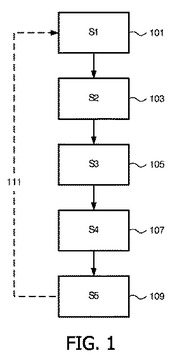
図1は、サンプル群から集められた臨床データから得られるシグネチャの少なくとも1つの組に対する信頼度インジケータを決める、本発明による方法のフローチャートを示す。
【0023】
ステップ101(S1)において、これらシグネチャは、前記サンプル群から臨床データの特徴を検出することにより生成される。これらサンプル群は、例として、潜在的な癌患者から集められたサンプルを有し、臨床データは、これらサンプルに行われる高スループット分子測定とすることができる。このようなデータの分析の結果は、シグネチャの組、すなわち癌のこの特定の型に対する特徴であるシグネチャを得る。全てのサンプルを通じて共通する特徴を示す臨床データの如何なる特徴もシグネチャ又は分子シグネチャとも呼ばれる用語で表される。サンプルの組の試験分類を提供するシグネチャを誘導するのに使用される特徴サブセットを発生させる例えば遺伝的アルゴリズム(GA)のような検索方法を用いることにより、上記シグネチャを得る様々な方法が利用されてもよい。さらに、このようなGAに基づいた実験に関する詳細は、"Schaffer, A. Janevski及びM. Simpson著、"A Generic Algorithm Approach for Discovering Diagnostic Patterns in Molecular Measurement Data," presented at Proceedings of the 2005 IEEE Symposium on Computational Intelligence in Bioinformatics and Computational Biology, CIBCB 2005, La Jolla, CA, USA, 2005"に見られ、参照することにより全て含まれる。これらシグネチャは、シグネチャに関してサンプル群を層別する第1の層別値を生成する。これは、サンプル毎に、1つの層別割り当てだけが存在し、ここで各サンプルは"侵攻性"若しくは"非侵攻性"と割り当てられるか、又は"0"若しくは"1"またさらには例えば1から3のような特定のスケールでラベルが付けられることができる。それに従って、100個のサンプルのシグネチャが存在している場合、特定のシグネチャは、これら100個のサンプルの各々に例えば0又は1のような層別値を供給する。
【0024】
上述したように、本発明は、比較的多くの測定に比べサンプルが非常に少ないので、データがそれだけで"良好な"シグネチャを保証するには十分ではないシナリオを扱う。このようなデータの分析は、このデータを上手く特徴付けしたように偶然見える偽のパターンを見つけやすい。後でさらに詳細に説明されるように、これらパターンを追加として特徴付けることにより、"実際の"(より有望な)パターンから偽のパターンを識別することが可能である。
【0025】
ステップ103(S2)において、少なくとも1つの並列する層別ソースが前記サンプル群から供給され、この少なくとも1つの並列する層別ソースは、前記シグネチャから独立し、サンプル群に対する層別値の第2の組を生成する。これは、特徴付けをするための追加のソースが供給されることを意味するが、ここで追加のソースは、別の方法を用いて得られる。それに従って、各夫々のサンプルに対し、前記シグネチャに加え、並列する層別ソースが供給され、この並列する層別ソースは、第2の層別値、例えば"侵攻性"若しくは"非侵攻性"又は"0"若しくは"1"を生成する。これは、サンプル1は、例えばサンプル1を"非侵攻性"と層別する層別値が割り当てられ、及び追加のソースとして、並列する層別ソースが前記サンプルもさらに"非侵攻性"と層別することを意味する。それに従って、あるソースは、臨床データから得られるシグネチャであり、並列する層別ソースは、臨床情報、例えば乳癌に対する予後予測因子(prognostic indices)、例えば以下のNottingham Prognosis Index(Pinder, Elston他2003), National Institutes of Health Consensus (NIH 2001), and the St. Gallen Cosensus Conference (Ciatto, Cecchini他1990)から得られる。このような並列する層別を追加する理由は、シグネチャをこれらの"整合"に対し、特定の並列する層別基準と比較することを可能にするためである。これは後で詳細に説明される。一般に、本発明の目的は、全く異なる方法を用いることにより、同じ種類の層別(例えば侵攻性対非侵攻性)を追求することである。
【0026】
このような並列する層別ソースの他の実施例は、撮像データから得られるソースであり、これは、例えば高スループット分子測定のような"核(core)"の分析に類似する方式でサンプルを層別するような方式で分析される該当する全ての撮像モダリティ(造影剤を使用する又は使用しないMRI、CT)からのデータである。これは一般に、画像の特徴(形状、構造等)を分析し、各画像/サンプルに対するカテゴリー(例えば侵攻性又は非侵攻性)を出力することにより行われる。他の並列する層別ソースは、高スループット分子測定、つまり遺伝子発現データ、DNAメチル化、質量分析プロテオミクスである。このような測定からのデータは、前記サンプルを"核"の高スループット測定に類似して特徴付ける方法で分析される限り、基本的なシグネチャ発見処理をするためにその出力を使用することが可能である。さらに他の並列する層別ソースは、注釈である、つまり高スループット分子測定の特徴は、例えばそれらの生物学的特徴に基づいて特徴付けられることができる。例えば注釈に広く用いられるソースは、遺伝子オントロジー(GO(geneontology.org参照))であり、ここで遺伝子はそれらの分子機能、生物学的処理及び細胞構成要素に対し注釈が付けられる。このような注釈は、例えば分子機能に関して特徴(例えば遺伝子)の組を特徴付けるのにも使用されることができる。このデータの表示(ビュー)は次いで、サンプルを層別するために、上記他の形式と同じ方法で使用されることができる。
【0027】
ステップ105(S3)において、各夫々のサンプルに対し、第1の層別値及び第2の層別値が真の基準層別値と比較される比較ステップが行われる。この真の基準層別値は、データが5年又は10年間フォローアップしている例えば癌患者に関する後ろ向き研究(retrospective study)によるので、"グランドトルース"と考えられ、それ故に癌が再発したかが分かる。それに従って、サンプルに対し、このステップにおいて、サンプルnに対する第1の層別値及び並列する層別ソースに対する第2の層別値(例えば画像データに基づく)は、このグランドトルース値と比較される。
【0028】
ステップ107(S4)において、シグネチャは、前記第1及び第2の層別値が前記真の基準層別値と一致するかを示す類似度インジケータが割り当てられる。例として、サンプルnに対するこの基準層別値(グランドトルース値)は、"侵攻性"であり、第1の層別値及び第2の層別値は夫々、"侵攻性"及び"非侵攻性"であり、類似度インジケータは、"真"及び"偽"又は"真陽性"及び"偽陽性"である。これは、"+"及び"−"とラベル付けられることもできる。これは、n個のサンプル全て、すなわち各夫々のサンプルに対し繰り返され、第1の層別値及び第2の層別値が前記真の基準層別値と比較される。
【表1】
【0029】
表1は、2つの層別"侵攻性"及び"非侵攻性"並びに8個のサンプルを用いて、この方法が最も簡単な形式でどのように実施されるかを説明するための実施例を示す。第1の列はサンプルを示し、第2の列は真の基準層別値"グランドトルース"であり、第3の列は第1の層別値"並列する層別値"であり、及び第4の列は第2の層別値"予想クラス"である。各試験サンプルに対し"真"のクラスを与える場合、誘導されるシグネチャがサンプルのクラスを正確に予想するかが分かる。
【0030】
107(S4)を参照すると、シグネチャに類似度インジケータの割り当てが表2に示される。"TP(true-positive)"は"真陽性"を意味し、"TN(true-negative)"は"真陰性"を意味し、"FP(false-positive)"は"偽陽性"を意味し、"FN(false-negative)"は"偽陰性"を意味する。それに従って、例としてサンプル1に対し、並列する層別に対する類似度インジケータは、真の値がサンプル1は侵攻性であると述べ、並びに第1及び第2の層別値は同じであると予想するので、"TP"である。他方、サンプル2に対し、前記並列する層別が陰性と予想する一方、グランドトルース値は陽性と予想している。それ故に、第2の層別値に対する類似度インジケータは"FN"(陰性と予想し、偽であった)である一方、第2の層別値(予想クラス)は、グランドトルース値と同じと予想し、故に "TP"(陽性と予想し、真であった)の類似度インジケータを与える。これは全てのサンプルに対し繰り返される。
【表2】
【0031】
表1及び表2は主に明確にするためであり、例えば100又は200個のサンプルを用いた実施例を表しているのではないことに注意すべきである。
【0032】
ある実施例において、分類は、検査されているシグネチャは誤っている(FN:偽陰性又はFP:偽陽性)、及び並列する層別(本実施例では臨床インデックス)は正しい(TP:真陽性又はTN:真陰性)というこれら誤分類にペナルティが課される臨床予後インデックス(clinical prognostic index)と合っているかを判断される。簡単にするために、本実施例において、この臨床予後インデックスは一定である(臨床データに基づいて一度だけ計算する)と仮定される。関心のある部分は、変化する部分、すなわちシグネチャである。これは一般に、FN及びFPの総数を減少させたい。本実施例において、それ自身は正しくない(例えばサンプル4及び5)が、並列する層別は正しい(例えばサンプル3及び6)シグネチャは、インデックス及び分類子が共に正しくない(例えばサンプル4及び5)予測の組合せよりもさらに重いペナルティの重み付けを割り当てられる。これは、サンプル4及び5のシグネチャは、並列する層別とより一層合致していると結論が出されるからである。それに従って、このようにして、前記並列する層別を追加の情報ソースとして使用することにより、4つのシグネチャ(サンプル3から6を参照)を識別することが可能である。この並列する層別がないときは、これら4つの"FN"シグネチャを識別することは不可能である。
【0033】
ステップ109(S5)において、類似度インジケータは、これらシグネチャの信頼度を決めるとき、入力として使用される。ある実施例において、これら類似度インジケータを入力として使用するステップは、シグネチャの少なくとも1つの組が少なくとも1つの並列する層別の第2の層別値に基づいて、どの位整合されたかを示す整合インジケータを決めることに基づいている。この整合インジケータは、前記少なくとも1つの組のシグネチャの類似度インジケータが前記少なくとも1つの並列する層別の類似度インジケータと一致している一致数を数えることを有する。この一致数はこのとき、シグネチャの信頼度を示す。
【表3】
【0034】
表3は、シグネチャの数が3つ(S1からS3)であり、1つの並列する層別が使用されている複合類似度の例を示す。表3は、各シグネチャがこれらサンプルのうち5つを正確に分類する状況を示す。それ故に、前記並列する層別がないとき、これら3つのシグネチャの識別は不可能である。しかしながら、上述したように、整合インジケータは、シグネチャが正しく分類せず、並列する層別も正しく分類しない場合の数を数えることにより簡単に決められる。シグネチャ1に対し、誤分類のうち2つは並列する層別(サンプル2及び4)と一致し、シグネチャ2に対し、誤分類のうち2つは並列する層別(サンプル4及び5)と一致し、しかしシグネチャ3に対し、誤分類のうち3つは、並列する層別(サンプル2、5及び7)と一致する。この特定の事例において、整合インジケータは、単に"計数"、すなわち並列する層別と一致する数、すなわち"2"、"2"及び"3"である。それ故に、シグネチャ3は、残りのシグネチャよりも信頼性のあるシグネチャとみなされる。
【0035】
これは、数式表現を介してより一般的なやり方で表される。N個のサンプル:S={s1,s2,...sN}及びM個の層別カテゴリー:C={c1,c2,...cM}(例えば侵攻性=c1及び非侵攻性=c2)と仮定する。各サンプルに対し、基準層別値は、
REF={<si,ri>|i=1..N,ri∈C} (1)
分析も各サンプルに層別値を割り当てる、
ANALYSIS={<si,ri1>|i=1..N,ri1∈C} (2)
並列基準も各サンプルに層別値を割り当てる、
PARALLEL={<si,ri2>|i=1..N,ri2∈C} (3)
類似度は基本的に層別の対を得る関数である、
SIMILARITY(<si,ri1>,<si,ri2>) (4)
及び何らかの結果を戻す。
【0036】
例1:
SIMILARITY1(<si,ri1>,<si,ri2>)=カウント(ri1≠ri2)
例2:
SIMILARITY2(<si,ri1>,<si,ri2>)=<カウント(ri1≠ri2)&ri2=cA,カウント(ri1≠ri2)&ri2=>cB
ここでcAは、例えば侵攻性とし、cBは非侵攻性とする。
【0037】
これは、SIMILARITY(ANALYSIS,REF)、SIMILARITY(ANALYSIS,PARALLEL)及びSIMILARITY(ORTHOGONAL,REF)と呼ばれてもよい。信頼度インジケータはこのとき、これら呼び出しからの結果を比較することにより決められる。先行する実施例において、類似度は、SIMILARITY(ANALYSIS,ORTHOGONAL)に基づいている。
【0038】
表3の例は、同時に比較する3つ(又はそれ以上)の層別が比較されている、すなわちMULTI−SIMILARITY(<si,ri1>,<si,ri2>,<si,ri3>,....)であるシナリオを開示し、入力する層別を比較することにより類似度を規定することが可能である。ここで信頼度は実際に、類似度と同じとすることができ、すなわち例としてMULTI-SIMILARITY(ANALYSIS,PARALLEL,REF)と呼ばれてもよい。
【0039】
シグネチャは、より一層"真の値"と一致し、並列する層別と完全に合わないことに注意すべきであることを述べておく。この場合、整合インジケータは単に、データを単に監視している専門家により決められるインジケータである。
【0040】
ある実施例において、新しいシグネチャの組が決められ、整合インジケータを決める前記ステップが繰り返される。これは例えば数百回繰り返されてもよい。前記サンプルの層別が良好である及び並列する層別ソースと整合されることは、後続するステップにおいて、他の評価のために選択される。それに従って、シグネチャを連続して生成することにより、複数回繰り返した後、シグネチャの組をもたらす検索が行われる。並列する層別ソースを使用する質的改善は、並列する層別を用いない同じ方法と比較して、この検索を(複数の)並列する層別及び減少した過剰適合とより一層整合される良好なシグネチャの組に進めることを可能にする。シグネチャ発見の反復性は、"Schaffer, D.,A. Janevski他著、(2005). A Genetic Algorithm Approach for Discovering Diagnostic Patterns in Molecular Measurement Data. Proceedings of the 2005 IEEE Symposium on Computational Intelligence in Bioinformatics and Computational Biology, CIBCB 2005, La Jolla, CA, USA, IEEE"に開示され、参照することにより全て含まれる。
【0041】
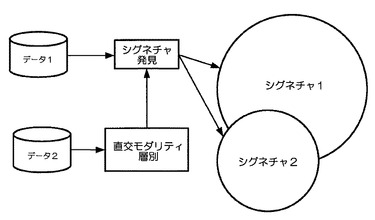
図2は、上記連続的繰り返しの結果を示し、データ1は"核"モダリティ、すなわち高スループット分子測定のデータセットを介して得られる分類子である。このデータだけを分析する結果は、一組のシグネチャ(シグネチャ1)を生み出す。データ2は前記並列する層別データである。この並列する層別を用いてシグネチャ発見を進める場合、他の組のシグネチャが出力(シグネチャ2)として得られる。唯一の要件は、データ1及びデータ2が全く異なるモダリティからのかなり重畳するサンプルの組にあることである。
【0042】
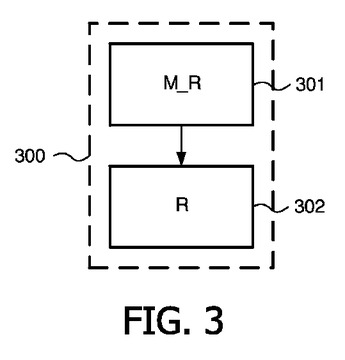
図3は、サンプル群から集められた臨床データから得られるシグネチャの少なくとも1つの組に対する信頼度インジケータを決めるための本発明による装置300を示す。これらシグネチャは、前記サンプル群から臨床データの特徴を検出することにより得られる。さらに、これらシグネチャは、シグネチャに関してサンプル群を層別する層別値の第1の組を生成する。この装置は、前記サンプル群から得られるシグネチャに少なくとも1つの並列する層別を供給するための手段301を有し、この少なくとも1つの並列する層別はこれらシグネチャから独立し、この並列する層別に関して層別値の第2の組を生成する。この装置はさらに、図1における上述した方法ステップを行う処理器301も有する。
【0043】
開示される実施例のある特定の詳細は、本発明の明瞭且つ完全な理解を提供するために、制限ではなく、説明を目的として述べられる。しかしながら、本発明は、本開示の意図及び範囲から大きく外れることなく、ここに述べられた詳細な説明に厳密に従っていない他の実施例で実施されてもよいことは当業者により理解されるべきである。さらに、この文脈において、並びに簡潔さ及び明瞭さを目的に、よく知られた装置、回路及び手法の詳細な説明は、不必要な詳細及び起こり得る混乱を避けるために省略される。
【0044】
請求項に参照符号が含まれているが、これら参照符号を含むことは、単に明瞭さを理由とするものであり、請求項の範囲を制限するとみなすべきではない。
【技術分野】
【0001】
本発明は、サンプル群から集められた臨床データから得られるシグネチャ(signature)の少なくとも1つの組に対する信頼度インジケータを決めるための方法及び装置に関する。前記シグネチャは、前記サンプル群から前記臨床データの特徴を検出することにより得られ、これらシグネチャの各々は、前記サンプル群を層別(stratify)する層別値の第1の組を生成する。
【背景技術】
【0002】
高スループット(high-throughput)分子測定はしばしば、生体試料(サンプル)を層別するのに役立つデータセットにおけるパターンを特定するために、臨床応用の目的で分析される。そのような応用は、例えば患者の特定のカテゴリーの診断シグネチャとして使用されることができる、例えば遺伝子発現データ(gene expression data)からの特徴サブセットの選択である。このような診断シグネチャは、病気の臨床診断、病期分類及び/又は治療の選択(例えばある病気に対する治療レジメントの肯定応答及び否定応答)に用いられてもよい。患者の臨床状態は一般に、上記シグネチャの発見中に分かることに注意されるべきである。この"グランドトルース(ground truth)"は、それからサンプルが得られる臨床研究の一部としてしばしば利用可能である、又は(例えばDNAメチル化、プロテオミクス及びSNPのような)シグネチャの発見に使用される以外の何らかの分子特性を分子測定を用いて検出することにより分かってもよい。診断に用いる、すなわち臨床状態を識別するのに使用されることができるこれら測定値の中からパターンを発見するために、様々な統計及び機械学習アルゴリズムがこのようなデータセットに適用されるのが一般的である。さらに単変量(univariate)シグネチャは、関心のある殆どの病気及び状態に対し発見されるとは考えにくいという認識が生物学者及び臨床医の間で増えていて、前記シグネチャの発見の組合せチャレンジを増やす多変量(multivariate)シグネチャが必要であると信じられている。この領域を悩ませる1つの問題は、前記データセットが測定値は多いが事例は少ないと必ず特徴付けられる、すなわち患者よりもかなり多くの測定値が存在していることである。結果として、パターン発見方法は、偽のパターン、すなわち所与のデータでは上手く予測するが、新しい事例では上手く予測しないパターンを発見する傾向がある。これは、過剰適合(overfitting)とも呼ばれる。低品質である又は臨床問題に関連していなさそうと信じられる幾つかの測定値を処分することにより測定値の数を減少する様々な方法、例えば再サンプリング及び相互検証は、過剰適合を克服するために利用されていたが、これらの方法でも前記問題は完全に克服されることができない。
【発明の概要】
【発明が解決しようとする課題】
【0003】
本発明の目的は、このような過剰適合の問題を克服する改良した方法を提供することである。
【課題を解決するための手段】
【0004】
ある態様によれば、本発明はサンプル群から集められた臨床データから決められるシグネチャの少なくとも1つの組に対する信頼度を決める方法に関し、前記シグネチャは前記サンプル群から前記臨床データの特徴を検出することにより得られ、これらシグネチャの各々は、前記サンプル群を層別する層別値の第1の組を生成する。前記方法は、
前記サンプル群から得られる前記シグネチャに少なくとも1つの追加の及び並列する層別ソース(stratification source)を供給するステップであり、この少なくとも1つの並列する層別ソースは、前記シグネチャから独立し、前記サンプル群に対する層別値の第2の組を生成しているステップ、
各夫々のサンプルに対し、層別値の第1の組を真の基準層別値と、及び層別値の第2の組を真の基準層別値と比較するステップ、
これら第1及び第2の層別値が前記真の基準層別値と一致するかを示す類似度インジケータ(similarity measure indicator)をシグネチャに割り当てるステップ、並びに
前記シグネチャの信頼度を決めるとき、前記類似度インジケータを入力として実行するステップ
を有する。
【0005】
それ故に、シグネチャの"整合(アライメント)"のために、これらシグネチャを特定の並列する層別基準と比較し、それ故に偽のパターンを削除するのに役立つことが可能である。
【0006】
ある実施例において、前記類似度インジケータを入力として実行するステップは、
それらの層別値が前記真の基準層別値と一致しないことを示す類似度インジケータをどのシグネチャが持っているかを特定するステップ、及び
これら特定されたシグネチャに対し、これらシグネチャの層別値が少なくとも1つの並列する層別ソースの層別値とどの位整合しているかを示す整合インジケータを決めるステップであり、この整合インジケータはシグネチャの信頼度を示しているステップ、
を有する。
【0007】
明確にするために、詳細な説明において表1及び表2を参照すると、これはあるシグネチャに対し、このシグネチャが間違って分類したサンプルが真の基準層別値と比較されたことに対して判断される(この場合、偽陰性(FN)又は偽陽性(FP))ことを意味する。この第2のステップは、これらの誤分類を並列する層別ソースと比較すること、すなわち他の"信頼度ステップ"が行われることである。この比較は、これら誤分類の2つが並列する層別ソースと一致していることを示す。表1及び表2は、(誤)分類の全ての起こり得る組合せをリストにすることを主目的とし、例えば100又は200個のサンプルを用いた実施例を表しているのではないことに注意すべきである。
【0008】
ある実施例において、整合インジケータを決める前記ステップは、シグネチャの層別値が少なくとも1つの並列する層別ソースにより生成される層別値とどの位の割合で一致するのかを決めるステップを有し、この数は、シグネチャの信頼度を示している。
【0009】
表3を参照すると、前記実施例は、3つのシグネチャ、つまりシグネチャ1、シグネチャ2及びシグネチャ3から選択する利点を持つ。これは単に明確にするためであり、サンプル数は一般にこれよりも多い実際のシナリオを反映していないことに再度注意すべきである。このシナリオにおいて、全てのシグネチャは、(真の値に比べ)50%しか正しい分類を示さない。この追加の1つ以上の並列する層別値がないとき、これら3つのシグネチャを区別することは不可能である。しかしながら、表を詳しく見ることにより、シグネチャ1に対しては、これら誤分類の2つが並列する層別値と一致し(サンプル2及び4)、シグネチャ2に対しても、これら誤分類の2つが並列する層別値と一致し(サンプル4及び5)、しかしシグネチャ3に対しては、これら誤分類の3つが並列する層別値と一致している(サンプル2、5及び7)。この特定の事例において、整合インジケータは単に"計数"(又はパーセンテージ)、すなわち前記並列基準と一致する数、すなわち"2"、"2"及び"3"である。それ故に、シグネチャ3は、4つの誤分類の3つが前記並列する層別値と一致しているので、残りのシグネチャよりも信頼できるシグネチャであるとみなされる。
【0010】
さらに明確にするために、癌患者を侵攻性(アグレッシブ)又は非侵攻性(ノンアグレッシブ)として層別しようとする、例えば遺伝子発現から得られる2つのシグネチャS1及びS2が存在すると仮定する。このシグネチャ(基本モダリティ、遺伝子発現)を単に使用することにより、両方のシグネチャが例えば4つの誤分類を行っていると言うことだけが可能であり、それ故にシグネチャが臨床的又は生物学的に関連している可能性が高いことに関して確信を持って進めることは不可能である。並列する層別ソース(例えば臨床予後インデックス)は、同じ患者の別々の層別を侵攻性及び非侵攻性にもする。この並列する層別は、S2は、S1と比較した臨床予後インデックスに比べ、多くの誤分類をすることに気付くことを可能にする。これに基づいて、S1は、並列する層別とより合致(in line)しているので、S2よりも"良好な"シグネチャであると結論を下すことができる。それ故に、S1はS2に比べより高い信頼度インデックスを持つ。
【0011】
ある実施例において、並列する層別は、以下の測定値、
臨床情報、
撮像データ、
高スループット分子測定から得られるデータ、又は
この分子測定の生物学的注釈
の1つ以上に基づいている。
【0012】
ある実施例において、前記方法はさらに、前記比較するステップ、前記割り当てるステップ及び前記実行するステップを、既定の基準が満たされるまで連続して繰り返すステップを有する。
【0013】
ある実施例において、既定の基準が満たされるまで前記比較ステップの繰り返しは、1回のステップでシグネチャをランク付けするためであり、どのシグネチャが後続するステップで考慮されるべきかを選ぶための選択基準として、信頼度インジケータを実行することに基づいている。
【0014】
それ故に、この信頼度インジケータのこのような繰り返しの利用を用いることにより、過剰適合の影響は、並列する基準の層別能力に依存して低下又は少なくとも減少する。
【0015】
ある実施例において、既定の基準は、以下の
−固定の繰り返し数、
−所望する整合性能、
−所望する信頼度性能
の少なくとも1つ以上に基づいて、前記繰り返しを終わらせるための1つ以上の基準を含む。
【0016】
これが排他的なリストではないことを注意しておく。
【0017】
他の態様によれば、本発明は、コンピュータプログラムプロダクトがコンピュータ上で実行されるとき、上述した方法のステップを実施するように処理ユニットに命令するためのコンピュータプログラムプロダクトに関する。
【0018】
さらに他の態様によれば、本発明は、サンプル群から集められた臨床データから得られるシグネチャの少なくとも1つの組に対する信頼度インジケータを決めるための装置に関し、これらシグネチャは、これらサンプル群から臨床データの特徴を検出することにより得られ、これらシグネチャの各々は、サンプル群を層別する層別値の第1の組を生成する。前記装置は、少なくとも1つの追加及び並列する層別ソースを前記サンプル群から得られるシグネチャに供給する手段であり、この少なくとも1つの並列する層別ソースは、前記シグネチャから独立し、前記サンプル群に対する層別値の第2の組を生成する手段、
各夫々のサンプルに対し、層別値の第1の組を真の基準層別値と、及び層別値の第2の組を真の基準層別値と比較するための処理器、
前記第1及び第2の層別値が前記真の基準層別値と一致しているかを示す類似度インジケータを前記シグネチャに割り当てるための処理器、並びに
前記シグネチャの信頼度を決めるとき、前記類似度インジケータを入力として実行するための処理器
を有する。
【0019】
本発明のこれら態様は、如何なる他の態様と各々組み合わされてもよい。本発明のこれら及び他の態様は、以下に記載の実施例から明らかあり、これら実施例から説明される。
【図面の簡単な説明】
【0020】
【図1】本発明による方法のフローチャート。
【図2】並列基準をシグネチャ発見処理に加える図。
【図3】本発明による装置。
【発明を実施するための形態】
【0021】
本発明の実施例は、図面を参照して単に例として説明される。
【0022】
図1は、サンプル群から集められた臨床データから得られるシグネチャの少なくとも1つの組に対する信頼度インジケータを決める、本発明による方法のフローチャートを示す。
【0023】
ステップ101(S1)において、これらシグネチャは、前記サンプル群から臨床データの特徴を検出することにより生成される。これらサンプル群は、例として、潜在的な癌患者から集められたサンプルを有し、臨床データは、これらサンプルに行われる高スループット分子測定とすることができる。このようなデータの分析の結果は、シグネチャの組、すなわち癌のこの特定の型に対する特徴であるシグネチャを得る。全てのサンプルを通じて共通する特徴を示す臨床データの如何なる特徴もシグネチャ又は分子シグネチャとも呼ばれる用語で表される。サンプルの組の試験分類を提供するシグネチャを誘導するのに使用される特徴サブセットを発生させる例えば遺伝的アルゴリズム(GA)のような検索方法を用いることにより、上記シグネチャを得る様々な方法が利用されてもよい。さらに、このようなGAに基づいた実験に関する詳細は、"Schaffer, A. Janevski及びM. Simpson著、"A Generic Algorithm Approach for Discovering Diagnostic Patterns in Molecular Measurement Data," presented at Proceedings of the 2005 IEEE Symposium on Computational Intelligence in Bioinformatics and Computational Biology, CIBCB 2005, La Jolla, CA, USA, 2005"に見られ、参照することにより全て含まれる。これらシグネチャは、シグネチャに関してサンプル群を層別する第1の層別値を生成する。これは、サンプル毎に、1つの層別割り当てだけが存在し、ここで各サンプルは"侵攻性"若しくは"非侵攻性"と割り当てられるか、又は"0"若しくは"1"またさらには例えば1から3のような特定のスケールでラベルが付けられることができる。それに従って、100個のサンプルのシグネチャが存在している場合、特定のシグネチャは、これら100個のサンプルの各々に例えば0又は1のような層別値を供給する。
【0024】
上述したように、本発明は、比較的多くの測定に比べサンプルが非常に少ないので、データがそれだけで"良好な"シグネチャを保証するには十分ではないシナリオを扱う。このようなデータの分析は、このデータを上手く特徴付けしたように偶然見える偽のパターンを見つけやすい。後でさらに詳細に説明されるように、これらパターンを追加として特徴付けることにより、"実際の"(より有望な)パターンから偽のパターンを識別することが可能である。
【0025】
ステップ103(S2)において、少なくとも1つの並列する層別ソースが前記サンプル群から供給され、この少なくとも1つの並列する層別ソースは、前記シグネチャから独立し、サンプル群に対する層別値の第2の組を生成する。これは、特徴付けをするための追加のソースが供給されることを意味するが、ここで追加のソースは、別の方法を用いて得られる。それに従って、各夫々のサンプルに対し、前記シグネチャに加え、並列する層別ソースが供給され、この並列する層別ソースは、第2の層別値、例えば"侵攻性"若しくは"非侵攻性"又は"0"若しくは"1"を生成する。これは、サンプル1は、例えばサンプル1を"非侵攻性"と層別する層別値が割り当てられ、及び追加のソースとして、並列する層別ソースが前記サンプルもさらに"非侵攻性"と層別することを意味する。それに従って、あるソースは、臨床データから得られるシグネチャであり、並列する層別ソースは、臨床情報、例えば乳癌に対する予後予測因子(prognostic indices)、例えば以下のNottingham Prognosis Index(Pinder, Elston他2003), National Institutes of Health Consensus (NIH 2001), and the St. Gallen Cosensus Conference (Ciatto, Cecchini他1990)から得られる。このような並列する層別を追加する理由は、シグネチャをこれらの"整合"に対し、特定の並列する層別基準と比較することを可能にするためである。これは後で詳細に説明される。一般に、本発明の目的は、全く異なる方法を用いることにより、同じ種類の層別(例えば侵攻性対非侵攻性)を追求することである。
【0026】
このような並列する層別ソースの他の実施例は、撮像データから得られるソースであり、これは、例えば高スループット分子測定のような"核(core)"の分析に類似する方式でサンプルを層別するような方式で分析される該当する全ての撮像モダリティ(造影剤を使用する又は使用しないMRI、CT)からのデータである。これは一般に、画像の特徴(形状、構造等)を分析し、各画像/サンプルに対するカテゴリー(例えば侵攻性又は非侵攻性)を出力することにより行われる。他の並列する層別ソースは、高スループット分子測定、つまり遺伝子発現データ、DNAメチル化、質量分析プロテオミクスである。このような測定からのデータは、前記サンプルを"核"の高スループット測定に類似して特徴付ける方法で分析される限り、基本的なシグネチャ発見処理をするためにその出力を使用することが可能である。さらに他の並列する層別ソースは、注釈である、つまり高スループット分子測定の特徴は、例えばそれらの生物学的特徴に基づいて特徴付けられることができる。例えば注釈に広く用いられるソースは、遺伝子オントロジー(GO(geneontology.org参照))であり、ここで遺伝子はそれらの分子機能、生物学的処理及び細胞構成要素に対し注釈が付けられる。このような注釈は、例えば分子機能に関して特徴(例えば遺伝子)の組を特徴付けるのにも使用されることができる。このデータの表示(ビュー)は次いで、サンプルを層別するために、上記他の形式と同じ方法で使用されることができる。
【0027】
ステップ105(S3)において、各夫々のサンプルに対し、第1の層別値及び第2の層別値が真の基準層別値と比較される比較ステップが行われる。この真の基準層別値は、データが5年又は10年間フォローアップしている例えば癌患者に関する後ろ向き研究(retrospective study)によるので、"グランドトルース"と考えられ、それ故に癌が再発したかが分かる。それに従って、サンプルに対し、このステップにおいて、サンプルnに対する第1の層別値及び並列する層別ソースに対する第2の層別値(例えば画像データに基づく)は、このグランドトルース値と比較される。
【0028】
ステップ107(S4)において、シグネチャは、前記第1及び第2の層別値が前記真の基準層別値と一致するかを示す類似度インジケータが割り当てられる。例として、サンプルnに対するこの基準層別値(グランドトルース値)は、"侵攻性"であり、第1の層別値及び第2の層別値は夫々、"侵攻性"及び"非侵攻性"であり、類似度インジケータは、"真"及び"偽"又は"真陽性"及び"偽陽性"である。これは、"+"及び"−"とラベル付けられることもできる。これは、n個のサンプル全て、すなわち各夫々のサンプルに対し繰り返され、第1の層別値及び第2の層別値が前記真の基準層別値と比較される。
【表1】
【0029】
表1は、2つの層別"侵攻性"及び"非侵攻性"並びに8個のサンプルを用いて、この方法が最も簡単な形式でどのように実施されるかを説明するための実施例を示す。第1の列はサンプルを示し、第2の列は真の基準層別値"グランドトルース"であり、第3の列は第1の層別値"並列する層別値"であり、及び第4の列は第2の層別値"予想クラス"である。各試験サンプルに対し"真"のクラスを与える場合、誘導されるシグネチャがサンプルのクラスを正確に予想するかが分かる。
【0030】
107(S4)を参照すると、シグネチャに類似度インジケータの割り当てが表2に示される。"TP(true-positive)"は"真陽性"を意味し、"TN(true-negative)"は"真陰性"を意味し、"FP(false-positive)"は"偽陽性"を意味し、"FN(false-negative)"は"偽陰性"を意味する。それに従って、例としてサンプル1に対し、並列する層別に対する類似度インジケータは、真の値がサンプル1は侵攻性であると述べ、並びに第1及び第2の層別値は同じであると予想するので、"TP"である。他方、サンプル2に対し、前記並列する層別が陰性と予想する一方、グランドトルース値は陽性と予想している。それ故に、第2の層別値に対する類似度インジケータは"FN"(陰性と予想し、偽であった)である一方、第2の層別値(予想クラス)は、グランドトルース値と同じと予想し、故に "TP"(陽性と予想し、真であった)の類似度インジケータを与える。これは全てのサンプルに対し繰り返される。
【表2】
【0031】
表1及び表2は主に明確にするためであり、例えば100又は200個のサンプルを用いた実施例を表しているのではないことに注意すべきである。
【0032】
ある実施例において、分類は、検査されているシグネチャは誤っている(FN:偽陰性又はFP:偽陽性)、及び並列する層別(本実施例では臨床インデックス)は正しい(TP:真陽性又はTN:真陰性)というこれら誤分類にペナルティが課される臨床予後インデックス(clinical prognostic index)と合っているかを判断される。簡単にするために、本実施例において、この臨床予後インデックスは一定である(臨床データに基づいて一度だけ計算する)と仮定される。関心のある部分は、変化する部分、すなわちシグネチャである。これは一般に、FN及びFPの総数を減少させたい。本実施例において、それ自身は正しくない(例えばサンプル4及び5)が、並列する層別は正しい(例えばサンプル3及び6)シグネチャは、インデックス及び分類子が共に正しくない(例えばサンプル4及び5)予測の組合せよりもさらに重いペナルティの重み付けを割り当てられる。これは、サンプル4及び5のシグネチャは、並列する層別とより一層合致していると結論が出されるからである。それに従って、このようにして、前記並列する層別を追加の情報ソースとして使用することにより、4つのシグネチャ(サンプル3から6を参照)を識別することが可能である。この並列する層別がないときは、これら4つの"FN"シグネチャを識別することは不可能である。
【0033】
ステップ109(S5)において、類似度インジケータは、これらシグネチャの信頼度を決めるとき、入力として使用される。ある実施例において、これら類似度インジケータを入力として使用するステップは、シグネチャの少なくとも1つの組が少なくとも1つの並列する層別の第2の層別値に基づいて、どの位整合されたかを示す整合インジケータを決めることに基づいている。この整合インジケータは、前記少なくとも1つの組のシグネチャの類似度インジケータが前記少なくとも1つの並列する層別の類似度インジケータと一致している一致数を数えることを有する。この一致数はこのとき、シグネチャの信頼度を示す。
【表3】
【0034】
表3は、シグネチャの数が3つ(S1からS3)であり、1つの並列する層別が使用されている複合類似度の例を示す。表3は、各シグネチャがこれらサンプルのうち5つを正確に分類する状況を示す。それ故に、前記並列する層別がないとき、これら3つのシグネチャの識別は不可能である。しかしながら、上述したように、整合インジケータは、シグネチャが正しく分類せず、並列する層別も正しく分類しない場合の数を数えることにより簡単に決められる。シグネチャ1に対し、誤分類のうち2つは並列する層別(サンプル2及び4)と一致し、シグネチャ2に対し、誤分類のうち2つは並列する層別(サンプル4及び5)と一致し、しかしシグネチャ3に対し、誤分類のうち3つは、並列する層別(サンプル2、5及び7)と一致する。この特定の事例において、整合インジケータは、単に"計数"、すなわち並列する層別と一致する数、すなわち"2"、"2"及び"3"である。それ故に、シグネチャ3は、残りのシグネチャよりも信頼性のあるシグネチャとみなされる。
【0035】
これは、数式表現を介してより一般的なやり方で表される。N個のサンプル:S={s1,s2,...sN}及びM個の層別カテゴリー:C={c1,c2,...cM}(例えば侵攻性=c1及び非侵攻性=c2)と仮定する。各サンプルに対し、基準層別値は、
REF={<si,ri>|i=1..N,ri∈C} (1)
分析も各サンプルに層別値を割り当てる、
ANALYSIS={<si,ri1>|i=1..N,ri1∈C} (2)
並列基準も各サンプルに層別値を割り当てる、
PARALLEL={<si,ri2>|i=1..N,ri2∈C} (3)
類似度は基本的に層別の対を得る関数である、
SIMILARITY(<si,ri1>,<si,ri2>) (4)
及び何らかの結果を戻す。
【0036】
例1:
SIMILARITY1(<si,ri1>,<si,ri2>)=カウント(ri1≠ri2)
例2:
SIMILARITY2(<si,ri1>,<si,ri2>)=<カウント(ri1≠ri2)&ri2=cA,カウント(ri1≠ri2)&ri2=>cB
ここでcAは、例えば侵攻性とし、cBは非侵攻性とする。
【0037】
これは、SIMILARITY(ANALYSIS,REF)、SIMILARITY(ANALYSIS,PARALLEL)及びSIMILARITY(ORTHOGONAL,REF)と呼ばれてもよい。信頼度インジケータはこのとき、これら呼び出しからの結果を比較することにより決められる。先行する実施例において、類似度は、SIMILARITY(ANALYSIS,ORTHOGONAL)に基づいている。
【0038】
表3の例は、同時に比較する3つ(又はそれ以上)の層別が比較されている、すなわちMULTI−SIMILARITY(<si,ri1>,<si,ri2>,<si,ri3>,....)であるシナリオを開示し、入力する層別を比較することにより類似度を規定することが可能である。ここで信頼度は実際に、類似度と同じとすることができ、すなわち例としてMULTI-SIMILARITY(ANALYSIS,PARALLEL,REF)と呼ばれてもよい。
【0039】
シグネチャは、より一層"真の値"と一致し、並列する層別と完全に合わないことに注意すべきであることを述べておく。この場合、整合インジケータは単に、データを単に監視している専門家により決められるインジケータである。
【0040】
ある実施例において、新しいシグネチャの組が決められ、整合インジケータを決める前記ステップが繰り返される。これは例えば数百回繰り返されてもよい。前記サンプルの層別が良好である及び並列する層別ソースと整合されることは、後続するステップにおいて、他の評価のために選択される。それに従って、シグネチャを連続して生成することにより、複数回繰り返した後、シグネチャの組をもたらす検索が行われる。並列する層別ソースを使用する質的改善は、並列する層別を用いない同じ方法と比較して、この検索を(複数の)並列する層別及び減少した過剰適合とより一層整合される良好なシグネチャの組に進めることを可能にする。シグネチャ発見の反復性は、"Schaffer, D.,A. Janevski他著、(2005). A Genetic Algorithm Approach for Discovering Diagnostic Patterns in Molecular Measurement Data. Proceedings of the 2005 IEEE Symposium on Computational Intelligence in Bioinformatics and Computational Biology, CIBCB 2005, La Jolla, CA, USA, IEEE"に開示され、参照することにより全て含まれる。
【0041】
図2は、上記連続的繰り返しの結果を示し、データ1は"核"モダリティ、すなわち高スループット分子測定のデータセットを介して得られる分類子である。このデータだけを分析する結果は、一組のシグネチャ(シグネチャ1)を生み出す。データ2は前記並列する層別データである。この並列する層別を用いてシグネチャ発見を進める場合、他の組のシグネチャが出力(シグネチャ2)として得られる。唯一の要件は、データ1及びデータ2が全く異なるモダリティからのかなり重畳するサンプルの組にあることである。
【0042】
図3は、サンプル群から集められた臨床データから得られるシグネチャの少なくとも1つの組に対する信頼度インジケータを決めるための本発明による装置300を示す。これらシグネチャは、前記サンプル群から臨床データの特徴を検出することにより得られる。さらに、これらシグネチャは、シグネチャに関してサンプル群を層別する層別値の第1の組を生成する。この装置は、前記サンプル群から得られるシグネチャに少なくとも1つの並列する層別を供給するための手段301を有し、この少なくとも1つの並列する層別はこれらシグネチャから独立し、この並列する層別に関して層別値の第2の組を生成する。この装置はさらに、図1における上述した方法ステップを行う処理器301も有する。
【0043】
開示される実施例のある特定の詳細は、本発明の明瞭且つ完全な理解を提供するために、制限ではなく、説明を目的として述べられる。しかしながら、本発明は、本開示の意図及び範囲から大きく外れることなく、ここに述べられた詳細な説明に厳密に従っていない他の実施例で実施されてもよいことは当業者により理解されるべきである。さらに、この文脈において、並びに簡潔さ及び明瞭さを目的に、よく知られた装置、回路及び手法の詳細な説明は、不必要な詳細及び起こり得る混乱を避けるために省略される。
【0044】
請求項に参照符号が含まれているが、これら参照符号を含むことは、単に明瞭さを理由とするものであり、請求項の範囲を制限するとみなすべきではない。
【特許請求の範囲】
【請求項1】
サンプル群から集められた臨床データから決められるシグネチャの少なくとも1つの組に対する信頼度インジケータを決める方法であり、前記シグネチャは前記サンプル群から前記臨床データの特徴を検出することにより得られ、前記シグネチャの各々は、前記サンプル群を層別する層別値の第1の組を生成する方法において、
前記サンプル群から得られる前記シグネチャに少なくとも1つの追加の及び並列する層別ソースを供給するステップであり、前記少なくとも1つの並列する層別ソースは、前記シグネチャから独立し、前記サンプル群に対する層別値の第2の組を生成するステップ、
各夫々のサンプルに対し、前記層別値の第1の組を真の基準層別値と、及び前記第2の層別値を真の基準層別値と比較するステップ、
前記第1及び第2の層別値が前記真の基準層別値と一致するかを示す類似度インジケータを前記シグネチャに割り当てるステップ、並びに
前記シグネチャの信頼度を決めるとき、前記類似度インジケータを入力として実行するステップ
を有する方法。
【請求項2】
前記類似度インジケータを入力として実行する前記ステップは、
前記第1及び第2の層別値が前記真の基準層別値と一致しないことを示す類似度インジケータをどの前記シグネチャが持っているかを特定するステップ、
前記特定されたシグネチャに対し、前記シグネチャの層別値が少なくとも1つの並列する層別ソースの層別値とどの位整合しているかを示す整合インジケータを決めるステップであり、前記整合インジケータは前記シグネチャの信頼度を示しているステップ、
を有する請求項1に記載の方法。
【請求項3】
前記整合インジケータを決める前記ステップは、前記シグネチャの層別値が少なくとも1つの並列する層別ソースにより生成される前記層別値とどの位の割合で一致するのかを決めるステップを有し、この数は前記シグネチャの信頼度を示しているステップ
を有する請求項2に記載の方法。
【請求項4】
並列する層別は、以下の測定値
臨床情報、
撮像データ、
高スループット分子測定から得られるデータ、又は
前記分子測定の生物学的注釈
の1つ以上に基づいている、請求項1に記載の方法。
【請求項5】
シグネチャの組を生成する前記ステップ、並びに前記比較するステップ、前記割り当てるステップ及び前記実行するステップを、既定の基準が満たされるまで連続して繰り返すステップをさらに有する請求項1又は2に記載の方法。
【請求項6】
既定の基準が満たされるまで前記比較ステップの繰り返しは、1回のステップでシグネチャをランク付けするためであり、どのシグネチャが後続するステップで考慮されるべきかを選ぶための選択基準として、前記信頼度インジケータを実行することに基づいている、請求項5に記載の方法。
【請求項7】
前記既定の基準は、以下の
−固定の繰り返し数、
−所望する整合性能、
−所望する信頼度性能
の少なくとも1つ以上に基づいて、前記繰り返しを終わらせるための1つ以上の基準を含む請求項2又は5に記載の方法。
【請求項8】
コンピュータプログラムプロダクトがコンピュータ上で実行されるとき、請求項1に記載の方法ステップを実施するように処理ユニットに命令するためのコンピュータプログラムプロダクト。
【請求項9】
サンプル群から集められた臨床データから決められるシグネチャの少なくとも1つの組に対する信頼度インジケータを決めるための装置であり、前記シグネチャは、前記サンプル群から前記臨床データの特徴を検出することにより得られ、前記シグネチャの各々は、前記サンプル群を層別する層別値の第1の組を生成する装置において、
少なくとも1つの追加の及び並列する層別ソースを前記サンプル群から得られる前記シグネチャに供給する手段であり、前記少なくとも1つの並列する層別ソースは、前記シグネチャから独立し、前記サンプル群に対する層別値の第2の組を生成する手段、
各夫々のサンプルに対し、前記層別値の第1の組を真の基準層別値と、及び前記層別値の第2の組を真の基準層別値と比較するための処理器、
前記第1及び第2の層別値が前記真の基準層別値と一致しているかを示す類似度インジケータを前記シグネチャに割り当てるための処理器、並びに
前記シグネチャの信頼度を決めるとき、前記類似度インジケータを入力として実行するための処理器
を有する装置。
【請求項1】
サンプル群から集められた臨床データから決められるシグネチャの少なくとも1つの組に対する信頼度インジケータを決める方法であり、前記シグネチャは前記サンプル群から前記臨床データの特徴を検出することにより得られ、前記シグネチャの各々は、前記サンプル群を層別する層別値の第1の組を生成する方法において、
前記サンプル群から得られる前記シグネチャに少なくとも1つの追加の及び並列する層別ソースを供給するステップであり、前記少なくとも1つの並列する層別ソースは、前記シグネチャから独立し、前記サンプル群に対する層別値の第2の組を生成するステップ、
各夫々のサンプルに対し、前記層別値の第1の組を真の基準層別値と、及び前記第2の層別値を真の基準層別値と比較するステップ、
前記第1及び第2の層別値が前記真の基準層別値と一致するかを示す類似度インジケータを前記シグネチャに割り当てるステップ、並びに
前記シグネチャの信頼度を決めるとき、前記類似度インジケータを入力として実行するステップ
を有する方法。
【請求項2】
前記類似度インジケータを入力として実行する前記ステップは、
前記第1及び第2の層別値が前記真の基準層別値と一致しないことを示す類似度インジケータをどの前記シグネチャが持っているかを特定するステップ、
前記特定されたシグネチャに対し、前記シグネチャの層別値が少なくとも1つの並列する層別ソースの層別値とどの位整合しているかを示す整合インジケータを決めるステップであり、前記整合インジケータは前記シグネチャの信頼度を示しているステップ、
を有する請求項1に記載の方法。
【請求項3】
前記整合インジケータを決める前記ステップは、前記シグネチャの層別値が少なくとも1つの並列する層別ソースにより生成される前記層別値とどの位の割合で一致するのかを決めるステップを有し、この数は前記シグネチャの信頼度を示しているステップ
を有する請求項2に記載の方法。
【請求項4】
並列する層別は、以下の測定値
臨床情報、
撮像データ、
高スループット分子測定から得られるデータ、又は
前記分子測定の生物学的注釈
の1つ以上に基づいている、請求項1に記載の方法。
【請求項5】
シグネチャの組を生成する前記ステップ、並びに前記比較するステップ、前記割り当てるステップ及び前記実行するステップを、既定の基準が満たされるまで連続して繰り返すステップをさらに有する請求項1又は2に記載の方法。
【請求項6】
既定の基準が満たされるまで前記比較ステップの繰り返しは、1回のステップでシグネチャをランク付けするためであり、どのシグネチャが後続するステップで考慮されるべきかを選ぶための選択基準として、前記信頼度インジケータを実行することに基づいている、請求項5に記載の方法。
【請求項7】
前記既定の基準は、以下の
−固定の繰り返し数、
−所望する整合性能、
−所望する信頼度性能
の少なくとも1つ以上に基づいて、前記繰り返しを終わらせるための1つ以上の基準を含む請求項2又は5に記載の方法。
【請求項8】
コンピュータプログラムプロダクトがコンピュータ上で実行されるとき、請求項1に記載の方法ステップを実施するように処理ユニットに命令するためのコンピュータプログラムプロダクト。
【請求項9】
サンプル群から集められた臨床データから決められるシグネチャの少なくとも1つの組に対する信頼度インジケータを決めるための装置であり、前記シグネチャは、前記サンプル群から前記臨床データの特徴を検出することにより得られ、前記シグネチャの各々は、前記サンプル群を層別する層別値の第1の組を生成する装置において、
少なくとも1つの追加の及び並列する層別ソースを前記サンプル群から得られる前記シグネチャに供給する手段であり、前記少なくとも1つの並列する層別ソースは、前記シグネチャから独立し、前記サンプル群に対する層別値の第2の組を生成する手段、
各夫々のサンプルに対し、前記層別値の第1の組を真の基準層別値と、及び前記層別値の第2の組を真の基準層別値と比較するための処理器、
前記第1及び第2の層別値が前記真の基準層別値と一致しているかを示す類似度インジケータを前記シグネチャに割り当てるための処理器、並びに
前記シグネチャの信頼度を決めるとき、前記類似度インジケータを入力として実行するための処理器
を有する装置。
【図1】

【図2】
【図3】
【図2】
【図3】
【公表番号】特表2012−504761(P2012−504761A)
【公表日】平成24年2月23日(2012.2.23)
【国際特許分類】
【出願番号】特願2011−529655(P2011−529655)
【出願日】平成21年9月24日(2009.9.24)
【国際出願番号】PCT/IB2009/054176
【国際公開番号】WO2010/038173
【国際公開日】平成22年4月8日(2010.4.8)
【出願人】(590000248)コーニンクレッカ フィリップス エレクトロニクス エヌ ヴィ (12,071)
【Fターム(参考)】
【公表日】平成24年2月23日(2012.2.23)
【国際特許分類】
【出願日】平成21年9月24日(2009.9.24)
【国際出願番号】PCT/IB2009/054176
【国際公開番号】WO2010/038173
【国際公開日】平成22年4月8日(2010.4.8)
【出願人】(590000248)コーニンクレッカ フィリップス エレクトロニクス エヌ ヴィ (12,071)
【Fターム(参考)】
[ Back to top ]