
グーグル インコーポレイテッドにより出願された特許
51 - 60 / 161
視覚クエリの複数の領域についての検索結果を提示するためのユーザインターフェイス
写真、スクリーンショット、スキャン画像、映像フレームなどの視覚クエリを、クライアントシステムから視覚クエリ検索システムにサブミットする。その検索システムは、それぞれが互いに異なる視覚クエリ検索処理を実施する複数の並列検索システムに、その視覚クエリを送ることによりその視覚クエリを処理する。並列検索システムから複数の結果を受け取る。その検索結果を利用して対話型結果ドキュメントを作成し、クライアントシステムに送る。対話型結果ドキュメントは、視覚クエリの副部分に関する少なくとも1つの検索結果への選択可能リンクを有する、その視覚クエリの副部分に関する少なくとも1つの視覚的識別子を有する。視覚的識別子は、それぞれの副部分を取り囲む境界ボックスとすることも、それぞれの副部分上の半透明ラベルとすることもできる。場合により、境界ボックスまたはラベルを結果の種類ごとに色分けしてもよい。 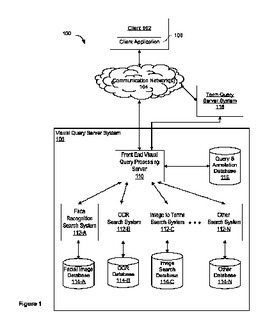 (もっと読む)
(もっと読む)
ソーシャルネットワークの支援による顔認識
顔認識検索システムが、クエリ内の1つまたは複数の顔画像に対応する、1つまたは複数の適当な名前(または他の個人識別子)を以下のように特定する。1つまたは複数の顔画像を有する視覚クエリを受け取った後、このシステムは、視覚的類似性基準に応じてそれぞれの顔画像に潜在的に一致する画像を特定する。次いで、それらの潜在的な画像に関連する1人または複数の人物を特定する。特定した人物ごとに、通信アプリケーション、ソーシャルネットワーキングアプリケーション、カレンダアプリケーション、共同アプリケーションなど、複数のアプリケーションから、要求者に対する社会的なつながりについてのメトリクスを含む人物固有データを取得する。次いで、少なくともそれぞれの顔画像と潜在的な画像の一致との間の視覚的類似性のメトリクスに応じて、および社会的つながりメトリクスに応じて特定した人物をランク付けすることにより、順序付き人物一覧を生成する。最後に、その一覧からの少なくとも1つの人物識別子を要求者に送る。  (もっと読む)
(もっと読む)
広告の質に対するエンドユーザーの知覚に影響を与える要因、例えばドキュメントパフォーマンス、を用いた広告カウント数及び/又は広告ブランディングの調整又は決定

【課題】自己のブランドイメージを保護し、エンドユーザーによって知覚される広告の質を高める高品質な広告引き渡しシステムを提供する。
【解決手段】広告がドキュメント(又はドキュメントの組に属するドキュメント)とともに提供されたときの行動、例えば選択、の価値を反映させるためにドキュメント又はドキュメントの組に点数を付ける。次に、ドキュメントとともに提供される広告数、及び/又は前記広告に対して提供されるブランディングの型又はレベルを、前記点数を用いて制御する。ドキュメント点数は、前記広告提供システムが自己のブランドの品質を維持及び制御するのに役立つ。さらに、提供される広告数、及び/又は前記広告に対して提供されるブランディングの型又はレベルは、広告の質に対するエンドユーザーの知覚に影響を与える可能性があるその他の要因を用いて制御することが可能である。
(もっと読む)
階層アーキテクチャ内の結果最適化のための生産的分散

プロデューサノード(122)は、階層型のツリー形状の処理アーキテクチャ(102)に含まれてもよく、該アーキテクチャは、プロデューサノード(126)及びプロデューサノード(122、126、129)の事前定義済みのサブセット内の少なくとも1つの他のプロデューサノード(126)への分散を含むアーキテクチャ(102)内でクエリ(106)を分散するように構成される少なくとも1つのディストリビュータノード(120)を含む。ディストリビュータノード(120)は、プロデューサノード(122)からの結果、及び少なくとも1つの他のプロデューサノード(126)からの結果を受信し、コンパイル済みの結果(108)をそこから出力するようにさらに構成されてもよい。プロデューサノード(102)は、プロデューサノード(120)に関連付けられているプロデューサインデックスの検索に適合するクエリ特徴(402-406)を使用してクエリ表現を取得し、それによりプロデューサノード(122)から結果を取得するためにディストリビュータノード(120)から受信されるクエリ(106)を処理するように構成されるクエリプリプロセッサ(134)と、クエリ表現を入力して、それに基づいて、プロデューサノード(122、126、129)の事前定義済みのサブセット内の少なくとも1つの他のプロデューサノード(126)によるクエリ(106)の処理により、少なくとも1つの他のプロデューサノードの結果がコンパイル済みの結果(108)内に含まれるようになるかどうかについての予測を出力するように構成されるクエリ分類器(142)とを含むことができる。 (もっと読む)
ターゲットページとは異なる文字セットおよび/または言語で書かれたクエリを使用する検索のためのシステムおよび方法
【課題】曖昧な検索クエリに応じて、適切な検索結果を提供する方法および装置を提供すること。
【解決手段】本発明と合致する方法および装置により、ユーザは、曖昧な検索クエリを提出し、適切な検索結果を受け取ることが可能である。クエリは、検索されるデータの少なくとも一部の文字セットおよび/または言語とは異なる文字セットおよび/または言語を使用して表され得る。これらの文字セットおよび/または言語の間の変換は、連係されたテキストにおいて、言葉の使用を検証することによって実行され得る。確率は、それぞれの可能な変更に関連付けられ得る。改良は、検索結果を用いて、ユーザの相互作用を検証することによって、これらの確率に対してなされ得る。
(もっと読む)
アカウント回復技術
コンピュータシステム、方法、およびコンピュータシステムとともに使用するためのコンピュータプログラム製品(例えば、ソフトウェア)の実施形態を説明する。これらの実施形態は、オンラインアカウントの制御を取り戻すためのユーザ要求を評価するために使用されてもよい。例えば、ユーザ要求は、ウェブページを使用してオンラインで提出されてもよく、オンラインアカウントに関連する最近のアクティビティの履歴等の、ユーザの身元を確立する、またはユーザがオンラインアカウントの所有者であることを実証する情報を含んでもよい。この情報は、最近のアクティビティの記憶された履歴、または登録ユーザが以前にオンラインアカウントにアクセスした時の登録ユーザの1つ以上の場所等の、オンラインアカウントに関連する記憶された情報と比較することによって、評価されてもよい。ユーザ要求を評価した後に、是正措置が行われてもよい。  (もっと読む)
(もっと読む)
携帯電話等のコール機能を有するデバイスに関する広告
【課題】携帯電話等のコール機能を有するデバイスに広告を提供する。
【解決手段】1つ以上の広告をユーザーデバイスに提供するにあたり、ユーザーデバイスの特徴、例えば、ユーザーデバイスが電話のコールをサポートするかどうかを考慮する。電話のコールをサポートするユーザデバイスに対する広告は、コール・オン・セレクト機能を含むことができる。(例えばボタンのクリックを通じて)広告が選択されたときには、ドキュメント(ウェブページ、等)を提供するためにローディングする代わりに、広告主によって前記広告と関連づけられた電話番号に自動的に電話することができる。
(もっと読む)
デジタル写真のコレクションからのランドマーク
デジタル画像におけるランドマークの自動検出と、それらの画像の注釈とのための方法およびシステムが開示される。デジタル画像においてランドマークを検出し、かつ注釈を付けるための方法は、タグを付けられたランドマークの画像のセットを生成するために、複数のテキストに関連付けられたデジタル画像における1つ以上の画像にランドマークを説明するタグを自動的に割り当てるステップと、タグを付けられたランドマークの画像のセットからのランドマークに対して出現モデルを記憶するステップと、出現モデルを用いて新しい画像においてランドマークを検出するステップとを含む。方法はまた、ランドマークを説明するタグを用いて新しい画像に注釈を付けるステップを含み得る。 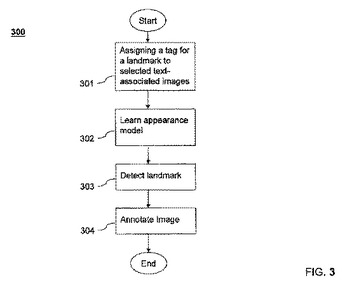 (もっと読む)
(もっと読む)
ストレージクラスタを指定可能な複製されたコンテンツのための非同期的分散オブジェクトアップロード
方法は、2つ以上の装置によって実行される。方法は、同じ固有のテンポラリ識別子を有し、アップロードされるオブジェクトを含むチャンクの組を、2つ以上の装置において受信するステップと、2つ以上の装置の各々において複製されたインデックスにおいて、固有のテンポラリ識別子によって鍵付けされた、オブジェクトに対するエントリを、2つ以上の装置にて作成するステップと、チャンクの組の集合は、オブジェクトの全てのデータを含むことを、2つ以上の装置のうちの開始装置によって判定するステップを含む。方法は、オブジェクトに対するコンテンツベース識別子を演算するステップと、コンテンツベース識別子によって鍵付けされた、オブジェクトに対する別のエントリを、複製されたインデックスにおいて作成するステップと、固有のテンポラリ識別子からコンテンツベース識別子へ指し示すように、複製されたインデックスを更新するステップもを含む。  (もっと読む)
(もっと読む)
ビデオ圧縮方法
【課題】適応性のある方法で離散コサイン変換を実行できるビデオ圧縮方法及びコーデックを提供する。
【解決手段】方法は、各ブロックのピクセルを係数に変換し、これらの係数の最適な送信順序を作成する。データビットストリームを区画して各パーティションを独立に符号化することにより、圧縮ビデオデータの処理速度を最適化する。また、各所与のブロックに関連した少なくとも1つのメトリックに応じて、各所与の複数のピクセル又はピクセルブロックの補間方法を選択することにより端数ピクセル動きを予測し、ブロックごとに方法を変える。さらに、現在のフレームの直前のフレームよりも前のフレームを、データ送信中の品質損失を小さくするための唯一の基準フレームとして使用して、現在のフレームのエラー回復を高度化する。
(もっと読む)
51 - 60 / 161
[ Back to top ]