
ヴォコレクト・インコーポレーテッドにより出願された特許
1 - 7 / 7
離脱式電気コネクター
周辺デバイス16のコード18に対してターミナルを電気的に接続するための電気コネクター12であって、電気コネクター12は、プラグ部材20と、このプラグ部材20に対して回動可能に取り付けられたレバーアーム40と、付勢部材44とを含む。プラグ部材20およびレバーアーム40はそれぞれ、ターミナルの相補的面と係合するよう構成された係合爪36,38を含み、かつ、付勢部材44は、係合爪36,38をターミナルの相補的表面に対して近接させるためにレバーアーム40に付勢力を加える。レバーアーム40は、有利なことには、ターミナルからプラグ部材20を取り外すためにユーザーが付勢力に抗して解除力を加えるための輪郭取りされた凹状プロファイル48を備えた第1の把持面52を含む。第2の面72は、ユーザーの指と係合しかつグリップバンプ77を形成するための凹状面74,76を含む。  (もっと読む)
(もっと読む)
音声認識システムにモデルを適合させるための方法およびシステム
システムに入力された語の筆記録を使用せずに、音声認識システムによって発生する、考えられる誤りを識別するための方法が開示される。音声認識システムに対するモデル適合の方法は、システムに入力された語の筆記録を使用せずに、1つの語の事象の認識または様々な語の事象の認識に対応する誤り率を決定する段階315を含む。方法は、誤り率に基づいて、1つの語に対する1つのモデルまたは様々な語に対する様々なモデルの適合を調整する段階320をさらに含みうる。システムに入力された語の筆記録を使用せずに、音声認識システムによって発生する、考えられる誤りを識別するための装置が開示される。音声認識システムに対するモデル適合の装置は、システムに入力された語の筆記録を使用せずに、1つの語の事象の認識または様々な語の事象の認識に対応する誤り率を推定するように適合された、プロセッサ210を含む。装置は、誤り率に基づいて、1つの語に対するモデル235および様々な語に対する様々なモデルの適合を調整するように適合されたコントローラ225をさらに含みうる。  (もっと読む)
(もっと読む)
音声認識システムのパフォーマンスを評価および改善するための方法およびシステム
音声認識システムのパフォーマンスを評価する方法は、1組の語のうちの1つの語の事例の認識または様々な語の事例の認識のいずれかに対応する、等級315、320を決定する段階を含むことが可能であり、等級はシステムのパフォーマンスのレベルを表示し、等級は認識率および少なくとも1つの認識計数に基づく。音声認識システムのパフォーマンスを評価するための装置は、1組の語のうちの1つの語の事例の認識または様々な語の事例の認識のいずれかに対応する、等級を決定するプロセッサ224を含むことが可能であり、等級はシステムのパフォーマンスのレベルを表示し、等級は認識率および少なくとも1つの認識計数に基づく。  (もっと読む)
(もっと読む)
音声認識システムに対するモデル適合を最適化するための方法およびシステム
音声認識システムのリソースの効率的な使用のための方法は、1組の語のうちの1つの語の事例の認識または様々な語の事例の認識に対応する認識率を決定する段階315と、認識率の精度範囲を決定する段階320とを含む。方法は、精度範囲内の少なくとも1つの値と認識率のしきい値との比較に基づいて、1つの語に対する1つのモデルの適合または様々な語に対する様々なモデルの適合を調整する段階325、330をさらに含みうる。音声認識システムのリソースの効率的な使用のための装置は、1組の語のうちの1つの語の事例の認識または様々な語の事例の認識に対応する認識率と認識率の精度範囲とを決定するように適合されたプロセッサ210を含む。装置は、精度範囲内の少なくとも1つの値と認識率のしきい値との比較に基づいて、1つの語に対する1つのモデルまたは様々な語に対する様々なモデルの適合235を調整するように適合されたコントローラ225をさらに含む。  (もっと読む)
(もっと読む)
音声認識環境において用いるための無線ヘッドセット
装置(10、20)と通信するためのヘッドセット(16)は、ユーザの音声を検出するためにヘッドセット(16)によって取得されたオーディオ信号を処理し、概して、ユーザの音声が検出された場合にのみ、取得されたオーディオ信号のサンプリングされた表示を装置(10、20)に送信するよう構成されている。 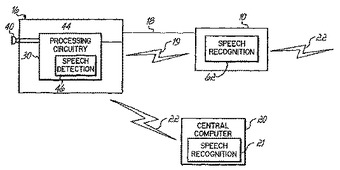 (もっと読む)
(もっと読む)
ユーザの音声を検出するための装置及び方法
ユーザの音声を検出するための装置は、各々がそれぞれの信号特性を有する音信号を発生するよう動作可能な第1のマイクロフォン70及び少なくとも1つの第2のマイクロフォン72を備える。第1のマイクロフォン70は、第2のマイクロフォン72よりもユーザの音声音の一層大きい割合を取得するよう動作可能である。処理回路30は、ユーザが喋っているかどうかを決定するためにそれらの信号特性における変動を決定するよう第1のマイクロフォン70及び第2のマイクロフォン72によって発生される音信号の信号特性を処理する。  (もっと読む)
(もっと読む)
マルチモーダルソフトウェアにおける知的なプロンプト制御のための方法、及びシステム
マルチモーダルデータ収集装置入力、または音声認識入力を、発話出力機能と統合するための対話マネージャ、及び方法。作業フローの記述(208)がグラフィカルユーザインタフェース(86)の対象物から抽出されると共に、マルチモーダルユーザインタフェース(204)が定義される。作業フローの記述(208)に従って、対話エンジン(254)は、入出力装置(264)とアプリケーション(204)との間の情報の流れを同期させる。複数の周辺装置(266-274)によって出力されるデータを入力するためのプロンプトは、周辺装置(266-274)の入力状態に基づき、対話エンジン(254)によって、知的な方法で制御される。バージイン、プロンプトホールドオフ、プライオリティプロンプト、及びトークアヘッドのような機能が提供される。 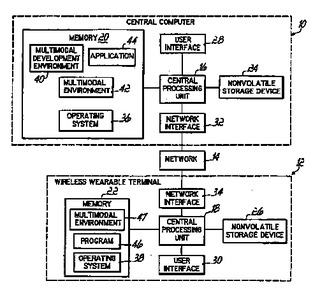 (もっと読む)
(もっと読む)
1 - 7 / 7
[ Back to top ]