
Fターム[5B056EE05]の内容
Fターム[5B056EE05]の下位に属するFターム
ベクトル演算とスカラ演算間 (1)
ベクトル演算相互間 (6)
Fターム[5B056EE05]に分類される特許
1 - 10 / 10
ベクトル演算装置及びベクトル演算方法
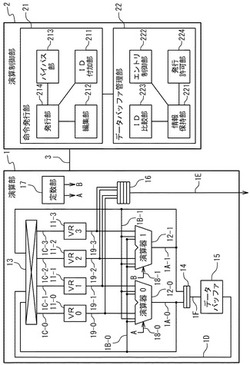
【課題】ハードウェア量の増大やレジスタ制御の複雑さを抑制しつつ、システム性能を向上可能なベクトル演算装置を提供する。
【解決手段】ベクトル演算装置は、レジスタ、レジスタのデータを用いベクトル演算する演算器、及び演算結果データを格納可能なデータバッファを備える演算部と、演算部へベクトル演算命令を発する命令発行部及びデータバッファ管理情報を保持するデータバッファ管理部を備える演算制御部とを具備する。命令発行部は、同一レジスタでの複数の命令の依存関係に基づき、第1命令と第2命令とが順番変更可能な場合、演算結果データをデータバッファに格納するよう第2命令を編集する。データバッファ管理部は、第2命令に基づいて、データバッファの出力先レジスタ及び第1命令の情報を管理情報に格納する。演算器は、第2命令に基づき、ベクトル演算して演算結果データを出力する。データバッファは、演算結果データを格納する。
(もっと読む)
ベクトル命令間追い越し判定装置と方法

【課題】ハードウェア量の増大を抑止しながら、命令間の追い越し数を増やし、メモリネットワークの効率化を実現するベクトル命令間追い越し判定装置と方法の提供。
【解決手段】アドレス比較部(2)を複数のベクトルストア命令に対して共通に1つ備え、アドレス比較部(2)では、複数のベクトルストア命令と後続のベクトルロード命令のアドレスの依存関係のチェックを時分割で行い、ベクトル命令のアドレス、ディスタンス、要素数情報からメモリアクセス要素に展開する要素展開部(4)における展開処理と、
アドレス比較部(2)での複数のベクトルストア命令と後続のベクトルロード命令のアドレス比較処理とが並行して実行可能とされる。
(もっと読む)
逆行列演算回路及び逆行列演算方法
【課題】アレーアンテナの相関行列を求める際に、高速かつ小さな回路規模で逆行列を演算し得る逆行列演算回路を提供する。
【解決手段】各ステップ演算部110〜140間で行入れ替え操作を共通とし、パイプライン処理を可能な構成とした。また、各ステップ演算部110〜140内の逆数演算部において、複素数による逆数計算を不要とし、実数による逆数計算を行うようにした。
(もっと読む)
連立一次方程式の並列求解装置
【課題】連立一次方程式の解を高速に求めることが可能な連立一次方程式の並列求解装置を得ること。
【解決手段】この発明の連立一次方程式の並列求解装置によれば、行単位に並列処理する方法を採用し、LU分解では、各要素の実行可否を当該要素の処理フラグの設定、確認により制御し、また、前進消去、後退代入の処理では、当該CPUで計算した解について、後段のCPUで処理する計算項目も当該CPUで計算して後段のCPUにデータを受渡し、また、各要素の実行可否を当該要素の処理フラグの設定、確認により、制御することにより、各CPUの演算量を減少させ、各CPUの演算量のバランスを図ることにより、並列処理の効率性を向上させて、連立一次方程式を高速に求解できるようにした。
(もっと読む)
並列演算方法、演算装置、および演算装置用プログラム
【課題】本発明は、通信回数を増やすことなく、演算装置間のネットワークの通信路の数を少なくすることを目的とする。
【解決手段】本発明の並列演算方法は、N個の演算装置がバラバラに記録しているK次元のベクトルの和を、リング状のネットワークを利用して計算し、結果をN個の演算装置で共有する。具体的には、K個の成分をN個のグループに分け、各演算装置は、1つのグループの成分を隣の演算装置に渡す。受け取った演算装置は自分が保有する当該グループの成分との和を求め、その結果を次の演算装置に渡す。この作業をN−1回行い、N回目からは受け取った演算装置は、当該グループの成分の和として記録すると共に、そのデータを次の演算装置に渡す。この作業を2N−2回目まで行う。
(もっと読む)
シストリックアレイ
【課題】演算する行列サイズが可変とし負荷を均一化し、入出力データを蓄積するメモリを減らすMFA1次元シストリックアレイの提供。
【解決手段】MFA(修正Faddeevaアルゴリズム)を利用した行列演算用シストリックアレイであって、下方向正方MFAアレイ処理と、上方向正方MFAアレイ処理を1次元アレイに水平方向にマッピングし、1次元アレイの各PEでは、下方向と上方向の二つのスレッドのMFA行列演算が行われ、入出力を一次元アレイ両端のPEに対して備えている。
(もっと読む)
ベクトル命令管理回路、ベクトル処理装置、ベクトル命令管理方法、ベクトル処理方法、ベクトル命令管理プログラム、および、ベクトル処理プログラム
【課題】 物理ベクトルレジスタのリソース不足を抑止する。
【解決手段】 リネーミング判定手段102は、ベクトル書き込み命令(後続ベクトル命令)を入力すると、実行中ベクトルレジスタ番号テーブル103を参照し、同一論理ベクトルレジスタに書き込みを行う実行中のベクトル書き込み命令(先行ベクトル命令)が存在するかどうか判定し、同一論理ベクトルレジスタに書き込みを行う1以上の先行ベクトル命令が存在すると、後続ベクトル命令のマスクフラグを判定する。後続ベクトル命令のマスクフラグが有効を示しているか、または、後続ベクトル命令のベクトル長≦最新先行ベクトル命令のベクトル長であると、ベクトルレジスタリネーミング手段104は、後続ベクトル命令の論理ベクトルレジスタ番号に対し最新先行ベクトル命令に割り付けられたものと同一の物理ベクトルレジスタ番号を割り付ける。
(もっと読む)
ベクトル演算装置および方法
【課題】 ベクトル演算装置で、複数の同種演算の計算式を1つの計算式として高速に処理ができるようにする。
【解決手段】 複数のベクトルパイプでは、複数のベクトル演算がそれぞれ並列に処理され、ベクトルパイプが有するベクトルレジスタは、ベクトル演算対象となるデータが一時蓄積されると共に、当該データに基づくベクトル演算結果が一時蓄積され、データ転送部は、ベクトル演算対象となるデータをメモリからベクトルレジスタに複写転送すると共に、ベクトル演算結果をベクトルレジスタからメモリに複写転送し、このデータ転送部がアクセスするメモリの領域を指定する際に、ベクトルパイプ毎にメモリの指定領域が異なるようにする。また、ベクトル演算器による演算の際に用いるベクトルの要素数がベクトルパイプ毎に異なるようにする。
(もっと読む)
最適値を求めるためのコンピュータシステム
【課題】
本発明は,従来に比べ高速に最適値を求めるためのコンピュータシステムを提供することを目的とする。
【解決手段】
本発明は,基本的には,初期試行値を複数発生させ,それらに関して別々のコンピュータを用いて並列的に関数の勾配の計算を実行させ,いずれかのコンピュータでの計算が終了するごとに計算結果から新たな試行値を発生させ,新規試行値に関しての勾配の計算を実行させることを繰り返すことで,関数の極値を見つける最適化の高速化を可能にする。従って,ある一つの試行値での勾配を計算させ,その計算結果からへシアンを更新して新たな試行値を発生させ,新規試行値に関しての勾配の計算を実行させることを逐次的に繰り返す,従来のシステムとは異なる。
(もっと読む)
プロセッサ
【課題】 クォータニオン積を1命令により実行するSIMD型プロセッサを提供する。
【解決手段】 2つの四次元ベクトルを読出しオペランドとするクォータニオン積命令において、レジスタファイル140から読み出された一方の四次元ベクトルに対してデータ操作回路170は各要素の並び替えおよび符号反転を施す。繰返し制御回路150はクォータニオン積命令において指定されたサイズに応じて積和演算を演算器180に繰返し実行させる。サイズ処理回路161および162は、指定されたサイズ(要素数)を超える要素に対してゼロを設定する。指定されたサイズが値"4"であればクォータニオン積が算出され、指定されたサイズが値"3"であれば外積が算出される。
(もっと読む)
1 - 10 / 10
[ Back to top ]