
Fターム[5B091EA24]の内容
Fターム[5B091EA24]に分類される特許
1 - 20 / 63
機械翻訳装置、および機械翻訳方法
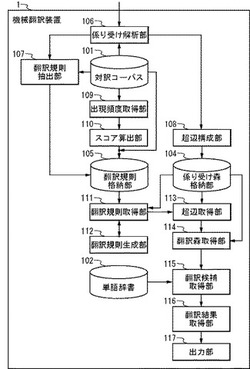
【課題】従来、精度の高い機械翻訳ができなかった。
【解決手段】係り受け森を構成する各頂点に対して、1以上の各翻訳規則を適用し、頂点ごとに、合致する1以上の翻訳規則を取得する翻訳規則取得部と、係り受け森を構成する各頂点をヘッドとした1以上の超辺であり、各頂点に対応する1以上の翻訳規則の左辺における変数部分に対応する頂点をテイルとした1以上の超辺を取得する超辺取得部と、係り受け森を構成する全頂点と、超辺取得部が取得した1以上の超辺とを有する翻訳森を取得する翻訳森取得部と、翻訳森の各頂点に対応する1以上の各超辺が有する翻訳規則の右辺と単語辞書とを用いて、1以上の翻訳候補を取得する翻訳候補取得部と、1以上の翻訳候補のうちいずれか1以上の翻訳候補である翻訳結果を出力する出力部とを具備する機械翻訳装置により、精度の高い機械翻訳が可能となる。
(もっと読む)
翻訳装置、翻訳プログラムおよび翻訳方法

【課題】各翻訳部品を整合性のとれた自然な文に組み合わせること。
【解決手段】翻訳装置100は、翻訳対象となる文章を、複数の構造部品に分割し、各構造部品のパターンに対応する文法によって機械翻訳することで、複数の翻訳部品を作成する。そして、翻訳装置100は、翻訳部品の主要部を特定し、主要部を変数に置き換えた検索キーおよび主要部をそのままにした検索キーを作成する。翻訳装置100は、主要部を変数に置き換えた検索キーよりも、変数に置き換えていない検索キーのほうが優位になるように、検索キーに重みをつける。翻訳装置100は、各検索キーを利用して、コーパスデータ103dを検索し、ヒット数と検索キーの重みに基づいて、翻訳候補を評価する。
(もっと読む)
略称検索装置,方法およびプログラム,ならびに略称検索機能を備えるデータパース装置
【課題】 固有の名称が含まれる文字列から,辞書に未登録の略称を検索できるようにする。
【解決手段】 データパース装置1は,検索対象を入力するデータ入力部13と,辞書記憶部11の辞書をもとに検索対象から法人名称を検索する辞書引き部14と,検索対象に辞書に登録されていない文字列がある場合に,略称を検索する略称検索部15を備える。略称検索部15は,辞書の登録語と部分的に一致する登録語を検索し,検索した登録語から,部分一致する範囲が長く一致の割合が高いものを特定し,特定した登録語と一致する範囲を略称とし,特定した登録語をその正式名称とする。
(もっと読む)
多言語文法解析装置、多言語文法解析方法および多言語文法解析プログラム
【課題】複数の言語で記述された文集合から個別言語の文法と共に言語共通の文法を推定する技術を提供すること。
【解決手段】多言語文法解析装置1は、個別文法パラメータ集合46と、共通文法パラメータ集合45と、入力多言語データ44とを記憶する記憶手段4と、言語毎に、記憶されている情報に基づいて、構文木確率を推定する処理と、記憶されている情報および推定された構文木確率に基づいて、個別文法のパラメータを推定して更新する処理とを交互に実行することで、各言語の文法を推定する個別文法推定部21と、更新された各言語の個別文法のパラメータと、記憶されている共通文法パラメータとに基づいて、新たな共通文法パラメータを推定して更新する共通文法推定部22と、各言語の文法を推定する処理と、言語共通の文法を推定する処理とを終了条件が満たされるまで交互に繰り返し実行させる推定処理制御部23とを備える。
(もっと読む)
自然言語解析装置、方法及びプログラム
【課題】解析対象の文を文末まで形態素解析しなくても、文字ごとの係り受け関係を決定することが可能な自然言語解析装置、方法及びプログラムを提供すること。
【解決手段】自然言語解析装置10は、解析対象の文を構成する文字を文字単位で取得し、取得した文字ごとの依存関係を決定する。そして、自然言語解析装置10は、当該解析対象の文の先頭文字から順にこの文字ごとの依存関係を決定する過程で、係り先が未確定の文字を依存先未決スタック107にスタックしていき、依存関係の判定により文字の係り先が決定した後に、依存先未決スタック107に蓄積された文字の依存関係の決定を行って文字の係り受けを決定する。
(もっと読む)
単語クラスタリング装置及び方法及びプログラム及びプログラムを格納した記録媒体
【課題】意味の近い単語の集合をクラスタとして適切に抽出することを目的とする。
【解決手段】各単語ベクトルの各成分値を成分値の和で割ることにより確率ベクトルに変換し、その確率ベクトルのエントロピー、または、エントロピーを正規化した値を確率ベクトルの重みとする。その各確率ベクトルを初期クラスタとし、クラスタA,B間の距離を、Aの重み付き重心ベクトルとBの重み付き重心ベクトルの各成分の差の自乗の和に、Aの重みと、Bの重みと、Aの重みとBの重みの和の逆数と、を乗じた値とする。そして、最小の距離をとるクラスタA、Bを結合する。この処理を繰り返して、確率ベクトル群のクラスタリングを行い、クラスタリングの結果得られたクラスタ内の確率ベクトルに対応する単語の集合をクラスタとする。
(もっと読む)
一般化された巡回セールスマン問題としてのフレーズ−ベースの統計的機械翻訳
【課題】一般化された巡回セールスマン問題としてのフレーズ−ベースの統計的機械翻訳を行う。
【解決手段】統計的機械翻訳(SMT)および一般化された非対称巡回セールスマン問題(GTSP)グラフを使用して2つの言語を翻訳する方法は、SMT問題をGTSPとして定義するステップ(120)と、入力文のブロックを、前記GTSPを表すGTSPグラフ内のノードに対応するバイ−フレーズを使用して翻訳するステップ(122)と、前記GTSPを解くステップ(124)と、前記GTSPの解によって定義される順序で前記翻訳済みブロックを出力するステップ(126)と、を包含する。
(もっと読む)
単語出現確率算出装置および方法、語義推定装置および方法、プログラム、並びに記録媒体
【課題】膨大な量の学習コーパスを必要とすることなく、精度の高い単語出現確率を算出する。
【解決手段】直接出現確率算出部15Bにより、語義別見出語と語義文の組み合わせごとに、当該語義文内に当該語義別見出語が出現する直接出現確率14Cを算出し、間接共起確率算出部15Cにより、任意の語義別見出語が複数の語義文においてそれぞれ異なる語義別見出語と共起するという連接共起関係を経ることにより、任意の2つの語義別見出語が1つ以上の語義別見出語を介して間接的に共起する間接共起確率14Dを語義別見出語対ごとに算出し、単語出現確率算出部15Dにより、間接共起確率14Dから生成した間接共起確率行列Cと、直接出現確率14Cから生成した直接出現確率行列Aとの行列積CAを算出し、当該行列積CAの各行列要素を単語出現確率14Eとして出力する。
(もっと読む)
抽出規則作成システム、抽出規則作成方法及び抽出規則作成プログラム
【課題】ユーザが欲する情報を抽出するための規則を効率よく作成する抽出規則作成システムを提供する。
【解決手段】抽出規則作成手段82は、タグ付きテキスト及びそのタグ付きテキスト中の文字列の位置を示す情報である文字列位置情報が与えられたときに、その文字列位置情報が示す位置に対応する単語又はタグと、その単語又はタグの前後の単語又はタグとを組み合わせて、タグ付きテキストから情報を抽出するための規則である抽出規則を作成する。適合文位置情報抽出手段83は、タグ付きテキスト記憶手段81に記憶されたタグ付きテキストごとに、抽出規則に適合する単語又はタグを含む適合文の位置を示す情報である適合文位置情報を抽出する。評価値算出手段84は、1つのタグ付きテキスト内に現れる適合文がより少ないほど評価値を高く算出し、より多くのタグ付きテキスト内に適合文が現れるほど評価値を高く算出する。
(もっと読む)
オノマトペのイメージ評価システム、イメージ評価装置、およびイメージ評価用プログラム
【課題】オノマトペの客観的なイメージの情報を提示するオノマトペのイメージ評価システム、イメージ評価装置、およびイメージ評価用プログラムを提供する。
【解決手段】評価処理対象のオノマトペの音韻形態を解析する音韻形態解析部41と、解析された各音韻形態のイメージを示す語句を定性的なイメージ評価情報として取得する定性イメージ評価部42と、定性的なイメージ評価情報から当該オノマトペのイメージを示す文書情報を生成する文書情報生成部43と、解析された各音韻形態の予め設定された形容詞ごとのイメージ評価値を特定し、これに基づいて当該オノマトペのイメージ評価値を当該オノマトペの定量的なイメージ評価情報として算出する定量イメージ評価部44と、当該オノマトペのイメージを示す文書情報と定量的なイメージ評価情報とを、当該オノマトペの評価情報として出力するための出力情報を生成する出力情報生成部45とを有する。
(もっと読む)
機械翻訳装置及び機械翻訳プログラム
【課題】用例ベース方式による中国語の入力語の翻訳精度を向上させる。
【解決手段】差分文字列検索部5が、翻訳対象の差分文字列を前後方向にN文字拡張した拡張パターン及び類似用例の差分文字列を前後方向にN文字拡張した拡張パターンを作成し、文字数を順次短くしながら翻訳対象の拡張パターン及び類似用例の拡張パターンの日本語訳を辞書データベース6bから検索する。翻訳対象の拡張パターンの日本語訳と類似用例の拡張パターンの日本語訳の双方の検索に成功した場合、組立部8が、類似用例の日本語訳を構成する文字列中の拡張パターンに対応する部分を翻訳対象の拡張パターンの日本語訳に置換した文字列を出力する。
(もっと読む)
単語列探索装置およびコンピュータプログラム
【課題】nグラム等の言語的特徴(出現確率)を用いるだけでなく、所定の重要な単語を含む単語列を上位解として選択することのできる単語列探索装置を提供する。
【解決手段】単語の重要度を表わす重要度スコア値を記憶する単語重要度記憶部を備え、グラフを文頭のノードから探索しながら、グラフ上のノードにおいて、文頭のノードから当該ノードまでの単語の列に関して、単語重要度記憶部から読み出した重要度スコア値の積算値をも加味した前向きスコアを計算し、グラフを文末のノードから探索しながら、各ノードにおいて、文末のノードから当該ノードまでの単語の列に関して、単語重要度記憶部から読み出した重要度スコア値の積算値をも加味した後向きスコアを計算し、前向きスコアと後向きスコアとに基づいて、ノードの総合スコアを算出し、総合スコアの上位の単語列を出力する。
(もっと読む)
地域特性辞書生成方法及び装置
【課題】地域毎に特徴語を抽出して、特徴語に関する地域特性辞書を生成する方法及び装置を提供すること。
【解決手段】地域特性辞書生成サーバ1は、ブログサーバ2に格納されているブログのうち、地域ブログの情報を収集するブログ情報収集部11と、収集された地域ブログの情報より用語を抽出して、用語の出現数の合計値を地域毎に計数する用語出現数計数部12と、地域ブログの数量及び用語が含まれている地域ブログの数量を計数するブログ数計数部13と、地域における用語の出現数の合計値、地域ブログの数量、及び用語が含まれている地域ブログの数量に基づいて所定の演算を行い、地域における用語の出現頻度の偏差を算出する用語出現偏差算出部14と、算出した用語の出現頻度の偏差が予め定めた閾値よりも大きい場合に、用語の出現頻度の偏差を算出した地域の地域特性辞書である辞書DB22に、当該用語を登録する辞書登録部15とを備える。
(もっと読む)
単語間関連度判定装置、単語間関連度判定方法、プログラムおよび記録媒体
【課題】2単語間の関連度の近似値を効率的に逐次計算することができ、つまり、全体的な精度を大きく損なわずに、本来は次元数に比例して増加する積算処理を、効率化することができる単語間関連度判定装置を提供することを目的とする。
【解決手段】コーパスを入力し、任意の単語について、上記単語と上記単語の次元に対する単語意味属性との共起頻度を集計することによって頻度ベクトルを生成し、上記単語意味属性が具備する木構造に従って、上記頻度ベクトルを、確率として正規化して概念ベクトルを生成し、任意の2単語に対して得られた2つの概念ベクトル間の距離を、上記木構造に従って、親ノードに対応する上記確率と子ノードに対応する上記確率とに基づいて計算した局所的な距離を、根ノードから葉ノードに向かって積算することによって上記2単語間の関連度を算出する。
(もっと読む)
確率文脈自由文法探索装置、確率文脈自由文法探索方法、および確率文脈自由文法探索プログラム
【課題】確率文脈自由文法探索において、探索結果の精度を維持しつつ、計算コストを低減する技術に関する。
【解決手段】確率文脈自由文法探索において、終端記号と非終端記号(ノード)と確率付き生成規則の集合によって定義される文法Gが与えられたとする。まず、文法Gをランダムに並び換える(ステップS101)。次に、ノードをすべて集約して近似確率P2を算出し(ステップS105)、文法Gに対してノードの枝刈り(枝刈りされた部分は探索の対象外とされる)を行いつつ、ノードを高さごとに集約して近似確率P1を算出して(ステップS107)、解候補の確率θと比較し(ステップS106、S108)、ノードの枝刈りを行いつつ、厳密な確率Pの算出に用いられる文法の数やノードの数を低減した上で、厳密な確率計算を行う(ステップS109)。
(もっと読む)
情報処理プログラム、情報処理方法、および情報処理装置
【課題】複数の構成員が属する集団内での各単語の使用実態に即して、同義語群の中から適切な代表語を選択する。
【解決手段】計数部102は、インタビュー結果データ106と同義語群定義データ107を参照し、インタビューした各構成員について、同義語群のいずれかに分類されている各単語が当該構成員のインタビュー結果データ106に出現する回数を計数する。第1の評価部103は、各単語について、計数された回数の単純和または重み付け和を、第1の評価値として算出する。第2の評価部104は、各単語について、インタビュー結果データ106が当該単語を含む構成員の人数を、単純にまたは重み付けして、第2の評価値として計数する。選択部105は、同義語群定義データ107において各同義語群に分類された単語のうちの1つを、第1および第2の評価値に基づいて、代表語として選択する。
(もっと読む)
言語処理装置およびプログラム
【課題】互いに関係を持つ可能性の高い名詞の対のみを精度良く抽出するとともに、それら対をなす2つの名詞の関係も抽出することのできる言語処理装置を提供する。
【解決手段】言語処理装置は、入力テキストデータを基に、一つの文に含まれる単語のペアを処理対象単語ペアとして選択するとともに処理対象単語ペアの出現頻度特徴を抽出する処理対象単語ペア特徴抽出部と、共起単語を選択するとともに、共起単語の出現頻度特徴を抽出する共起単語特徴抽出部と、処理対象単語ペアと共起単語との当該文中の構文構造を抽出するとともに、構文構造の出現頻度特徴を抽出する構文構造特徴抽出部と、得られたこれらの出現頻度特徴のデータを用いて機械学習処理により、処理対象単語ペアの条件付き確率と、共起単語の条件付き確率と、構文構造の条件付き確率とを算出し、学習結果データとして学習結果データ記憶部に書き込む機械学習処理部とを具備する。
(もっと読む)
対訳表現処理装置およびプログラム
【課題】対訳表現同士を推定する処理であって、複数単語同士のアラインメントができるとともに、長い対訳表現のアラインメントを可能とする対訳表現処理装置を提供する。
【解決手段】対訳表現処理装置は、対訳フレーズ組候補を複数有する対訳フレーズ候補データを記憶し、対訳文書組データを基に、対訳フレーズ候補データを読み出し、複数言語の全てについて対訳文書の中に語系列が存在するような対訳フレーズ組候補を選択して取得し、統計量に基づき対訳フレーズ組候補の確からしさの順位付けを行ない、対訳フレーズ候補取得部によって取得された複数の対訳フレーズ組候補から、複数の対訳フレーズ組候補が互いに整合する関係を有するように、各々の対訳フレーズ候補組を採用するか否かを決定し、採用された対訳フレーズ候補組の情報を含んだアラインメント処理結果を出力する。
(もっと読む)
文・単語対応付け装置及び文・単語対応付けプログラム
【課題】二言語間における文対応と単語対応の両方の信頼性を向上させ高精度な対応付けを行う。
【解決手段】対訳関係にある二言語間の複数のテキスト情報に基づき、前記テキスト情報に含まれる文及び単語の対応付けを行う文・単語対応付け装置において、前記テキスト情報に含まれる少なくとも1つの文章に対して形態素解析を行う形態素解析手段と、前記形態素解析手段により得られる二言語間の形態素情報を用いて文単位の対応度を算出する文対応度算出手段と、前記文対応度算出手段により得られる文対応度により単語対応度を算出する単語対応度算出手段と、前記文対応度算出手段により得られる文対応度結果及び前記単語対応度算出手段により得られる単語対応度結果を用いて、前記文対応度算出手段による文対応度の算出及び前記単語対応度算出手段による単語対応度の算出を予め設定された回数実行させて対応付けを制御する対応付け制御手段とを有する。
(もっと読む)
対訳表現処理装置およびプログラム
【課題】対訳表現同士を推定する処理であって、複数単語同士のアラインメントができるとともに、長い対訳表現のアラインメントを可能とする対訳表現処理装置を提供する。
【解決手段】対訳表現処理装置が、複数言語による対訳文書の組である対訳文書組データを複数記憶する対訳文書組群データ記憶部と、前記対訳文書組データ記憶部から読み出した前記対訳文書組データに基づき、単一の前記対訳文書組データ内に出現する語系列の前記複数の言語間での共起頻度をカウントし、全ての前記対訳文書組データにおける前記共起頻度の合計値が所定の頻度閾値以上となるような、前記複数言語による前記語系列の組を対訳フレーズ組候補として抽出して出力する対訳文書組群データ分析処理部とを具備する。
(もっと読む)
1 - 20 / 63
[ Back to top ]