
Fターム[5B091EA25]の内容
Fターム[5B091EA25]に分類される特許
1 - 20 / 77
機械翻訳システム、機械翻訳方法および機械翻訳プログラム
対話装置、対話方法および対話プログラム
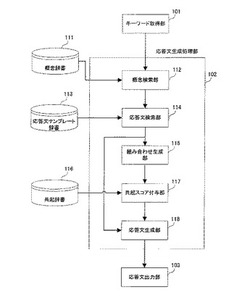
【課題】予め記憶した文に含まれないキーワードが入力された場合でもユーザの意図に即した応答文を生成する対話装置を実現する。
【解決手段】実施形態の対話装置におけるキーワード取得手段は、ユーザからのキーワードを取得する。概念検索手段は、概念辞書から前記キーワードの概念を検索する。応答文検索手段は、応答文テンプレート辞書から前記概念検索手段で検索された概念を含む応答文テンプレートを検索する。組み合わせ生成手段は、前記応答文検索手段で検索された応答文テンプレート中の自立語と前記キーワードとの組み合わせを生成する。共起スコア付与手段は、共起辞書を利用して前記組み合わせ生成手段で生成された組み合わせに共起スコアを付与する。応答文生成手段は、前記キーワードと、前記応答文検索手段で検索された応答文テンプレートと、前記共起スコア付与手段で付与された共起スコアとを利用して、ユーザに提示する応答文を生成する。
(もっと読む)
文書平易化装置およびプログラム

【課題】変換対象の単語を修飾する修飾句をも考慮しながら、名詞から動詞等へ、異なる品詞間での単語変換を行うことによって、自動的に文を平易化する。
【解決手段】平易化規則選択部は、係り受け解析結果データに含まれる名詞データに基づき、平易化規則テーブル記憶部から適用可能な前記平易化規則データを選択する。修飾句変換規則選択部は、平易化規則データが適用され得る名詞データを修飾する連体修飾句データを抽出し、修飾句変換規則データを選択する。格フレーム照合部は、平易化規則データに含まれる用言データと、選択された修飾句変換規則データに含まれる連用修飾句データとに基づき、格フレームテーブル記憶部から出現頻度データを読み出し、出現頻度に基づいて表現の置換を行う。体言変換規則選択部は、自立語に合う体言化データを選択し、用言データを体言化する。
(もっと読む)
翻訳装置、翻訳プログラムおよび翻訳方法
【課題】各翻訳部品を整合性のとれた自然な文に組み合わせること。
【解決手段】翻訳装置100は、翻訳対象となる文章を、複数の構造部品に分割し、各構造部品のパターンに対応する文法によって機械翻訳することで、複数の翻訳部品を作成する。そして、翻訳装置100は、翻訳部品の主要部を特定し、主要部を変数に置き換えた検索キーおよび主要部をそのままにした検索キーを作成する。翻訳装置100は、主要部を変数に置き換えた検索キーよりも、変数に置き換えていない検索キーのほうが優位になるように、検索キーに重みをつける。翻訳装置100は、各検索キーを利用して、コーパスデータ103dを検索し、ヒット数と検索キーの重みに基づいて、翻訳候補を評価する。
(もっと読む)
機械翻訳装置、および機械翻訳方法
【課題】従来、精度の高い機械翻訳ができなかった。
【解決手段】係り受け森を構成する各頂点に対して、1以上の各翻訳規則を適用し、頂点ごとに、合致する1以上の翻訳規則を取得する翻訳規則取得部と、係り受け森を構成する各頂点をヘッドとした1以上の超辺であり、各頂点に対応する1以上の翻訳規則の左辺における変数部分に対応する頂点をテイルとした1以上の超辺を取得する超辺取得部と、係り受け森を構成する全頂点と、超辺取得部が取得した1以上の超辺とを有する翻訳森を取得する翻訳森取得部と、翻訳森の各頂点に対応する1以上の各超辺が有する翻訳規則の右辺と単語辞書とを用いて、1以上の翻訳候補を取得する翻訳候補取得部と、1以上の翻訳候補のうちいずれか1以上の翻訳候補である翻訳結果を出力する出力部とを具備する機械翻訳装置により、精度の高い機械翻訳が可能となる。
(もっと読む)
テキストを生成する方法及びシステム
【課題】本発明は、全体としてテキストを生成する方法及びシステムに関し、特に、レポート用の構文法的に正しいテキストを生成する方法及びシステムに関する(ただし、これに限定されない)。
【解決手段】データを解釈するエキスパートシステムの能力は、人間の専門家を制限するのと同じ要因、すなわちデータ複雑性によって制限される。したがって、従来のエキスパートシステムは、ますます大量化する複雑なデータを解釈し、そのようなデータを知識に変換する際に制限を受ける。本発明は、複雑なデータを解釈し、そのようなデータをテキストレポート内で表現される知識に変換する手段を提供する。
(もっと読む)
翻訳の品質を定量化するための装置及び方法
【課題】 あらゆるタイプの文書及び資料の翻訳に、客観的な自動品質管理又は品質保証を適用する装置と方法を提供すること
【解決手段】 翻訳の品質評価を自動化するためのシステム(10)。システム(10)は、プロセッサ(14)、及び操作可能な状態で相互に接続されているメモリデバイス(16)を有するコンピュータ(12)を含んでもよい。第1の言語によるソーステキストは、メモリデバイス(16)内に格納されてよい。第2の言語へのソーステキストの翻訳を含むターゲットテキストもメモリデバイス(16)内に格納されてよい。これに加えて、複数の実行ファイルは、メモリデバイス(16)上に格納されるとともに、プロセッサ(14)によって実行されたときに、1つ以上のブロックを含むテストサンプルを単独で認識するように構成されてもよく、前記各ブロックは、ソーステキストから選択されたソース部分とターゲットテキストから選択された対応するターゲット部分とを有する整合されたセットを含む。
(もっと読む)
文章解析プログラム及び文章解析装置
【課題】一方の文の語句と他方の文の語句とを換言できない場合において、文と文とが互いに関連するか否かを判定する文章解析プログラム及び文章解析装置を提供する。
【解決手段】文章解析プログラム110は、制御部10を、第1の文章から少なくとも、同格であって対となる語句と、当該対となる語句を修飾する語句とを抽出し、それらの対応付けを示す文脈規則情報111を作成する文脈規則情報作成手段102と、第1の文と第2の文とを含む第2の文章において、第1の文の第1の語句及び第2の語句が文脈規則情報111に含まれるときであって、第1の語句及び第2の語句以外の第1の文に含まれる語句、文脈規則情報111の対となる語句の他方及び第2の語句が第2の文に含まれるとき、第1の文と第2の文とが関係すると判定する文章関係判定手段105として機能させる。
(もっと読む)
解析モデル学習装置、解析モデル学習方法及び解析モデル学習プログラム
【課題】解析モデルの自動学習における処理速度の向上を図ること。
【解決手段】解析モデル学習装置1は、一度に読み込む訓練データ中の記事数を1記事または少数記事とし、それ以前に読み込まれた記事も含めて解析を行い解析結果の初期値を与えるベースライン解析部2と、訓練用データに対する解析結果を保持する解析結果テーブル3と、解析誤りデータからルールテンプレート5に基づいてルール候補を作成するルール候補作成部4と、それを保持するルール候補テーブル7と、ルール候補の中で最も正味の正解の増加数が大きくなるルールを選択するルール選択部6と、選択されたルールを保持する解析モデルテーブル9と、保持されたルールを、前記テーブル3に保持された訓練データに対する解析結果に適用し解析結果を変換するルール適用部8と、解析モデルテーブル9に保持されたルールを解析モデルとして外部に出力する出力部10とを備える。
(もっと読む)
機械翻訳装置、機械翻訳方法、およびそのプログラム
【課題】高い翻訳精度の機械翻訳技術を提供する。
【解決手段】本発明は、部分仮説を拡張する手法によって、翻訳元言語の単語列から翻訳先言語の単語列を生成する機械翻訳装置2であって、(a)翻訳候補となる翻訳先言語の単語列だけでなく、少なくとも、(b)翻訳元言語の文を翻訳先言語の語順に並び替えた単語列、および、(c)翻訳先言語の文を翻訳元言語の語順に並び替えた単語列、のいずれかを考慮して部分仮説の評価値を示す部分仮説スコアを算出することで、翻訳精度を向上させることができる。
(もっと読む)
校正支援装置及び校正支援プログラム
【課題】文書に対してなされた校正における校正規則を、校正前文書及び校正後文書から自動抽出できるようにする。
【解決手段】文書読出部15が校正前文書7及び校正後文書8を読み出し、文書解析部16がこれを解析して要素に分割し、各要素の共起関係を抽出する。頻度算出部17は、校正前文書において共起関係が出現する頻度及び校正後文書において共起関係が出現する頻度を夫々算出する。さらに、差分算出部19が、校正後の共起頻度から校正前の共起頻度を差し引いた差分を算出し、共起関係に含まれる要素を次元軸とし差分を成分とする差分ベクトルを生成する。また、校正規則作成部20が、差分ベクトルが生成された要素について差分ベクトルを反転させ、当該反転させたベクトルと他の要素の差分ベクトルとが一致又は近似するときに、当該要素と当該他の要素とで校正規則を作成する。そして、表示処理部21及び辞書登録部22が当該校正規則を出力する。
(もっと読む)
用語抽出方法とその装置と、プログラム
【課題】高速かつ用語のゆらぎ等を考慮した用語抽出方法を提供する。
【解決手段】この発明の用語抽出方法は、用語WFST作成過程と、ゆらぎWFST変換過程と、変換器合成過程と、WFST記憶過程と、WFST復号過程とを含む。用語WFST作成過程は、外部から入力される用語リストの各用語をWFST表現した用語WFSTを作成する。ゆらぎモデル変換過程は、用語のゆらぎ確率若しくは音訳のゆらぎ確率をゆらぎモデルであるゆらぎWFSTに変換する。そして、WFST復号過程で、ゆらぎWFSTと用語WFSTとを合成した合成WFSTを用いて、入力文字列から表記ゆらぎや異表記を含む用語を抽出する。
(もっと読む)
文書平易化装置および平易化規則テーブル作成装置、ならびにプログラム
【課題】不要な変形規則を含まず、難解単語から平易単語への変形規則のみを自動的に獲得することのできる文書平易化装置および平易化規則テーブル作成装置を提供する。
【解決手段】平易化規則テーブル作成装置内では、置換可能単語対作成部が、辞書テーブル記憶部から読み出した単語と語釈文に基づき置換可能単語対として出力する。平易化規則候補認定部は、置換可能単語対に含まれる単語それぞれについて難易度データを読み出し、置換可能単語対が平易化規則となり得るか否かを認定する。文脈類似認定部は、置換可能単語対に含まれる単語に基づいて文脈類似データベース記憶部を読み出し、置換可能単語対に含まれる単語同士が文脈類似な関係にあるか否かを認定する。平易化規則テーブル書込部は、平易化規則候補認定部によって平易化規則となり得ると認定され且つ文脈類似認定部によって文脈類似な関係にあると認定された平易化規則を生成する。
(もっと読む)
知識構築装置およびプログラム
【課題】テキストに関する構成要素情報を得るためのルールを、単語表層にとらわれずに概念レベルで生成して蓄積することのできる、知識構築装置を提供する。
【解決手段】知識構築装置は、テキスト項目と構成要素情報とを、互いに関連付けて記憶するテキストデータ記憶部を備える。そして、単語抽出部は、テキスト項目に含まれる単語の出現頻度に基づき、テキスト項目に特有の単語を抽出する。知識データ取得部は、単語と単語概念との関係を表わす知識データを取得する。概念獲得部は、前記知識データを用いて、テキスト項目から抽出された単語を対応する単語概念に置き換えるとともに、当該テキスト項目に関連付けられた構成要素情報と組み合わせ、事例データとして出力する。機械学習装置は、この事例データを用いて機械学習を行い、単語概念と構成要素情報との関係を表わすルールを生成する。
(もっと読む)
用語間の対応関係抽出システム及び対応関係抽出プログラム
【課題】テキストデータに基づいて各企業の商品名を抽出し、対応する製品分類に自動的に関連付ける技術を提供する。
【解決手段】一般名称としての製品分類を複数格納した製品分類辞書16と、入力されたテキスト文を形態素単位に分解すると共に、製品分類辞書16を参照し、各形態素の中で製品分類に該当するものに対して対応のタグを付する形態素解析処理部12と、タグを含む文字列パターンと、この文字列パターン中からタグを付された製品分類に属する具体的商品名として抽出すべき文字列の位置とを規定する抽出ルールを、複数格納しておく抽出ルール記憶部18と、テキスト文の中の抽出ルールにマッチする文字列パターン中の所定の位置に存する文字列をタグが付された製品分類に属する商品名として抽出し、この製品分類と商品名との組合せを関係情報記憶部20に格納する関係情報抽出部14とを備えた用語間の対応関係抽出システム10。
(もっと読む)
トピック具体表現辞書作成システム、トピック具体表現辞書作成方法及びそのプログラム
【課題】不要語辞書を効率的に作成し、かつ、抽出もれの少ない強化語リストを作成する。
【解決手段】対象トピック観点と、テキストの中で対象トピック観点について記述されている範囲とから、対象トピック観点に対応する具体表現辞書に登録する可能性のある候補のリストである「候補語リスト」を作成する。具体表現辞書と係り受けルールとを使って、具体表現辞書に登録されている単語を含む2単語の係り受け関係を抽出し、係り受け関係を基に不要語を抽出するためのルールを作成し、具体表現辞書に登録されていない単語を不要語として抽出し、不要語辞書に格納する。対応する候補語リストと、対応する不要語辞書とをつきあわせ、候補語リストから、不要語辞書に登録されている単語を削除し、削除されなかった単語は強化語リストに追加する。対象トピック観点に対応する強化語リストを対応する具体表現辞書に追加する。
(もっと読む)
自然言語ユーザインタフェースを漸進的に開発する装置及び方法
【課題】迅速かつ柔軟な自動応答の生成装置及び方法を提供すること。
【解決手段】自然言語ユーザインタフェース生成装置は、ユーザ端末からの会話文の入力に対応した会話文の出力における会話の状況、会話の動作及びそれらの関係を示すコンピュータ上での処理動作をノードとエッジで表現する知識構造の記憶手段と、知識構造を解釈し、複数の対話ルールと対話制御手法の組を予め関連付けて実行する応答手段とを備え、応答手段は、対話制御手法を実施するために、ノードに属する要素のうち少なくとも二つの要素の間の関係において、処理動作の流れを示す関係及び処理動作に必要な関係を対話ルールとして記憶する対話構造記憶手段と、記憶した要素に対して知識構造における関連付けの有無を判別する判別手段と、判別手段による判別の結果に応じて、対話構造記憶手段に記憶された二つの要素の間の関係を変更する変更手段と、を備える。
(もっと読む)
関係抽出装置、関係抽出方法、及びプログラム
【課題】予め辞書を用意することなく、語と語との関係及びその関係を満たす語の集合を抽出し得る、関係抽出装置、関係抽出方法、及びプログラムを提供する。
【解決手段】語と語との関係及びその関係を満たす語の集合を抽出する関係抽出装置11を用いる。関係抽出装置11は、複数の語を要素として含む構造化データから、2以上の要素を要素集合として抽出し、抽出した要素集合を、予め設定された語と語との関係を表す文字列パターンに当てはめて、複数の文字列表現を作成する文字列表現作成部3と、作成された複数の文字列表現それぞれが文書集合中に出現しているかどうかを判定し、文書集合中に出現している文字列表現を、語と語との関係及びその関係を満たす語の集合として出力する文字列表現判定部4とを備えている。
(もっと読む)
語句抽出ルール生成装置、語句抽出システム、語句抽出ルール生成方法、及びプログラム
【課題】学習データが意味的に類似するクラスを含む場合、及びそうでないクラスを含む場合のいずれであっても、語句のクラスを正しく分類可能な抽出ルールを学習し得る、語句抽出ルール生成装置、語句抽出ルール生成方法、及びプログラムを提供する。
【解決手段】語句抽出ルール生成装置2は、特徴量とクラス情報とを含む学習データから、特定のクラスの語句を抽出するための語句抽出ルールを生成する装置である。語句抽出ルール生成装置2は、特徴量の種類と、特徴量の種類別に付与されている特徴量の重みとによって予め設定された各クラスの定義を用いて、学習データの特徴空間を変換する特徴空間変換部20と、特徴空間変換部20によって特徴空間が変換された学習データから語句抽出ルールを学習する、抽出ルール学習部21とを備えている。
(もっと読む)
能動学習装置及び方法
【課題】日本語係り受け解析において、受動学習の場合よりも、より少ない人手コストで高い精度が得られる能動学習装置及び方法を提供すること。
【解決手段】能動学習装置10は、日本語を構成する文節の係り関係の正解事例データDB41に基づいて、文節の係り関係を判定する係り関係モデルDB31を作成する。そして、能動学習装置10は、一の文を係り関係モデルDB31を用いて係り受け解析を行い、解析結果を出力し、出力した解析結果が所定の場合に一の文を選択し、選択した一の文をユーザ端末60に提示し、提示した一の文を構成する文節の係り関係についての判定情報を受け付け、受け付けた判定情報に基づく正解データを正解事例データDB41に追加し、追加された正解事例データDB41に基づいて係り関係モデルDB31を更新する。
(もっと読む)
1 - 20 / 77
[ Back to top ]