
Fターム[5D015EE05]の内容
Fターム[5D015EE05]に分類される特許
1 - 20 / 172
雑音抑圧装置、方法及びプログラム
【課題】音響信号から雑音信号を効果的に抑圧することができる雑音抑圧技術を提供する。
【解決手段】雑音を含まない、多数話者の音声信号を学習データとして学習された話者独立の音声信号の確率モデルである話者独立音声モデルを音響信号に含まれる音声信号の話者に適応させるための話者適応パラメータと、雑音信号の確率モデルである雑音モデルと、話者独立音声モデルとを用いて、音響信号の確率モデルである第一確率モデルを生成し、第一確率モデルと音響信号の音響特徴とに基づいて雑音信号を推定し、推定した雑音信号を学習データとして雑音モデルを教師無し学習し、音響信号の音響特徴と話者独立音声モデルと雑音モデルとを用いて、音響信号に含まれる音声信号を推定し、推定した音声信号を学習データとして、話者適応パラメータを教師無し推定し、音響信号の音響特徴と話者独立音声モデルと雑音モデルと話者適応パラメータとを用いて雑音信号を抑圧する。
(もっと読む)
残響抑制装置および残響抑制方法並びに残響抑制プログラム

【課題】雑音成分の大きさにかかわらず、音声を歪ませることなく残響成分のみを正確に抑制する。
【解決手段】音声の入力に応じてマイクロホンから得られる入力信号の電力の時間変化を解析することにより、前記音声が発声されている区間の末尾に続く残響区間における前記入力信号の電力の単位時間当たりの減少量を求める解析部と、前記解析部による解析結果に基づいて、前記入力信号を減衰させる比率を示す抑制ゲインを制御する抑制制御部とを備える。また、音声の入力に応じてマイクロホンから得られる入力信号の電力の時間変化を解析することにより、前記音声が発声されている区間の末尾に続く残響区間における前記入力信号の電力の単位時間当たりの減少量を求め、前記残響区間における前記入力信号の電力の単位時間当たりの減少量に基づいて、前記入力信号を減衰させる比率を示す抑制ゲインを制御する処理をコンピュータに実行させる。
(もっと読む)
音響モデル作成装置、音響モデル作成方法、及び音響モデル作成システム
【課題】本発明が解決しようとする課題は、任意の雑音抑圧方式で作成された雑音抑圧信号にマッチした音響モデルを作る技術を提供することにある。
【解決手段】本願発明は、雑音の無い環境で収録した音声であるクリーン信号に、リアルタイムで収録している雑音信号を付加して雑音付加信号を作成し、前記作成された雑音付加信号から雑音を取り除いて雑音抑圧信号を作成し、前記作成した雑音抑圧信号を用いて計算したGMMを、前記クリーン信号を学習したモデルであるクリーンモデルのGMMと入れ替えることで、雑音抑圧モデルを作成することを特徴とする。
(もっと読む)
信号処理装置および方法、並びにプログラム
【課題】音声認識装置においてクリッピングによる性能劣化を防止する。
【解決手段】変換部は、入力された処理対象の信号をA/D変換し、分析部は、A/D変換された信号がクリップしている場合、クリップしていない信号を分析対象信号として生成し、分析対象信号を分析し、処理部は、分析された信号を処理する。例えば切り出した分析区間がクリップされた部分を含む場合、クリップされている部分が除外されるように、前記分析区間を基準値より短い長さに変更することで、前記分析対象信号を生成する。
(もっと読む)
背景音抑圧装置、背景音抑圧方法、およびプログラム
【課題】計算コストを小さく抑え、より複雑な形状をした確率密度関数を利用することができる、より効率的で高精度な背景音抑圧装置を提供する。
【解決手段】本発明の背景音抑圧装置40は、特徴量抽出部100が観測信号から高解像度音源位置特徴量と高解像度スペクトル特徴量を抽出し、音源位置占有度推定部210が高解像度音源位置占有度を求め、高解像度占有度推定部520が高解像度占有度とスペクトルパラメータを推定し、目的音声推定部600が目的音声を推定する。
(もっと読む)
雑音/残響除去装置とその方法とプログラム
【課題】クリーン音声の事例モデルのみを用いて音声強調を行う雑音/残響除去装置を提供する。
【解決手段】強調処理結果信頼性計算部は、入力信号の特徴量と、1次音声強調信号とから、その1次音声強調信号の不確かさを示す値を出力する。マッチング部は、1次音声強調信号と、当該1次音声強調信号の不確かさを示す値と、学習データの事例モデルと、を入力として各時間フレームに対して入力信号に含まれるクリーン音声に一番近いクリーン音声系列を与える学習データセグメントを出力する。音声強調フィルタリング部は、入力信号と学習データセグメントを入力として、該学習データセグメントと対を成す振幅スペクトルデータを事例モデル記憶部から読み出してウィナーフィルタを生成し、入力信号のパワースペクトルにそのウィナーフィルタを乗じてフィルタリングして音声強調信号を出力する
(もっと読む)
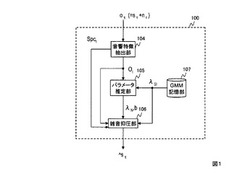
雑音抑圧装置、方法及びプログラム
【課題】音声信号の存在有無に関わらず、雑音信号を学習データとして利用し、より多くの雑音信号の変化や特徴を雑音信号の確率モデルに反映することができ、より正確に雑音信号を抑圧することができる雑音抑圧技術を提供する。
【解決手段】音響信号の音響特徴を抽出する。雑音を含まない音声信号の確率モデル(以下「音声モデル」という)と音響信号の音響特徴とを用いて、雑音信号を推定し、推定した雑音信号を学習データとして雑音信号の確率モデル(以下「雑音モデル」という)を教師無し学習する。雑音モデルを用いて音響信号の雑音信号を抑圧する。
(もっと読む)
音声データ中継装置、端末装置、音声データ中継方法、および音声認識システム
【課題】安定した品質の音声認識サービスを提供する。
【解決手段】音声データ中継装置110は、車載端末102と音声認識サーバ104との間を中継するにあたって、音声認識サーバ104の音声認識性能の変化を調べるために、評価用音声データを雑音抑圧モジュール118において雑音抑圧処理した後、音声認識サーバ104に送信し、認識結果を受信する。そして、音声データ中継装置110は、音声認識サーバ104の認識結果に基づいて、雑音抑圧処理に用いる雑音抑圧用パラメータや音声認識サーバ104から得られた複数の認識結果の統合処理に用いる結果統合用パラメータの値を最適な値に設定する。これにより、音声認識サーバ104の音声認識性能が変化する場合においても、適切なパラメータを設定することができる。
(もっと読む)
音声判別装置、音声判別方法および音声判別プログラム
【課題】
複数チャンネルのシステム音によって生じるエコーに対しても頑健に動作する音声判別装置を提供することである。
【解決手段】
実施形態の音声判別装置は、複数チャンネルのシステム音を複数のスピーカから再生した再生音およびユーザの音声を含んだ第1の音響信号について音声/非音声を判別する音声判別装置であって、少なくとも前記複数チャンネルのシステム音に基づいて、周波数帯域別の重みを付与する重み付与手段と、前記重み付与手段で付与された周波数帯域別の重みを利用して、前記第1の音響信号に含まれる前記再生音を抑圧した第2の音響信号から特徴量を抽出する特徴抽出手段と、前記特徴抽出手段で抽出された特徴量に基づいて、前記第1の音響信号について音声/非音声を判別する音声/非音声判別手段とを備える。
(もっと読む)
音声判別装置、音声判別方法および音声判別プログラム
【課題】
音響信号から利用者の音声の主要な成分を除外せずに妨害音の影響を除外する音声判別装置を提供することである。
【解決手段】
実施形態の音声判別装置は、利用者の音声を含む第1の音響信号の周波数スペクトルと妨害音を含む第2の音響信号の周波数スペクトルに基づいて、周波数帯域別の重みを付与する重み付与手段と、前記重み付与手段で付与された周波数帯域別の重みを利用して、前記第1の音響信号の周波数スペクトルから特徴量を抽出する特徴抽出手段と、前記特徴抽出手段で抽出された特徴量に基づいて、前記第1の音響信号の音声/非音声を判別する音声/非音声判別手段とを備える。
(もっと読む)
テレビジョン装置及び遠隔操作装置
【課題】 音声認識で操作するテレビジョン装置において、音声認識中に出力音声をミュートする機会を必要最小限に抑える。
【解決手段】 ユーザによる音声認識開始の指示の入力を受けてから、音声認識処理が終わるまでの間、出力音量の設定値を一時的に閾値以下の値に変更する。
(もっと読む)
特徴量強調装置、特徴量強調方法、及びそのプログラム
【課題】訓練データセットでカバーされない種類の雑音が観測特徴量に含まれる場合でも適切に所望特徴量を推定することを可能とする。
【解決手段】観測特徴量の時系列データから雑音特徴量を推定し、時系列データを構成する短時間フレーム毎に、各混合要素に対する事後重みと各混合要素に対する条件つき強調特徴量を、それぞれ観測特徴量だけでなく雑音特徴量を用いて計算し、得られた各混合要素に対する事後重みと各混合要素に対する条件つき強調特徴量とから、前記短時間フレーム毎の所望特徴量の推定値を得る。
(もっと読む)
ノイズ除去装置およびノイズ除去方法
【課題】高ノイズ環境下においても、処理負荷を増大することなく音声区間判定およびノイズ除去の精度を向上する。
【解決手段】本発明のノイズ除去装置100は、所定区間のオーディオデータが、音声が含まれる音声区間であるか、音声が含まれない非音声区間であるかを判定する音声区間判定部118と、音声区間判定部の判定結果を保持するパラメータ保持部114と、音声区間判定部の判定結果が非音声区間であれば適応フィルタ130の適応処理を行いつつ、音声区間であれば適応フィルタを固定して、所定区間のオーディオデータのノイズ成分を除去するノイズ除去部120とを備え、音声区間判定部が、ノイズ除去部によってノイズ成分が除去されたオーディオデータの音声区間判定を再度実行し、その判定結果がパラメータ保持部に保持された判定結果と異なる場合、ノイズ除去部は、ノイズ成分の除去を再度実行する。
(もっと読む)
状況認知型音声認識方法
【課題】 小型情報機器で使用される埋込型システム上で音声認識の前処理によって音声入力データの動的状況認知パラメータDIPを推定して音声が認識できる耐雑音化技術が不可欠である。
【解決手段】
本発明による音声認識方法は、図1の状況認知前処理部S1によるA/D変換部の出力になる音声入力データに対して動的状況認知パラメータDIPを算出、算出された動的状況認知パラメータDIPの情報により次の処理部分を決定するインタープリターと、可変雑音処理基準パラメータRTHを算出する状況認知変数推定部を構成しておく。動的状況認知パラメータDIPの基準で状況認知変数IPを生成する状況認知生成部と可変雑音処理基準パラメータRTHと状況認知変数IPを比較する分配部を軽由、音声区間を抽出して音声区間以外部分の雑音を減少/除去する音声抽出処理や騒音やデバイス雑音を除去する雑音処理を使用して音声認識前処理を行う。
(もっと読む)
音声認識装置、音声認識方法および音声認識プログラム
【課題】デバイスコストを削減しつつ、外部環境の変化に対応して音声認識を精度良く実行すること。
【解決手段】オンラインテンプレート収集部140が、コントローラ200から取得するメタ情報と、発話区間の信号とを基にして、テンプレートメモリ142に記憶されたテンプレートを順次更新する。テンプレート選択部150は、入力信号と一致度の高いテンプレートをテンプレートメモリ142から検索し、雑音除去部160に出力する。雑音除去部160は、入力信号からテンプレートの信号を除去することで雑音成分を除去し、音声認識部170が、雑音成分の除去された信号に対して音声認識を実行する。
(もっと読む)
雑音抑圧装置とその方法とプログラム
【課題】雑音の音響特徴量を、時間変化を伴わないバイアス成分と残差成分とに分けて推定する雑音抑圧装置を提供する。
【解決手段】雑音バイアス成分推定部は、対数メルスペクトルと、無音GMMとクリーン音声GMMのパラメータと、を入力として雑音信号の音響特徴量空間の重心であるバイアス成分を最適推定し、雑音残差成分推定部が、対数メルスペクトルとバイアス成分と、無音GMMとクリーン音声GMMのパラメータと、を入力として雑音信号とバイアス成分との差分である残差成分を最適推定する。そして、雑音抑圧部は、対数メルスペクトルと複素数スペクトルと、バイアス成分と残差成分と、無音GMMとクリーン音声GMMのパラメータと、を入力として雑音信号を抑圧した音響信号を出力する。
(もっと読む)
受音装置、音声認識システム、及び作業指示システム
【課題】騒音の影響による音声認識の精度低下を低コストで防止した受音装置を提供する。
【解決手段】受音装置は、音声取得用マイクロフォン12と、騒音取得用マイクロフォン31と、を備える。音声取得用マイクロフォン12は、作業者の声を含む第1音情報を取得する。騒音取得用マイクロフォン31は、作業者とともに走行するピッキングカートに取り付けられ、作業者の声の音声認識を行うときに不要となる騒音を含む第2音情報を取得する。
(もっと読む)
携帯型電子機器
【課題】非定常ノイズの影響を低減することによって音声入力中に他の操作を実行することができる携帯型電子機器を実現する。
【解決手段】実施形態によれば、携帯型電子機器は、タッチスクリーンディスプレイを備えた本体を具備し、タッチスクリーンディスプレイ上のタップ位置に対応する表示オブジェクトに関連づけられた機能を実行する。携帯型電子機器は、本体に取り付けられた少なくとも一つのマイクロホンと、本体内に設けられ、マイクロホンからの入力音声信号を処理する音声処理手段と、本体内に設けられ、音声処理手段によって処理された入力音声信号を認識および機械翻訳することによって得られる目的言語の翻訳結果を出力する翻訳結果出力手段とを具備する。音声処理手段は、入力音声信号内に含まれる、タッチスクリーンディスプレイ上をタップすることによって発生するタップ音信号を検出し、検出されたタップ音信号による入力音声信号への影響を軽減するために入力音声信号を補正する。
(もっと読む)
ノイズパワー推定装置及びノイズパワー推定方法並びに音声認識装置及び音声認識方法
【課題】レベルに基づいたしきい値パラメータを必要とせず、ノイズ環境の変化に対して高いロバスト性を有する、ノイズパワー推定装置を提供する。
【解決手段】本発明による周波数スペクトルの成分ごとのノイズパワーを推定するノイズパワー推定装置であって、横軸がパワーの大きさのインデクスであり縦軸が累積頻度である、指数移動平均の重みをつけた累積ヒストグラムを、時系列入力信号の周波数スペクトルの成分ごとに生成する累積ヒストグラム生成部と、該時系列入力信号の周波数スペクトルの成分ごとに、該累積ヒストグラムからノイズパワーの推定値を求めるノイズパワー推定部と、を備えている。
(もっと読む)
音源分離装置、及びプログラム
【課題】音源分離装置において、混合音に含まれる対象音を、該混合音から分離するまでに要する計算量を低減すること。
【解決手段】対象楽曲を構成する楽音が時間軸に沿って推移した波形である楽音推移を取得し(S120)、その取得した楽音推移と楽譜データとに基づいて、対象楽曲を構成する楽音の音高及び演奏開始タイミングに、演奏音の音高及び出力タイミングが一致するように、当該楽譜データを修正して修正楽譜データを生成する(S130,S140)。さらに、音量補正量を導出し(S170)、修正楽譜データ、及び音量補正量を用いて、楽音推移から、一つの音源から出力された音が時間軸に沿って推移した波形である対象音推移を生成する(S180)。ただし、S170では、出力音平均振幅と、楽音平均振幅との比率である音量比率kvを音量補正量として導出する。
(もっと読む)
1 - 20 / 172
[ Back to top ]