
Fターム[5D015GG03]の内容
Fターム[5D015GG03]に分類される特許
1 - 20 / 100
放送受信システム
単語追加装置、単語追加方法、およびプログラム
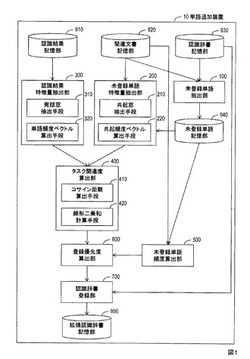
【課題】少量の関連文書からでも、入力音声のタスクに関連した未登録単語を効果的に選択することで、認識辞書の語彙数の増大を抑え、認識精度を向上することができる単語追加装置を提供する。
【解決手段】本発明の単語追加装置10は、未登録単語抽出部100が、認識辞書を用いて、未登録単語を抽出する。未登録単語特徴量抽出部200が、未登録単語を特徴づける共起頻度ベクトルを生成する。認識結果特徴量抽出部300が、認識結果を特徴づける単語頻度ベクトルを生成する。タスク関連度算出部400が、タスク関連度を算出する。未登録単語頻度算出部500が、未登録単語の関連文書における出現頻度である未登録単語頻度を算出する。登録優先度算出部600が、登録優先度を算出する。認識辞書登録部700が、予め設定された閾値を用いて、追加登録単語を抽出し、認識辞書に追加登録単語を追加して拡張認識辞書を生成する。
(もっと読む)
音響モデル生成装置、音響モデル生成方法及び音響モデル生成用コンピュータプログラム

【課題】同一の読みとなる文字列を含む複数の単語のうち、その文字列について異なる発音がなされる可能性のある単語についてのみ、その異なる発音に対応する音響モデルを生成可能な音響モデル生成装置を提供する。
【解決手段】音響モデル生成装置(1)は、少なくとも一つの単語の読みを表す発音列と、読み替えがなされる可能性のある少なくとも一つの変換候補の変換前の読みと変換後の読みの組とを記憶する記憶部(3)と、発音列から変換候補列を抽出する変換候補列抽出部(11)と、変換候補列に含まれる単位音ごとの発音明瞭度に応じた変換候補列明瞭度が異なる発音がなされるレベルである場合、発音列中のその変換候補列の読みを対応する変換後の読みに置換することにより、修正発音列を生成する発音列修正部(12)と、発音列及び修正発音列に対応する音響モデルをそれぞれ生成する音響モデル生成部(13)とを有する。
(もっと読む)
単語追加装置、単語追加方法及びそのプログラム
【課題】追加リソースを必要とせず、追加単語のクラス内単語出現確率を適切に決定する。
【解決手段】追加単語の音素列と単語辞書に登録されている既存単語の音素列の発音類似距離を全ての既存単語についてDPマッチングにより計算する発音類似距離計算部20と、発音類似距離が閾値以下かを判定する判定部30と、閾値以下と判定された既存単語から発音類似距離が小さい上位N個を抽出するN-best発音類似単語抽出部50と、N個の既存単語のユニグラム出現確率を求め、最大のユニグラム出現確率を追加単語のユニグラム出現確率として求めた追加単語のクラス内単語出現確率を言語モデルに追加し、追加単語を単語辞書に追加するクラス内単語出現確率付与部70を備える。発音類似距離が閾値以下の既存単語が存在しない場合、クラス内単語出現確率付与部70は追加単語に対して指定されたクラスにおける最大のクラス内単語出現確率を追加単語に付与する。
(もっと読む)
音声命令語処理装置及びその方法
【課題】使用者との相互作用(Interaction)に基づき音声命令語テーブルを更新することにより、別の音声命令語を入力する過程を必要とせずに、音声認識率を高める音声命令語処理装置及びその方法を提供する。
【解決手段】
本発明は、音声命令語テーブルを格納している格納手段、使用者から音声命令語の入力を受ける音声命令語入力手段、前記音声命令語テーブルに基づき、前記音声命令語入力手段を介して入力された音声命令語を認識する音声命令語認識手段、及び前記音声命令語認識手段が非正常音声命令語と認識した場合、前記入力された音声命令語に係る類似命令語を前記使用者に提供し、前記使用者から選択された類似命令語に前記入力された音声命令語をリンクさせ、前記音声命令語テーブルを更新する音声命令語処理手段を含むことを特徴とする。
(もっと読む)
音声認識システムおよびこれを用いた検索システム
【課題】認識精度を向上させることができるとともに正しい認識結果を得るまでの操作を簡略化することができる音声認識システムを提供すること。
【解決手段】車載装置100は、話者が発声した音声を保存する音声保存バッファ112と、認識辞書116を用いて、音声保存バッファ112に保存された音声に対して音声認識処理を行う音声認識部114とを備える。施設検索サーバ150は、認識辞書116と異なる認識辞書162を用いて、音声保存バッファ112に保存された音声に対して音声認識処理を行う音声認識部160とを備える。車載装置100に備わった優先度調整部122は、2つの音声認識部114、160の認識結果に基づいて、音声保存バッファ112に保存された音声に対応する認識候補を決定する。
(もっと読む)
音声認識辞書拡張装置、システム、方法およびプログラム
【課題】各ユーザが作成するユーザ辞書に登録された用語を音声認識に用いる用語として活用できる音声認識辞書拡張装置を提供する。
【解決手段】音声認識辞書記憶手段81は、音声認識の対象とする用語を含む音声認識辞書を記憶する。未登録用語抽出手段82は、音声認識の対象とする用語とその用語の読みとを対応付けて作成されるリストである用語リストから音声認識辞書に存在しない用語を抽出し、抽出した用語を音声認識辞書に追加する。音声認識手段83は、音声認識辞書に基づいて音声認識を行う。
(もっと読む)
音声認識装置,および音声認識プログラム
【課題】 音声認識装置で,怠け音声を精度良く認識することを目的とする。
【解決手段】 音声認識装置1は,音声データの音声特徴量を算出する音声入力部11,単語の複数の読み情報と各々の混合度を示す単語辞書を記憶する単語辞書記憶部12,音声の特徴と読み情報を対応付けた音響モデルを記憶する音響モデル記憶部13,音響モデルから単語辞書の複数の読み情報に対応する音響モデル列を生成する音響モデル列生成部14,単語辞書の混合度をもとに複数の読み情報の音響モデル列を混合する音響モデル列混合部15,入力された音声データの音声特徴量を求め,混合した音響モデル列と照合し,単語辞書から該当する単語を検出する照合部16,および検出された単語を出力する結果出力部17を備える。
(もっと読む)
音声認識システム及び辞書生成装置
【課題】 ユーザが発話した時から音声認識が完了するまでに要する時間の短縮を図るとともに、多様な認識語彙の変化に対応可能とする。
【解決手段】 携帯プレーヤ5が端末装置3に装着されると、端末装置3は、携帯プレーヤ5に記憶されている楽曲データのTOCデータを携帯プレーヤ5から読み込んで遠隔サーバ7に送信する。一方、TOCデータを受信した遠隔サーバ7は、このTOCデータに関連する情報を読み込んでTOCデータと関連付けながら辞書データを生成した後、その生成された辞書データを端末装置3に送信する。そして、受信した辞書データの辞書保持メモリ3Dに保存する。これにより、ユーザが発話した時から音声認識が完了するまでに要する時間の短縮を図るとともに、多様な認識語彙の変化に対応することが可能となる。
(もっと読む)
動的音声認識辞書の生成方法及びその生成装置
【課題】音声による検索機能のうち、利用者の発話に呼応する機能が有効になるまでの時間を短縮できる「動的音声認識辞書の生成方法」を提供することである。
【解決手段】利用者からの音声認識辞書の生成要求を受付けたときに新規に辞書生成スレッドを作成するステップ(S11)と、前記辞書生成スレッドのタスクを辞書生成中タスクのリストに追加するステップ(S12)と、辞書生成が必要なタスクに対応するコマンドを目的毎に分類した優先処理中の検索カテゴリがあるか否かを判定するステップ(S14)と、所定の条件に応じて前記新規作成のスレッドの処理優先度を変更するステップ(S15〜S17)とを含む動的音声認識辞書の生成方法であって、前記利用者の発話があって動的生成の音声認識辞書を必要とするコマンドを認識したとき、所定の条件に応じてそのタスクの辞書生成スレッドの処理優先度を変更するステップを更に含む構成となる。
(もっと読む)
車両用情報端末及びプログラム
【課題】音声認識できなかった音声情報をその後の操作に基づいて音声認識に係る辞書に適切に記憶させ、音声認識できなかった音声情報を適切に音声認識させることができる車両用情報端末およびプログラムを提供する。
【解決手段】発話者の発した音声情報を認識処理し、認識結果が得られないと判断された場合、音声情報を認識不可音声情報として保持する。認識結果が得られないと判断された後に実行された操作に基づき、認識音声不可情報に対応すると推定される地図上の推定地点を特定し(S114)、推定地点に関する推定地点情報と認識不可音声情報とを関連付けて記憶させる(S118)。これにより、認識結果が得られなかった認識不可音声情報を、認識不可音声情報に対応すると推定される推定地点に関する推定地点情報と関連付けて記憶させることができるので、音声認識できなかった音声情報を適切に音声認識させることができる。
(もっと読む)
音声認識装置
【課題】音声認識辞書作成の処理負荷を軽減する「音声認識装置」を提供する。
【解決手段】接続されたポータブルオーディオプレイヤ22(PAP22)から、楽曲テキストとして「a」、「b」、「d」を含む楽曲リストが取得された場合(a)に、過去に生成したヨミ(発音データ)と楽曲テキストの対応を登録した全体ヨミデータに楽曲テキストが登録されている(b)、「a」、「d」については全体ヨミデータからヨミを取得して音声認識辞書に登録し(d)、全体ヨミデータに楽曲テキストが登録されていない「b」については、各テキストの各読み方を表すテキストを登録したヨミ生成テキスト辞書と、テキストのヨミを生成するTTS部12とを用いてヨミを生成して(c)、音声認識辞書に登録する(d)。また、生成した「b」のヨミを、対応する楽曲テキストとともに全体ヨミデータに登録する(e)。
(もっと読む)
重み付き有限状態トランスデューサ作成装置、作成方法及びプログラム
【課題】単語が追加された認識用WFSTの作成時間を短縮する。
【解決手段】音声認識に使用する重み付き有限状態トランスデューサ(認識用WFST)の作成において、状態遷移を追加するWFSTと追加しないWFSTとに分け、追加しないWFSTを予め合成化及び/又は最適化して基本WFSTとし、追加するWFSTはそのまま基本WFSTとし、それぞれ記憶しておく。状態遷移を追加する場合は、それぞれの基本WFSTの内の指定された基本WFSTに状態遷移を追加し、その後、追加したWFST及び追加しないWFSTに対し合成・最適化演算を行い、最終的な音声認識用WFSTを得る。
(もっと読む)
音声認識装置及び音声認識方法
【課題】音声認識対象となる単語の言い換え語が複数存在する場合でも、ユーザが意図する単語を選択することが可能な「音声認識装置及び音声認識方法」を提供すること。
【解決手段】音声認識装置は、外部機器又は媒体から音声認識の対象となる原テキストを入力する入力手段と、原テキストを解析して読みデータを生成する読みデータ生成手段と、音声認識辞書用の文字列に変換する変換規則が格納された記憶手段と、音声認識辞書と、入力手段を介して入力された原テキストを記憶手段に格納する制御手段とを有する。制御手段は、原テキストに対する言い換え語を生成し、言い換え語のうち原テキストと一致する言い換え語を特定可能な識別番号をその言い換え語に付与し、言い換え語を読みデータ生成手段に入力して読みデータを取得して、読みデータと認識対象の言い換え語とを関連付けて音声認識辞書に登録する。
(もっと読む)
画像処理装置、音声認識処理装置、音声認識処理装置の制御方法、およびコンピュータプログラム
【課題】発声する複数の語句の順序をユーザが意識しなくても、音声認識を正しく行うこと。
【解決手段】原稿の画像を読み取る画像読取装置を備えた画像処理装置に、マイク、音声を認識するための認識語句を記憶する認識辞書テーブルTB3、複数の所定の語句についての順序の異なる全ての組合せからなる複数の複合語句WFを生成する複合語句生成部34b、生成された複合語句WFを認識語句として認識辞書テーブルTB3に書き込む複合語句登録部34dと、複数の所定の語句を任意の順序で発声した発声語句に係る音声が入力されたときに、認識辞書テーブルTB3の中から当該発声語句と一致する複合語句WFを検索することによって当該音声を認識する音声認識処理部35、音声の認識の結果に基づいて画像に対する処理を実行する画像処理部を設ける。
(もっと読む)
情報検索装置,情報検索方法及びナビゲーションシステム
【課題】音声入力を利用した使い勝手のよい情報検索装置を提供する。
【解決手段】ユーザがタッチパネルなどにより入力した検索クエリを,音声認識語彙として使う。また,検索クエリを形態素情報や他のデータベースの情報により編集し,ユーザが発話しやすい音声認識語彙を提供する。
(もっと読む)
携帯電子機器
【課題】読み仮名の変更に伴う認識辞書の更新をユーザに意識させることなく行うことができる携帯電子機器を提供すること。
【解決手段】携帯電話機1は、所定の処理と編集可能な読み仮名とが対応付けられたアドレス帳データを記憶するアドレス帳DB51と、音声認識の結果と照合する読み仮名の選択肢を含む認識辞書データを、アドレス帳データと関連付けて記憶する認識辞書DB52と、音声認識結果と照合された読み仮名に対応する所定の処理を実行する実行部41と、アドレス帳データと認識辞書データとの読み仮名の差分を示す更新データを記憶する更新情報DB53と、アドレス帳データが更新された場合に、当該更新の内容を示す更新データを更新情報DB53へ記憶し、当該更新後の所定のタイミングで、更新データに基づいて認識辞書データを更新する更新部42と、を備える。
(もっと読む)
多言語音声認識装置及び多言語音声認識辞書作成方法
【課題】音声認識の対象言語が一つに設定されていても、テキスト本来の読みで認識することが可能な「多言語音声認識装置及び多言語音声認識辞書作成方法」を提供すること。
【解決手段】音声認識辞書の設定言語が所定の一つの言語に設定された多言語音声認識装置は、外部機器又は媒体から音声認識の対象となるテキストを入力する入力手段と、テキストが格納される記憶手段と、テキストの名称データを解析して読みデータを生成する複数の言語に対応したテキスト−読みデータ変換手段と、テキストの名称データの読みデータが格納された音声認識辞書と、制御手段とを有する。制御手段は、取得した名称データの言語種別を判定し、判定した言語種別に応じたテキスト−読みデータ変換手段により当該名称データに対する読みデータを生成し、当該生成した読みデータを設定言語に合わせた読みデータに変換して音声認識辞書に登録する。
(もっと読む)
楽曲データベース更新装置及び楽曲データベース更新方法
【課題】楽曲情報が不完全な場合に楽曲情報を自動的に補填して楽曲の検索を可能にする「楽曲データベース更新装置及び楽曲データベース更新方法」を提供すること。
【解決手段】楽曲データベース更新装置は、外部機器又は媒体から楽曲情報を入力する入力手段と、楽曲情報が格納される記憶手段と、作曲者名又はアーティスト名を格納した人名データベースと、入力手段を介して入力された楽曲情報を記憶手段に格納する制御手段と、を有する。制御手段は、取得した楽曲の楽曲情報に作曲者名又はアーティスト名の情報がなく、アルバム名の情報がある場合に、人名データベース内のいずれかの人名がアルバム名に含まれていると判定したとき、当該人名を当該楽曲の作曲者名又はアーティスト名として楽曲情報の作曲者又はアーティストに登録する。
(もっと読む)
音声認識装置、音声認識プログラム、および音声認識方法
【課題】短い語を表す複数の冗長な表現の音声データを認識できるようにする。
【解決手段】情報処理装置10は、音節数閾値以下の音節数を有する複数の短い語と、その短い語を説明するための、その短い語を含みその短い語の音節数より多い音節数をそれぞれ有する複数の冗長な音素データ列とを対応づけて格納する辞書データベース36と、音素認識部によって生成された冗長な音素データ列を認識し、さらに、その辞書データベースを検索して、その認識された冗長な音素データ列に対応する冗長な音素データ列に対して、その冗長な音素データ列に対応づけられた短い語を出力する音素データ認識部30と、を含む。
(もっと読む)
1 - 20 / 100
[ Back to top ]