
国際特許分類[G10L15/14]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 音声認識 (6,879) | 音声の識別または探索 (1,500) | 統計的モデルを用いるもの,例.隠れマルコフモデル[HMM] (175)
国際特許分類[G10L15/14]に分類される特許
1 - 10 / 175
音響モデル作成装置、音響モデル作成方法、及び音響モデル作成システム
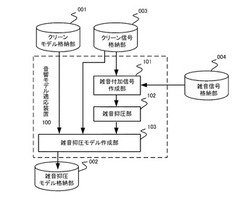
【課題】本発明が解決しようとする課題は、任意の雑音抑圧方式で作成された雑音抑圧信号にマッチした音響モデルを作る技術を提供することにある。
【解決手段】本願発明は、雑音の無い環境で収録した音声であるクリーン信号に、リアルタイムで収録している雑音信号を付加して雑音付加信号を作成し、前記作成された雑音付加信号から雑音を取り除いて雑音抑圧信号を作成し、前記作成した雑音抑圧信号を用いて計算したGMMを、前記クリーン信号を学習したモデルであるクリーンモデルのGMMと入れ替えることで、雑音抑圧モデルを作成することを特徴とする。
(もっと読む)
単語識別方法、単語識別装置、及びコンピュータ可読コード

【課題】原則として無制限の数の単語を認識することを可能とする。
【解決手段】
本発明は、音声認識、例えば連続する音声中の単語を認識するためのシステムを取り扱う。莫大な数の単語、原則として無制限の数の単語を認識することが可能な音声認識システムが開示される。音声認識システムは、単語グラフ中の最良の経路を導き出すための単語認識装置を有し、単語はその最小の経路に基づいて音声に割り当てられる。音素言語モデルを単語グラフの各々の単語に適用することによって、単語スコアが得られる。さらに、本発明は、音声ブロックから単語を識別する装置及び方法を取り扱い、並びに当該方法を実施するためのコンピュータ可読コードに関する。
(もっと読む)
音響モデル処理装置、音響モデル処理方法および音響モデル処理プログラム
【課題】雑音を反映したガウス分布の識別性を、少ない計算量で向上させることができる音響モデル処理装置を提供する。
【解決手段】フレーム集合導出手段92は、雑音を含む音声のデータである雑音重畳データであって、個々のフレームに関して、フレームに対応する音素の特徴を示すガウス分布の識別情報が付加された雑音重畳データを用いて、識別不能ガウス分布の識別情報が付加されたフレームの集合を、識別不能ガウス分布特定手段91によって特定された識別不能ガウス分布毎に導出する。変換行列算出手段93は、フレーム集合導出手段92によって導出されたフレームの集合を、フレームの集合間の分離度を最も高める空間に射影する変換行列を算出する。パラメータ追加手段94は、雑音重畳データを変換行列で変換した結果得られるデータの平均および分散を、音響モデル内のガウス分布の平均および分散に追加する。
(もっと読む)
雑音抑圧装置、方法及びプログラム
【課題】音声信号の存在有無に関わらず、雑音信号を学習データとして利用し、より多くの雑音信号の変化や特徴を雑音信号の確率モデルに反映することができ、より正確に雑音信号を抑圧することができる雑音抑圧技術を提供する。
【解決手段】音響信号の音響特徴を抽出する。雑音を含まない音声信号の確率モデル(以下「音声モデル」という)と音響信号の音響特徴とを用いて、雑音信号を推定し、推定した雑音信号を学習データとして雑音信号の確率モデル(以下「雑音モデル」という)を教師無し学習する。雑音モデルを用いて音響信号の雑音信号を抑圧する。
(もっと読む)
話者判別装置、話者判別プログラム及び話者判別方法
【課題】話者の判別を簡易かつ正確に行うことを課題とする。
【解決手段】話者判別装置50は、各々の話者に配置される複数のマイクから各々の音声データを取得する。さらに、話者判別装置50は、取得された音声データを所定の区間のフレームにフレーム化する。さらに、話者判別装置50は、第1の確率モデルに基づいて、フレームが有声音領域または無声音領域のいずれであるかを識別する。さらに、話者判別装置50は、各音声データにおける同一区間のフレームで有声音領域が重複して識別された場合に、当該同一区間で有声音領域と識別されたフレームのうち最大のエネルギーを持つフレームの識別結果を有効化する。さらに、話者判別装置50は、第2の確率モデルに基づいて、有効化された後のフレームの識別結果から各々の音声データにおける発話領域および沈黙領域を識別する。
(もっと読む)
音響モデル学習装置及びコンピュータプログラム
【課題】SVMを用いた音響モデルの学習装置を提供する。
【解決手段】学習装置は、学習データ記憶部102と、各音素の内部状態のSVMパラメータを記憶するSVMパラメータ記憶部116と、学習データの各々と、対応する音響モデル内の内部状態との間を初期アライメントする初期アライメント処理部110と、初期アライメント済の学習データを記憶する、書換え可能な記憶部112と、アライメント済の学習データを用いて音響モデルの各内部状態のSVMの学習を行なうアライメント処理部118と、学習データの各々について、SVM学習部114により学習された音響モデルを用いて各音響モデル内の内部状態とアライメントを行ない、記憶部112の学習データを更新する学習データ更新部122と、終了条件が成立するまで、SVM学習と学習データのアライメントとを繰返し実行させる比較部126とを含む。
(もっと読む)
音源パラメータ推定装置と音源分離装置とそれらの方法とプログラム
【課題】音源モデルパラメータが予め与えられていなくとも音源パラメータと一緒に音源モデルパラメータも推定できる音源パラメータ推定装置を提供する。
【解決手段】音源モデルパラメータ更新部は、音源パワー特徴量と音源パワーパラメータと音源占有度と、音源モデル記憶部に記憶された音源パワーパラメータの事前確率密度関数と音源パワー特徴量のモデルとを入力として音源モデルパラメータを更新する。音源占有度更新部は、音源位置特徴量と音源パワー特徴量と各音源の更新された音源パワーパラメータと音源位置パラメータと、音源モデルパラメータと、音源モデル記憶部に記憶された音源パワーパラメータの事前確率密度関数と音源パワー特徴量のモデルとを入力として各音源の音源占有度を更新する。
(もっと読む)
音声認識用WFST作成装置とそれを用いた音声認識装置と、それらの方法とプログラムと記憶媒体
【課題】状態数、状態遷移数を削減したサイズの小さな音声認識用WFSTを作成する音声認識用WFST作成装置と、その音声認識用WFSTを用いた音声認識装置を提供する。
【解決手段】音素モデル構造表作成部は、音響モデルの要素である音素環境と状態位置と状態数で特定されるHMM状態にHMM状態IDを付与し、そのHMM状態IDの表を音素モデル構造表として作成して音素モデル構造表記憶部に記憶する。構造合致照合部は、複数の音響モデル間において同一の音素環境と状態位置と状態数である複数の状HMM態IDを併合させて新たに併合したHMM状態IDを付与し、そのHMM状態IDと対応する音素環境と状態位置と状態数とから成る表になるように音素モデル構造表を更新する。音響モデルWFST作成部は、その併合されたHMM状態IDを入力とし、出力を音素環境とする併合音響モデルWFSTを作成する。
(もっと読む)
音響モデル生成装置、音声翻訳装置、音響モデル生成方法
【課題】従来、音響モデルの構築のために、多数の話者が、予め決められた文章を読み上げるなどの作業を行っていた。
【解決手段】音声ファイルを含む1以上のファイルを格納している1以上のサーバ装置から1以上の音声ファイルを取得する音声ファイル取得部と、1以上の音声ファイルから、予め決められた条件を満たすデータであり、音響モデルの構築のために使用しないデータを除いた1以上の音声データを取得する音声データ取得部と、取得された1以上の各音声データを音声認識し、1以上の文字列を有する1以上の文字列情報を取得する音声認識部と、1以上の各音声データと各音声データに対応する1以上の各文字列情報とを有する1以上の音声情報から音響モデルを生成する音響モデル生成部と、音響モデルを蓄積する音響モデル蓄積部とを具備する音響モデル生成装置により、自動的に音響モデルが構築できる。
(もっと読む)
音声処理システム及び方法
【課題】学習とテストとの間の話者ミスマッチ及び環境ミスマッチを解決する音声処理。
【解決手段】音響モデルをミスマッチした音声入力に適応させる。適応させることは、話者の環境と、音響モデルがその下で学習された環境との間の相違を主としてモデリングするためのミスマッチ関数fと、ミスマッチした話者入力の話者の間の相違を主としてモデリングするための話者変換Fとを使用して、y=f(F(x,v),u)となるように、ミスマッチした話者入力からの音声を、音響モデルを学習するために使用される音声に関連付けることと、u及びvを同時に推定することを含む。ここで、yは、ミスマッチした話者入力からの音声を表し、xは、音響モデルを学習するために使用される音声であり、uは、環境の変化をモデリングするための少なくとも一つのパラメータを表し、vは、話者の間の相違をマッピングするために使用される少なくとも一つのパラメータを表す。
(もっと読む)
1 - 10 / 175
[ Back to top ]