
国際特許分類[G10L15/18]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 音声認識 (6,879) | 音声の識別または探索 (1,500) | 自然言語モデルを用いるもの (322)
国際特許分類[G10L15/18]に分類される特許
1 - 10 / 322
音声データ検索システムおよびそのためのプログラム
【課題】
音声データ検索システムにおいて、検索結果の正解/不正解の判定を容易に行うことができるようにする。
【解決手段】
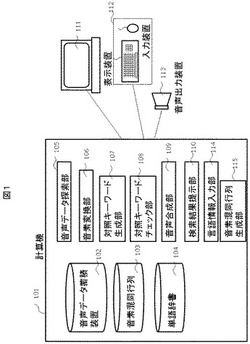
音声データ検索システムにおいて、キーワードを入力する入力装置112と、入力された前記キーワードを音素表記へ変換する音素変換部106と、音素表記のキーワードを元に音声データ中で当該キーワードが発話された個所を検索する音声データ探索部105と、ユーザごとの音素混同行列103に基づいて、ユーザが聴取混同する可能性のある対照キーワードの集合を生成する対照キーワード生成部107と、前記音声データ探索部105からの検索結果および前記対照キーワード生成部107からの前記対照キーワードをユーザへ提示する検索結果提示部110を備える。
(もっと読む)
認識装置、認識プログラム、認識方法、生成装置、生成プログラムおよび生成方法

【課題】精度良く音声の認識を行うこと。
【解決手段】認識装置20は、記憶部24と、第一の算出部26aと、第二の算出部26bと、決定部26cとを有する。記憶部24は、文章に含まれる単語と単語の文章内の位置を示す位置情報とを記憶する。第一の算出部26aは、入力された音声信号と、記憶部24に記憶された複数の単語を接続した文字列の読み情報とを比較して、類似度を算出する。第二の算出部26bは、記憶部24に記憶された各単語の位置情報に基づいて、接続した複数の単語間の近さを示す接続スコアを算出する。決定部26cは、類似度および接続スコアに基づいて、音声信号に対応する文字列を決定する。
(もっと読む)
単語識別方法、単語識別装置、及びコンピュータ可読コード
【課題】原則として無制限の数の単語を認識することを可能とする。
【解決手段】
本発明は、音声認識、例えば連続する音声中の単語を認識するためのシステムを取り扱う。莫大な数の単語、原則として無制限の数の単語を認識することが可能な音声認識システムが開示される。音声認識システムは、単語グラフ中の最良の経路を導き出すための単語認識装置を有し、単語はその最小の経路に基づいて音声に割り当てられる。音素言語モデルを単語グラフの各々の単語に適用することによって、単語スコアが得られる。さらに、本発明は、音声ブロックから単語を識別する装置及び方法を取り扱い、並びに当該方法を実施するためのコンピュータ可読コードに関する。
(もっと読む)
音声認識装置および音声認識方法
【課題】音声認識処理で間違って認識された文字列に対する変換候補を、上記音声認識処理とは異なる根拠に従って決定すること。
【解決手段】音声認識装置は、音声データを取得する音声データ取得部と、音響モデルおよび第1言語モデルを参照して、音声データに対する音声認識処理をおこない、その認識結果を示す認識文字列を生成する音声認識部と、認識文字列に含まれる一部の文字列を、変換対象文字列として決定する変換対象文字列決定部と、認識文字列において、決定された変換対象文字列の前または後に接続された文字列を、参照文字列として決定する参照文字列決定部と、第2言語モデルを参照して、決定された参照文字列との接続関係が示されている文字列を、変換対象文字列を変換する候補の変換候補文字列として決定する変換候補文字列決定部と、決定された変換候補文字列を出力する出力部とを備える。
(もっと読む)
音声データ書き起こし用WEBサイトシステム
【課題】ライブストリーミングのように一時停止ができない動画コンテンツまたは音声コンテンツ中の音声を、不特定多数のユーザが協調してリアルタイムに書き起こすことが可能な音声データ書き起こし用WEBサイトシステムを提供する。
【解決手段】判定部22は、断片テキストデータの入力時刻から所定の時間間隔T遡った所定の時間期間T内に配信された期間音声データPADを音声データ記憶部14から取得して、期間音声データPADの中に断片音声パターンPAPと音響的に適合する音声パターンとなる音声データ部分があるか否かを判定する。データ置換部23は、判定部22が音響的に適合すると判定した音声パターンとなる部分に対応する音声認識結果記憶部15に記憶されているテキストデータの該当テキストデータ部分を断片テキストデータまたは単語断片テキストデータで置き換える。
(もっと読む)
音声認識装置および音声認識プログラム
【課題】話題に応じて、高精度な音声認識結果を得る。
【解決手段】音声データに基づいて音響特徴量を算出する音響分析部50と、音響特徴量と発音ネットワークに対応する音響モデルとに基づき言語表現ごとの音響スコアを求め、また言語スコアを求め、音響スコアと言語スコアとに基づいて正解候補単語列を探索して認識結果テキスト情報を生成する正解単語探索部60と、話題情報から認識結果テキスト情報に対応する発話対応テキストを抽出する話題トラッキング部80と、話題情報から、発話対応テキストを含む発話相当付近テキストを抽出し、発話相当付近テキストに関連する関連テキスト情報をテキスト情報源2から取得し、言語モデルを関連テキスト情報に基づき適応化して更新する言語モデル適応化部90と、更新した際に適応化言語モデルに基づいて発音ネットワークおよび言語スコアメモリを更新する更新部62とを備える。
(もっと読む)
音声認識装置
【課題】ロバスト性が高く、誤認識率を低減させた音声認識装置を提供すること。
【解決手段】音声認識装置は、音素系列のパターンに制限を与える言語モデル22と、音素ラベルを記憶する単語音素ラベル辞書21と、音素ラベルを変換するルールを記憶するラベル変換ルール辞書23と、標準音声パターンを生成する音響モデル24と、を有し、音声を特徴量化する音響特徴量変換部12と、音響特徴量変換部により特徴量化された音声について、言語モデル22と、単語音素ラベル辞書21と、ラベル変換ルール辞書23とを参照して音素ラベルに変換する音素ラベル変換部13と、音素ラベル変換部13で変換された音素ラベルを、音響モデル24により標準音声パターンに変換し、音響特徴量変換部12で特徴量化された音声との類似度を計算する類似度計算部14と、類似度計算部14による計算結果から入力文章を判定する最尤文法決定部15と、を備える。
(もっと読む)
単語関連度テーブル作成装置とその方法と音声認識装置とプログラム
【課題】単語ペアの単語間の関連度の計算を改善した関連度を計算する単語関連度テーブル作成装置と、その単語関連度テーブルを用いた音声認識装置の提供。
【解決手段】単語関連度計算部は、生起回数補正手段と、検定値計算手段と、補正関連度計算手段と備え、単語ペア(wi,wj)の生起回数がr-1回の生起回数を、0では無い小さな値(r-1)Nr/Nr-1に補正すると共に、単語ペア(wi,wj)が共起する回数と各単語が単独で発生する回数との積の差を統計的に検定するt値を求め、t値が大きな単語ペア(wi,wj)の関連度を、補正した生起回数に基づいて再計算する。その結果、共起する回数の少ない単語ペアの関連度は小さな値、共起する回数の多い単語ペアの関連度は大きな値とすることが出来る。
(もっと読む)
音声認識方法とその装置とプログラム
【課題】認識誤り単語を除外して認識スコアを再計算する音声認識方法を提供する。
【解決手段】この発明の音声認識方法のNベスト候補スコア再計算過程は、過去発話単語の2単語ペアの関連度の平均値である過去発話関連度と、未来発話単語の2単語ペアの関連度の平均値である未来発話関連度とを求め、Nベストの全順位の現在発話単語と全ての過去発話単語の単語ペアの過去・現在関連度と、Nベストの全順位の上記現在発話単語と全ての上記未来発話単語の単語ペアの現在・未来関連度とを求め、上記過去発話関連度と閾値を比較すると共に上記未来発話関連度と閾値とを比較することで上記過去発話単語集合内の関連性と上記未来発話単語集合内の関連性を評価し、関連性がある場合は上記過去・現在関連度と上記現在・未来関連度の値を考慮した認識スコアを再計算する。
(もっと読む)
音響モデル生成装置、音響モデル生成方法及び音響モデル生成用コンピュータプログラム
【課題】同一の読みとなる文字列を含む複数の単語のうち、その文字列について異なる発音がなされる可能性のある単語についてのみ、その異なる発音に対応する音響モデルを生成可能な音響モデル生成装置を提供する。
【解決手段】音響モデル生成装置(1)は、少なくとも一つの単語の読みを表す発音列と、読み替えがなされる可能性のある少なくとも一つの変換候補の変換前の読みと変換後の読みの組とを記憶する記憶部(3)と、発音列から変換候補列を抽出する変換候補列抽出部(11)と、変換候補列に含まれる単位音ごとの発音明瞭度に応じた変換候補列明瞭度が異なる発音がなされるレベルである場合、発音列中のその変換候補列の読みを対応する変換後の読みに置換することにより、修正発音列を生成する発音列修正部(12)と、発音列及び修正発音列に対応する音響モデルをそれぞれ生成する音響モデル生成部(13)とを有する。
(もっと読む)
1 - 10 / 322
[ Back to top ]