
国際特許分類[G10L21/04]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 他の可聴信号,または不可聴信号への音声信号変換処理,例.特性や明瞭性を修正するための視覚,触覚 (2,017) | 時間圧縮または拡張 (666)
国際特許分類[G10L21/04]に分類される特許
661 - 666 / 666
音声合成装置
声質の自由度が広く良い音質の合成音声をテキストデータから生成する音声合成装置を提供する。音声合成装置は、音声合成DB(101a,101z)と、テキスト(10)を取得するとともに、音声合成DB(101a)から、テキスト(10)に含まれる文字に対応した声質Aの音声合成パラメタ値列(11)を生成する音声合成部(103)と、音声合成DB(101z)から、テキスト(10)に含まれる文字に対応した声質Zの音声合成パラメタ値列(11)を生成する音声合成部(103)と、声質A及び声質Zの音声合成パラメタ値列(11)から、テキスト(10)に含まれる文字に対応した、声質A及び声質Zの中間的な声質の合成音声を示す中間的音声合成パラメタ値列(13)を生成する音声モーフィング部(105)と、生成された中間的音声合成パラメタ値列(13)をその合成音声に変換して出力するスピーカ(107)とを備える。 (もっと読む)
ディスク・ジョッキーのためのデジタル・ミュージック・システム
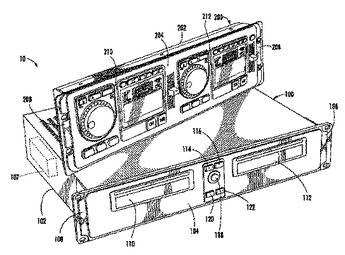
ディスク・ジョッキーのためのデジタル・メディア・システム(10)は、デジタル・ストレージ・ドライブ(107)を含む。ミュージック・システム(10)は、2つのメディア・リーダ(110、112)を有することが好ましい。オーディオ・ファイルについては、デジタル・ストレージ・ドライブ(107)への録音と、そこからの再生とを同時に行うことができる。デジタル・ストレージ・ドライブ(107)のデジタル・データを管理するためのオペレーティング・システムが含まれる。ミュージック・システム(10)はまた、出力、ならびにメディア・リーダ(110、112)と、デジタル・ストレージ・ドライブ(107)と、オペレーティング・システムと、出力とをコントロールするためのコントロール・ユニット(200)を含む。コントロール・ユニット(200)は、第1および第2のインターフェース(210、212)を有する。インターフェース(210、212)は、メディア・リーダ(110、112)およびストレージ・ドライブ(107)からのデジタル・データを1つの信号へと独立して選択的にミキシングし、出力を通じてその信号を回送することができる。
 (もっと読む)
(もっと読む)
音声学と音韻論の学習と理解による,言語習得を容易にするための方法,システム,プログラム,データの集合
この技術は,言語学習を容易にするということを目指しており,全般的に音韻論と音声学の習得を容易にするためであり,特には韻律の習得を容易にするためである.そのために,学習者は目標言語のリズムや韻律構造をよりよく受け取るために訓練される.その訓練は,学習者が目標言語の韻律特徴をよりよく特定させてくれ,その特定の実現能力を発達させてくれる,いくつかの簡単にする方法の助けを借りて,決まった聴覚再生を聞くことからなっている. (もっと読む)
音声信号強化方法及び装置、目的信号検出器、音響システム
音声信号は、信号の低音成分の高調波及び/又はサブ高調波のような、強化信号を付加することにより強化される。弱い出力又は会話中に不要な強化信号を避けるため、音声信号の目的音声信号成分を周波数範囲で監視し、目的音声信号が検出された場合のみ強化信号を付加することを提案する。目的音声検出器は、周波数範囲の主な周波数に等しい周波数を有するサイン及びコサイン信号生成器を有する。  (もっと読む)
(もっと読む)
信号処理装置
データ圧縮を行う信号処理装置において、間引き回路1は、入力されるPCMデータを間引いて間引きデータを生成する。例えば、PCMデータ(元データ)のサンプリングレートfsがfs=10Hzのとき、fs=1Hzの間引きデータを生成する。判定回路2は、次式 TOTAL1=|X(n)−X(n−1)|+|X(n−1)−X(n−2)|+・・・+|X(n−8)−X(n−9)|に基づいて、ifTOTAL1>C1のときには入力PCMデータを選択し、その他では間引きデータを選択するように、選択回路4を制御する。選択されたデータ及び前記判定回路2の判定結果情報はメモリ3に書き込まれる。従って、簡単な回路構成で、且つ元データの持つ必要な情報を失わずに、元データのデータ圧縮が行われる。 (もっと読む)
生前中に人の声の波長、声紋等を分析し記録して、その方の死後故人と電話で会話が出来るシステム。

[課題] 生前中の人の声の波長、声紋等を分析し記録して、その方の死後故人と電話で会話が出来るシステム。
【構成】 電話の声より口調、声のトーン及び声質、声の抑揚、話す速度、口癖等を分析して、再現できるようにする(図1(1))。再現した声より応答事例を作成する(図1(2))。アクセスすると自動で会話の返答をする。(図1(3))。
(もっと読む)
661 - 666 / 666
[ Back to top ]