
Fターム[5B045DD03]の内容
マルチプロセッサ (2,696) | メモリシステム、ファイル管理 (299) | 共有メモリ、専用メモリ (190) | 領域管理 (78) | CPU対応の領域を設けるもの (39)
Fターム[5B045DD03]に分類される特許
1 - 20 / 39
情報処理装置、情報処理方法及び制御プログラム
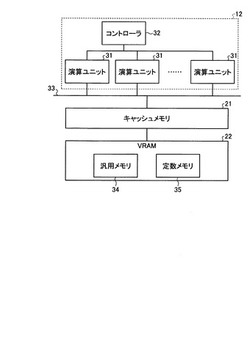
【課題】メモリに対するアクセス時間を低減し、ひいては、実行パフォーマンスを向上する。
【解決手段】実施形態の情報処理装置は、並列処理が可能な複数のプロセッサと、前記複数のプロセッサで共有されるメモリと、を備えている。そして、割当手段は、メモリのアクセス範囲が予め記述可能とされるとともに複数のスレッドで構成されたワークグループを、それぞれ記述されたアクセス範囲を参照して複数のプロセッサのいずれかに実行させるために割り当てる。
(もっと読む)
データ中継制御装置、リンク間転送設定支援装置およびリンク間転送設定方法

【課題】共有メモリ方式のサイクリック伝送されているネットワークが複数存在する制御システムで、一つのネットワークの通信ノードから別のネットワークの通信ノードへ共有メモリ領域のデータを転送するリンク間転送の設定を人手によらず設定することができるデータ中継制御装置を得ること。
【解決手段】複数のネットワークにそれぞれ接続される複数のノード31,32と、複数のノード31,32間を通信路で接続するベースと、リンク間転送設定に基づいて、データを一のネットワークに接続されるノードから前記他のネットワークに接続されるノードに転送するリンク間転送制御部35と、プログラムで使用されるメモリ領域に付されたラベルと、ラベルが演算前にデータを格納する動作か、演算後のデータの行き先となる動作かを示すフラグ情報と、を有するラベル割付情報に基づいて、リンク間転送設定を生成するリンク間転送設定生成部33と、を備える。
(もっと読む)
処理装置、及び、処理装置の起動方法
【課題】複数のCPUがメモリーを共有する構成を、より単純な回路構成によって実現する。
【解決手段】複数のCPU121、122と、これら複数のCPU121、122により共有されるROM130とを備え、少なくともいずれかのCPUがメインCPUとして起動し、メインCPU用の所定のアドレスに基づいてROM130から起動プログラムを読み出した後、他のCPUを起動させる制御を行い、メインCPUにより起動されたCPU122は、サブCPU用の所定のアドレスに従ってROM130から起動プログラムを読み出す。
(もっと読む)
データ処理装置及びデータ処理方法
【課題】 データ処理の領域を分割して複数のプロセッサに並列処理させる際に、分割の最小単位を小さくする。
【解決手段】 データ処理装置が、第一のデータ処理を複数のプロセッサに並列処理させ、並列処理されたデータを記憶部に格納する際に、複数のプロセッサのデータキャッシュのサイズに基づいて記憶部のアドレスを変換して格納する。そして、記憶部に格納されたデータを読み出し、読み出したデータに対して第二のデータ処理を行う。
(もっと読む)
プロセッサ、マルチプロセッサシステムおよびメモリ制御方法
【課題】ローカル命令メモリのサイズを実質的に拡大する形態でローカル命令メモリを各プロセッサ間で共有できるマルチプロセッサシステムにおけるプロセッサを提供する。
【解決手段】第1CPU100は、メモリ共有モード設定レジスタ107に格納された情報を参照することで、第1CPU100が命令フェッチを行うアドレスが、ローカル命令メモリ先頭アドレスレジスタ103とローカル命令メモリ終了アドレスレジスタ104とで定義される領域内であるか、または、共有命令メモリ先頭アドレスレジスタ105と共有命令メモリ終了アドレスレジスタ106とで定義される領域内であるかを判定し、その判定の結果に基づいてセレクタ102を制御することで、命令メモリ101と命令メモリ201とを切り替え、切り替え後の命令メモリから命令をフェッチして実行する。
(もっと読む)
並列処理システム及び並列処理システムの動作方法
【課題】複雑な制御機能を設けることなく、処理性能を向上させることのできる、並列処理システム及び並列処理システムの動作方法を提供する。
【解決手段】並列処理システムは、ネットワークを介して互いにアクセス可能に接続され、複数の処理を分散して実行する、複数の計算機を具備する。前記複数の計算機の各々は、割り当てられた処理を実行する演算処理装置と、第1領域及び第2領域を有する、ローカルメモリ群と、入出力制御回路とを備える。前記演算処理装置は、第1期間において、前記第1領域をアクセス先アドレスとして処理を実行し、前記第1期間に続く第2期間において、前記第2領域をアクセス先アドレスとして処理を実行する。前記入出力制御回路は、前記複数の計算機間で通信を行なうことにより、前記ローカルメモリ群に格納されたデータを最新のデータになるように更新する、更新部を備える。前記更新部は、前記第2期間において、前記第1領域に格納されたデータを更新するように構成されている。
(もっと読む)
データ転送制御装置及びプログラム
【課題】共有メモリのサイズに制限があっても、異なるOS間で効率的にデータ転送を行う。
【解決手段】第1OSから第2OSで管理するハードウェア・デバイスへデータを転送するためのデータ転送命令が第1OSに対して発行された場合に、該データ転送命令による転送対象のデータを、第1OS及び第2OSが共有して使用する共有メモリの使用可能なサイズよりも小さいサイズの複数個の分割データに分割して、該共有メモリに書き込み、、該共有メモリに書き込まれた分割データが第2OSにおいて読み出されて上記ハードウェア・デバイスに転送されるように、上記分割データが共有メモリに書き込まれる毎に、該分割データのデータサイズを転送サイズとして指定した分割データ転送コマンドを生成して第2OSに対して発行する。
(もっと読む)
電子機器及びメモリの初期化方法
【課題】製造コストを増大させることなく、メモリの初期化を高速に行い、提供するサービスの遅延を防ぐこと。
【解決手段】第1のCPU101は、第2のメモリ104に対する電源の供給が開始された場合においてデータ送信要求を受けた際に、各々のメモリブロックを所定の順番で特定するメモリブロック識別子を順次生成し、所定の順番に従ってメモリブロックにデータを書き込むとともにメモリブロック識別子を転送管理テーブル205に書き込む。第2のCPU103は、転送管理テーブル205から順次読み出したメモリブロック識別子により特定される所定の順番に従って、メモリブロックに書き込まれたデータを順次読み出すとともに、データを読み出したメモリブロックを特定するメモリブロック識別子をメモリ管理テーブル203に順次書き込むことにより第2のメモリ104を初期化する。
(もっと読む)
マルチプロセッサシステム及びメモリアクセス制御方法
【課題】プロセッサエレメントごとにアクセス可能なメモリ領域を設定できるようにすること。
【解決手段】マルチプロセッサシステムは、共有バスを介して互いに接続された複数のプロセッサノードを備え、当該複数のプロセッサノードは、それぞれ、プロセッサエレメントと、当該プロセッサエレメントによる物理メモリに対するアクセスを制御するメモリ管理ユニットとを備えている。
(もっと読む)
ヘテロジニアス処理ユニット間での不均一メモリアクセスのためのチップセットサポート
【課題】第2のプロセッサに関連付けられたメモリに第1のプロセッサがアクセスすることを可能にするための方法を提供すること。
【解決手段】この方法は、第1のプロセッサから、NUMAデバイスのためのMMIOアパーチャを含む第1のアドレスマップを受け取るステップと、第2のプロセッサから、ハードウェアデバイスのためのMMIOアパーチャを含む第2のアドレスマップを受け取るステップと、第1のアドレスマップと第2のアドレスマップを組み合わせることによってグローバルアドレスマップを生成するステップと、第1のプロセッサからNUMAデバイスに送られたアクセス要求を受け取るステップと、第1のアクセス要求と変換テーブルとに基づいて、メモリアクセス要求を生成するステップと、グローバルアドレスマップに基づいて、メモリアクセス要求をメモリにルーティングするステップとを含む。
(もっと読む)
ハードウェアデバイスをヘテロジニアス処理ユニット間でバインドし移行するためのチップセットサポート
【課題】コンピュータシステム内に含まれる他のプロセッサとの競合を引き起こすことなしにハードウェアデバイスに対する、プロセッサによるアクセスを可能とする方法をていきょうすること。
【解決手段】この方法は、第1のプロセッサから第1のアドレスマップを、また第2のプロセッサから第2のアドレスマップを受け取るステップであり、各アドレスマップは、プロセッサがアクセスするように構成されているハードウェアデバイスのセットのためのメモリマップド入出力アパーチャを含む、ステップと、第1と第2のアドレスマップを組み合わせることによってグローバルアドレスマップを生成するステップと、第1のプロセッサから第1のアクセス要求を受けるステップと、グローバルアドレスマップ内に含まれるアドレスマッピングに基づきハードウェアデバイスに第1のアクセス要求をルーティングするステップとを含む。
(もっと読む)
マルチコアプロセッサ,制御方法および情報処理装置
【課題】特別な管理や制御を行なうことなく、効率的にプロセッサコアにタスクを処理させることができるようにする。
【解決手段】第1のプロセッサコア11が、第1のタスクの処理に際して第2のタスクに関する処理要求を行なう際に、第1のプロセッサコア11により用いられるメモリ領域31に第2のタスクに関する情報を格納するとともに、複数のプロセッサダイ10にそれぞれそなえられた各第2のプロセッサコア12に対して割込通知を行ない、割込通知を受けた第2のプロセッサコア12が、第2のプロセッサコア12と同一のプロセッサダイ10上にそなえられた第1のプロセッサコア11によって用いられるメモリ領域31に対してそれぞれアクセスを行なう。
(もっと読む)
光トランシーバ
【課題】 プログラムのセットアップ時の処理時間を短縮することができると共にコストを低減することもできる光トランシーバを提供する。
【解決手段】 光トランシーバ1Aでは、LD11a〜11dを含むTOSA101と、ROSA107と、サブCPU5A及び5Bと、メインCPU3と、サブCPU5A及び5Bのためのアプリケーションプログラムが格納されており、サブCPU5A及び5BとSPIによって接続されているEEPROM20と、を備えた光トランシーバであって、メインCPU3は、サブCPU5A及び5Bが該光トランシーバの起動時にSPIを介して順次にEEPROM20からアプリケーションプログラムを読み出し、LD11a〜11dから各光出力信号が同時に出力開始されるようにサブCPU5A及び5Bに発光制御信号を送出する
(もっと読む)
マルチプロセッサシステム及びそれを搭載した流体吐出装置
【課題】マルチプロセッサシステムにおいて、プロセッサ間のメッセージのやりとりをより確実に行う。
【解決手段】プリンタ20は、メッセージボックス38を有するマルチプロセッサシステム30を搭載している。このマルチプロセッサシステム30では、2以上のプロセッサのうち送信側のプロセッサと受信側のプロセッサとが行列状のアドレスに対応付けられており、このアドレスに送信側のプロセッサから受信側のプロセッサへのメッセージを格納可能であるメッセージボックス38を備えており、このメッセージボックス38にメッセージが書き込まれると受信側のプロセッサへ割込信号生成回路39が割込信号を出力する。このように、送信側と受信側とが行列状のアドレスに対応付けられているため、送信者・受信者の関係を把握しやすく、メッセージが書き込まれたら受信側へ知らせるため、受信側でメッセージの有無を把握しやすい。
(もっと読む)
ノード装置
【課題】サイクリックマップが重複せず、サイクリック通信のシステムに柔軟性を持たせることができるサイクリック通信のノード装置を得ることを目的とする。
【解決手段】参入するノード2のサイクリックマップ制御部4は、ホスト1から送信サイズ値の指定のみを受けた際に、他ノード2のシステムサイクリックメモリ7に書き込まれたサイクリックマップ情報を受信し、これを参照してユーザーサイクリックメモリ5の空き領域を検索し、指定された送信サイズ値のエリアをユーザーサイクリックメモリ5の空き領域の先頭から割り付けるとともに、システムサイクリックメモリ7に自ノードのサイクリックマップ情報を書き込み、他ノード2に通信し、他ノード2のサイクリックマップ制御部4は、通信されたサイクリックマップ情報を参照して自ノード2のユーザーサイクリックメモリのサイクリックマップの設定変更をするようにした。
(もっと読む)
マルチプロセッサシステムにおけるデータ同期方法及びマルチプロセッサシステム
【課題】マルチプロセッサシステムにおいて、データの整合性を保証したデータ共有を実現する。
【解決手段】複数のプロセッサと共有メモリから構成され、共有メモリ領域は各プロセッサに割り当てられて領域とプロセッサ間のメッセージ交換を行うための通知メモリ領域とを含んでおり、第1のプロセッサが第2のプロセッサの割り当てメモリ領域内のデータを取得する場合には、データ取得要求を通知メモリ領域に書き込む。通知メモリ領域内のデータ取得要求を監視することでデータが要求されたことを確認でき、その場合は、割当領域間でデータのコピーを行うとともに、コピーが完了したことを示す完了通知を通知メモリ領域に書き込む。データを要求した側のプロセッサは、通知メモリ領域内の完了通知を確認することで取得したデータを利用した処理を行う。
(もっと読む)
プログラム実行システム
【課題】本発明の課題は、組み込みヘテロマルチプロセッサシステム上でのプロセッサ間で連携動作する中間コードを用いるアプリケーションプログラムを高速に実行可能とすることを目的とする。
【解決手段】上記課題は、複数のプロセッサを含み、前記複数のプロセッサ上で動作可能な中間コードを実行するプログラム実行環境を備えたプログラム実行システムであって、前記複数のプロセッサ夫々に専用の複数のプロセッサ専用メモリと、前記複数のプロセッサ間で共有される前記中間コードによって操作される共有オブジェクトを格納するプロセッサ間共有メモリとを備え、前記複数のプロセッサの各々は、前記共有オブジェクトを指定する名前と前記プロセッサ間共有メモリ内の該共有オブジェクトの実体とを対応させることによって、前記複数のプロセッサ専用メモリの各々と該プロセッサ間共有メモリ間にて該共有オブジェクトを読み出し及び書き込みする読出書込機能を実行することにより達成される。
(もっと読む)
マルチCPU装置及びそのブート処理方法
【課題】マルチCPU装置及びそのブート処理方法に関し、汎用性の高いマルチCPU構成のブート方式を可変にし、安価で汎用性の高いブート処理を可能にする。
【解決手段】CPU11,12の起動順序を含むCPUのブート方式の情報をブートパターンとして複数種類ブートパターンテーブルに格納し、ブート方式切替え設定部15により1つのブートパターンを選択してブート方式制御部14に設定し、CPUバス制御部13は該ブートパターンにより指定される起動順序で、ブートプログラムを不揮発性メモリ18から読み出すバスアクセス権をCPUに与える。アドレス変換部17はCPUから出力されるアドレス信号をブートパターンに従って不揮発性メモリのブートプログラム格納領域のアドレス信号に変換する。データ幅変換部16は不揮発性メモリから読み出したデータ信号をブートパターンに従うデータバス幅に変換してCPU11,12に出力する。
(もっと読む)
マルチプロセッサ処理システム
【課題】 OSプログラムを短時間で起動する「マルチプロセッサ処理システム」を提供する。
【解決手段】 本発明に係るマルチプロセッサ処理システムは、フラッシュメモリに記憶されたOSプログラムをメモリにロードし、ロードされたOSプログラムを実行する。フラッシュメモリ20は、OSプログラムを複数のプログラムファイルa、b、c、dに分割した記憶するための記憶空間72、74、76、78を有する。マスタープロセッサ10aにプログラムファイルaを実行させ、この実行に応答して、スレーブプロセッサ10b、10c、10dにプログラムファイルb、c、dを並列にロードさせる。これにより、OSプログラムのロード時間を短縮し、OSプログラムを起動するまでの時間を短くする。
(もっと読む)
データ交換システム
【課題】コモンメモリが無駄に大きくなることを抑えて効率的なデータ交換ができる。
【解決手段】ブロック割付け手段(1A,1B)は、自装置のコモンメモリ2上に確保する送信領域のワードサイズを共通のものとしてブロック単位に割付けておく。送信ノードグループ決定部1Dはシステムに結合されているノード群を複数のグループに分け、このグループ別にコモンメモリの各送信領域を1対1に対応付け、同じグループに属するノード群のうち、どのノードから送信領域に送信できるかを決定しておく。送信ブロック番号決定部1Eは自ノードがコモンメモリ送信処理において送信するブロック番号を決定する。受信処理部1Fは、コモンメモリ上の各ブロックを、どのノード番号から受信するかを設定し、当該ノード番号をもつノードからの送信データを当該ブロックに受信する。
(もっと読む)
1 - 20 / 39
[ Back to top ]