
Fターム[5B056BB72]の内容
Fターム[5B056BB72]に分類される特許
1 - 13 / 13
演算装置、演算方法および演算プログラム
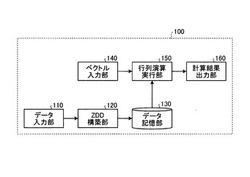
【課題】2値行列と実数ベクトルとの行列演算を効率的に実行する。
【解決手段】演算装置100は、M行N列(M、Nは整数)の2値行列のデータを入力するデータ入力部と、N次元の実数ベクトルを入力するベクトル入力部と、前記データ入力部により入力された2値行列のデータを、ゼロサプレス型二分決定グラフ(ZDD)のデータ構造に変換した変換データを構築する構築部と、前記構築部により構築された変換データと、前記ベクトル入力部により入力された実数ベクトルとの行列演算を実行する演算部と、前記演算部による演算結果を出力する出力部とを有する。
(もっと読む)
総和計算方法及び数値演算装置

【課題】汎用性を有するNビット幅のレジスタとNビット幅の加算器とでNビット幅の複数の数の総和計算が可能な総和計算方法を提供する。
【解決手段】総和計算方法は、N(2以上の自然数)ビット幅の2進数である複数の数を受け取り、複数の数の同一のビット位置にある1の個数を計数することにより、第n(=1〜N)ビット位置の1の個数を各nに対して求め、複数M(2以上の自然数)個のNビット幅のレジスタにより構成されるN列M行の行列の第n列に、第nビット位置の1の個数を表わす2進数を、第1行が最下位ビットで第M行が最上位ビットとなるように列方向に格納し、第m(=1〜M−1)行のNビット幅のレジスタの最下位ビット以外の格納内容を右(最下位方向)に1ビットシフトして第m+1行のNビット幅のレジスタの格納内容に加算する演算を第1行から順番に第M−1行まで実行することにより総和を求める各段階を含む。
(もっと読む)
行列演算コプロセッサ
【課題】 プロセッサから行列要素を1個ずつしか受け取れない状況でも、行列乗算処理を高速実行可能な行列演算コプロセッサを提供する。
【解決手段】 制御部140は、行列A、Bの乗算結果である行列Qの要素を行毎に順次得るための制御を行う。行列要素レジスタ120は、行列Bの要素を記憶する。制御部140は、行列Qの1行分の要素を累算器111〜114から得るため、累算器111〜114を初期化し、行列Aの1行分の要素をCPU200から1個ずつ受け取る都度、受け取った要素を乗算器101〜104に送るとともに、当該要素を共通の乗算相手とする1行分の要素を行列要素レジスタ120から乗算器101〜104に送って乗算を行わせ、各乗算結果の累算を累算器111〜114に各々行わせる。
(もっと読む)
積和演算器およびデジタルフィルタ
【課題】クロックに同期して逐次入力されるデータを対象として任意係数の積和演算を実行する高速ディジタルフィルタの回路規模を削減し消費電力を低減する。
【解決手段】Mタップの積和演算に対して1つまたは複数の積和演算にブロック分けし、予め乗数または被乗数の一方であるブロック内入力データから加算を行い、ブロック内の乗数または被乗数の他方を分離的な最小項で表すことで、乗算部分積に相当するand項を作り、ブロック内を一括してorして論理的に1つに集約し、ブロック内の部分積を1つの乗算器の部分積と同程度の数に削減し、またブロック内の積和演算の乗算後の加算を無くして、ブロック間の総和をとり、積和演算結果を出力する。またTタップ数のデジタルフィルタを、2タップ単位で係数と入力データの関係をクロスした形で加算し、加算した結果を1つの乗算器で計算することで、乗算器の個数を半分にする。
(もっと読む)
動的再構成可能演算装置および半導体装置
【課題】面積効率の高い動的再構成可能演算装置を得る。
【解決手段】乗算器100〜107は、それぞれ2入力の乗算を行う。加算器200〜203は、乗算器100〜107の乗算結果出力100c〜107cを入力として加算を行う。加算器204,205は、加算結果出力200a〜203aか乗算結果出力100c,101c,106c,107cかを入力として加算を行う。加算器206,207は、加算結果出力204a,205aか乗算結果出力102c〜105cかを入力として加算を行う。
(もっと読む)
演算処理装置
【課題】数学関数の値を求めるテーラー級数演算処理を、従来よりも高速に実行可能な演算処理装置を提供する。
【解決手段】任意の数学関数のテーラー級数演算の係数データを格納する係数テーブルのセットを、専用のメモリである係数テーブルセット10に記憶する。ある数学関数の値をテーラー級数演算で求める際には、テーラー級数の次数番号21、係数テーブルのセット番号22を用いて、係数テーブルセット10から所望の係数データを取得し、それを、マルチプレクサ27を介して浮動小数点積和演算器1050に供給する。浮動小数点積和演算器1050は、該係数データを用いて積和演算を実行し、任意の数学関数の値をテーラー級数演算により求める。
(もっと読む)
並列演算方法、演算装置、および演算装置用プログラム
【課題】本発明は、通信回数を増やすことなく、演算装置間のネットワークの通信路の数を少なくすることを目的とする。
【解決手段】本発明の並列演算方法は、N個の演算装置がバラバラに記録しているK次元のベクトルの和を、リング状のネットワークを利用して計算し、結果をN個の演算装置で共有する。具体的には、K個の成分をN個のグループに分け、各演算装置は、1つのグループの成分を隣の演算装置に渡す。受け取った演算装置は自分が保有する当該グループの成分との和を求め、その結果を次の演算装置に渡す。この作業をN−1回行い、N回目からは受け取った演算装置は、当該グループの成分の和として記録すると共に、そのデータを次の演算装置に渡す。この作業を2N−2回目まで行う。
(もっと読む)
2つの独立した差分絶対値和を生成するための命令
単一の命令を受信するとき、2つの独立した差分絶対値和(SAD)演算(505、705)を実行するための方法および装置が提供される。2つの演算は並列で実行され得る。演算は2個のソースレジスタ(405、410)内に記憶された値を処理して、結果はデスティネーションレジスタ(425)に記憶される。ソースレジスタおよびデスティネーションレジスタはそれぞれ2つの独立したアクセス可能な区分を有し、それにより、第1のSAD演算(401)は第1の区分にアクセスすることが可能であり、一方、第2の独立したSAD演算(402)はレジスタの第2の区分に同時にアクセスすることが可能である。第1のSAD演算は、ソースレジスタの第1の区分内の値に関して実行され、結果はデスティネーションレジスタの第1の区分に記憶されている。第2のSAD演算は、ソースレジスタの第2の区分内の値に関して実行され、結果はデスティネーションレジスタの第2の区分に記憶されている。値は画素値を含み得る。  (もっと読む)
(もっと読む)
汎用アレイ処理
処理方法および装置を含む汎用アレイ処理技術。プロセッサは、乗算器、マルチプレクサおよびALUなどの再使用可能な計算コンポーネントによって設計されている並列処理経路を含むことがある。該経路を介するデータの流れおよび実行される演算はオペコードに基づいてコントロール可能である。プロセッサは共有され、スケーラブルであり、かつ行列演算を実行するように構成されてもよい。とりわけ、このような演算は、MIMO−OFDM通信システムの物理セクションに有用である。  (もっと読む)
(もっと読む)
計算装置、および、計算方法
【課題】浮動小数点数の演算(内積演算、総和演算)において、高精度の結果を算出すること。
【解決手段】本発明は、浮動小数点形式で表現された複数の被演算子の入力を受け付ける入力部104と、入力部104に入力されたデータを記憶する記憶部と、記憶部に記憶された複数の被演算子の加算処理において、各被演算子を整数配列を使用して表現し、整数配列の値どうしを加算し、加算した結果を浮動小数点数形式に変換する演算部と、演算部の演算結果を出力する出力部105と、を有することを特徴とする。また、入力部104は、内積演算におけるベクトルの乗算結果を被演算子として入力を受け付けることを特徴とする。
(もっと読む)
浮動小数点データの総和演算処理方法及びコンピュータシステム
【課題】複数のノードの浮動小数点データの総和を計算するシステムにおいて、計算順序を守らなくても、総和計算処理に要する時間を短縮する。
【解決手段】各ノード(10,11,12,13)が、浮動小数点データを、リダクション機構(22)に送り、リダクション機構(22)は、指数部が最大値のグループと、2番目に最大値のグループのみの総和を演算し、指数部が最大値のグループの総和と、2番目に最大値のグループの総和同士を加算する。これにより、数値の計算順序に関係なく計算しても、計算結果の同一性を保証できる。
(もっと読む)
ベクトル演算装置および方法
【課題】 ベクトル演算装置で、複数の同種演算の計算式を1つの計算式として高速に処理ができるようにする。
【解決手段】 複数のベクトルパイプでは、複数のベクトル演算がそれぞれ並列に処理され、ベクトルパイプが有するベクトルレジスタは、ベクトル演算対象となるデータが一時蓄積されると共に、当該データに基づくベクトル演算結果が一時蓄積され、データ転送部は、ベクトル演算対象となるデータをメモリからベクトルレジスタに複写転送すると共に、ベクトル演算結果をベクトルレジスタからメモリに複写転送し、このデータ転送部がアクセスするメモリの領域を指定する際に、ベクトルパイプ毎にメモリの指定領域が異なるようにする。また、ベクトル演算器による演算の際に用いるベクトルの要素数がベクトルパイプ毎に異なるようにする。
(もっと読む)
演算処理装置および演算処理プログラム
【課題】ベクトルプロセッサにおいて、回路規模の増大を抑制しつつ、飽和機能を持つ命令を高速に処理する。
【解決手段】 加減算/シフトユニットA25または加減算/シフトユニットB26で加算処理がそれぞれ行われる時に、飽和処理部25a、26aは、ステータスレジスタ22のSビットを参照し、Sビットが“1”の時、加減算/シフトユニットA25または加減算/シフトユニットB26にて得られた加算結果がオーバーフローまたはアンダーフローしているかどうかをそれぞれ判断し、加減算/シフトユニットA25または加減算/シフトユニットB26にて得られた加算結果がオーバーフローしている場合、その加算結果として“0x7FFFFFFF”を出力するとともに、加減算/シフトユニットA25または加減算/シフトユニットB26にて得られた加算結果がアンダーフローしている場合、その加算結果として“0x80000000”を出力する。
(もっと読む)
1 - 13 / 13
[ Back to top ]