
Fターム[5B091CC03]の内容
Fターム[5B091CC03]に分類される特許
1 - 20 / 38
構文解析情報作成装置、翻訳装置、翻訳システム、構文解析情報作成方法およびコンピュータプログラム
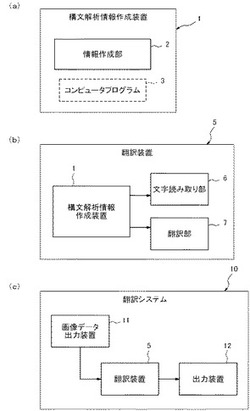
【課題】 文字認識処理および翻訳処理の高精度化を図りつつ、文字を認識する速度の向上を図る。
【解決手段】 構文解析情報作成装置は、情報作成部1を備える。情報作成部1は、文法制約条件を示す第1構文解析情報(例えば、翻訳用の構文解析情報)から、解析対象の単語候補に対応する文法情報を抽出し、当該抽出した文法情報に基づいて、前記単語候補に対応する文法制約条件を示す第2構文解析情報(例えば、文字認識用の構文解析情報)を作成する。
(もっと読む)
文書処理装置およびプログラム

【課題】構文的にわかりにくい文を自動的に検出し、ユーザに対して提示することが可能な文書処理装置およびプログラムを提供することにある。
【解決手段】ルール格納手段は、構文的にわかりにくい文を検出するための予め定められた条件および当該条件に応じたメッセージを対応づけて格納する。入力手段は、ユーザによって指定された文を入力する。解析手段は、入力手段によって入力された文の構造を解析する。判定手段は、解析手段による解析結果に基づいて、入力手段によって入力された文がルール格納手段に格納されている条件を満たすかを判定する。出力手段は、条件を満たすと判定手段によって判定された場合、入力手段によって入力された文の構造および当該条件に対応づけてルール格納手段に格納されている当該条件に応じたメッセージを出力する。
(もっと読む)
抽出規則作成システム、抽出規則作成方法及び抽出規則作成プログラム
【課題】指定された位置に対応する情報と同等の概念を有する情報を効率よく抽出可能な抽出規則を作成できる抽出規則作成システムを提供する。
【解決手段】組合せ位置情報作成手段81は、タグ付きテキストと、文字列またはタグの位置を示す3個以上の位置情報と、キー情報とをもとに組合せ位置情報を作成する。単語タグ文字列作成手段82は、その組合せ位置情報に含まれる位置情報が示す位置の単語またはタグを組み合わせた単語タグ文字列をその組合せ位置情報ごとに作成する。単語タグ文字列選択手段83は、評価値を算出して単語タグ文字列を選択する。付属文字列抽出手段84は、タグ付きテキストを文節ごとに分割した単語のうち、位置情報が示す位置の文字列を含む文節分割単語を抽出し、その文節分割単語から、位置情報が示す位置に含まれない付属文字列を抽出する。抽出規則作成手段85は、単語タグ文字列と付属文字列とをもとに抽出規則を作成する。
(もっと読む)
抽出規則作成システム、抽出規則作成方法及び抽出規則作成プログラム
【課題】ユーザが欲する情報を抽出するための規則を効率よく作成する抽出規則作成システムを提供する。
【解決手段】抽出規則作成手段82は、タグ付きテキスト及びそのタグ付きテキスト中の文字列の位置を示す情報である文字列位置情報が与えられたときに、その文字列位置情報が示す位置に対応する単語又はタグと、その単語又はタグの前後の単語又はタグとを組み合わせて、タグ付きテキストから情報を抽出するための規則である抽出規則を作成する。適合文位置情報抽出手段83は、タグ付きテキスト記憶手段81に記憶されたタグ付きテキストごとに、抽出規則に適合する単語又はタグを含む適合文の位置を示す情報である適合文位置情報を抽出する。評価値算出手段84は、1つのタグ付きテキスト内に現れる適合文がより少ないほど評価値を高く算出し、より多くのタグ付きテキスト内に適合文が現れるほど評価値を高く算出する。
(もっと読む)
テキスト解析学習装置
【課題】ラベル付き学習データ及びラベル無し学習データの双方を効率よく利用した学習により高精度なテキスト解析を実現できるテキスト解析学習装置を提供する。
【解決手段】ラベル付き学習データに付与されたラベルで示される解析結果の尤度を算出し、ラベル無し学習データに対する解析結果と同じカテゴリに属する入力文に対する解析結果との整合性の度合を示す評価値を算出し、尤度及び整合性の評価値に基づく目標関数が最大化するように素性データに対応するモデルパラメータの値を更新し、当該モデルパラメータの更新値を用いて算出された尤度及び評価値に基づく当該モデルパラメータの更新を、当該モデルパラメータの更新値が所定の収束条件を満たすまで実行して、所定の収束条件を満たしたモデルパラメータ、素性データ及びラベルの一覧を用いて、テキスト解析器が使用する解析用辞書を生成する。
(もっと読む)
能動学習装置及び方法
【課題】日本語係り受け解析において、受動学習の場合よりも、より少ない人手コストで高い精度が得られる能動学習装置及び方法を提供すること。
【解決手段】能動学習装置10は、日本語を構成する文節の係り関係の正解事例データDB41に基づいて、文節の係り関係を判定する係り関係モデルDB31を作成する。そして、能動学習装置10は、一の文を係り関係モデルDB31を用いて係り受け解析を行い、解析結果を出力し、出力した解析結果が所定の場合に一の文を選択し、選択した一の文をユーザ端末60に提示し、提示した一の文を構成する文節の係り関係についての判定情報を受け付け、受け付けた判定情報に基づく正解データを正解事例データDB41に追加し、追加された正解事例データDB41に基づいて係り関係モデルDB31を更新する。
(もっと読む)
機械翻訳システム及び機械翻訳プログラム
【課題】翻訳速度の高速化が可能で、しかも精度の高い翻訳結果を得ることができる機械翻訳システムを提供することである。
【解決手段】原文分割部29は入力装置20から入力された第一言語の原文を特定の単位で分割し、翻訳部30は辞書部34の情報を使って原文分割部29で得られた複数の分割原文を並列して翻訳するとともに、原文翻訳の過程で判断される翻訳情報のうち一つに特定できた翻訳情報を翻訳情報蓄積部32に蓄積する。そして、訳文結合部31は翻訳部30で翻訳された分割原文の分割訳文を結合する際に、分割訳文の中に翻訳部30で一つに特定できなかった翻訳情報がある場合には、翻訳情報蓄積部32に蓄積された翻訳情報に一致するように翻訳結果の訳語の置き換えを行い、翻訳部30で翻訳された分割訳文を結合する。
(もっと読む)
構文解析装置及びプログラム
【課題】文をその区切りによって分割して得られる文要素に対して構文解析を行う場合に、構文解析に失敗しにくい構文解析装置を提供する。
【解決手段】解析対象文を複数の文要素に分割し、分割された複数の文要素の少なくとも一つについて、標準文法規則に基づいて当該文要素に適合する修正文法規則を生成し、当該生成された修正文法規則を用いて文要素の構文解析を行う構文解析装置である。
(もっと読む)
2カ国語コーパスからの変換マッピングの自動抽出プログラム
【課題】機械翻訳システムを改善する必要性に対処するシステムまたは方法を提供する。
【解決手段】2カ国語コーパス取得される依存構造のノードを整列させるメソッド300は、第1の段階302が、該依存構造のノードを関連付けて仮の対応を形成する2段階アプローチを含む。次いで、段階304において、該依存構造のノードを仮の対応および/または構造的考察に応じて整列させる。整列した依存構造からマッピングを取得する。翻訳実行時により流暢な翻訳が取得できるように、ローカルコンテキストの種類および量の変化に応じてマッピングを拡大することが可能である。
(もっと読む)
文字処理装置
【課題】 単語辞書や正解コーパスが整備されていない分野のテキストを対象とする場合であっても、高い精度の単語区切り結果が得られる形態素解析システムを実現する技術を提供する。
【解決手段】 単語尤度計算手段4が、形態素解析結果の各文字列の単語らしさ(単語尤度)を算出し、変換ルール生成手段5が、形態素解析結果の1以上の文字列を抽出元の文中の順序に沿って連結した各連結文字列について、その構成要素である各文字列の単語尤度の平均値に基づいて第1連結文字列に該当するか判定し、第1連結文字列と判定された連結文字列の区切位置を異ならせた各連結文字列について、その構成要素である各文字列の単語尤度の平均値に基づいて第2連結文字列に該当するか判定し、第1連結文字列における区切位置を対応する第2連結文字列における区切位置に変換する変換ルールを生成する。
(もっと読む)
辞書作成装置、辞書作成方法および辞書作成プログラム並びに辞書作成プログラムを記録した記録媒体
【課題】付属語から必須表層格への適切な変換ルールである格変換ルールを自動学習し出力する。
【解決手段】辞書作成装置10は、構文解析部101、主辞特定部103、主辞間係り受け解析部104、格変換ルール学習部105、構文解析結果テーブル120、主辞テーブル121および項構造正解テーブル123等から構成され、構文解析部101はテキストを構文解析し、文節集合の係り受け関係を、構文解析結果テーブル120に格納する。主辞特定部103が文節の意味的主辞を特定し、文節内の自立語と判定された単語を意味的主辞として主辞テーブル121に格納する。主辞間係り受け解析部104が、各主辞の属する文節内で非自立語全体を付属語として主辞テーブル121に追加し、その後、格変換ルール学習部105が、格変換ルールを学習する。学習部105が動作性名詞について、必須表層格を格納した項構造正解テーブル123を作成する。
(もっと読む)
音訳モデル作成装置、音訳装置、及びそれらのためのコンピュータプログラム
【課題】言語の実情に即した音訳モデルを生成し、その音訳モデルを利用して言語間の音訳を信頼性高く行なうことが可能な音訳装置を提供する。
【解決手段】音訳装置20は、第1及び第2の言語の単語の音訳対を記憶する音訳対記憶装置30と、それら音訳対の各々について、第1の言語と第2の言語の単語又は単語列を構成する文字又は文字列を互いに対応付け、互いに対応付けられた音訳対の各々の第1の言語の文字及び第2の言語の文字を互いの訳語とみなして翻訳モデル48を作成し、音訳モデルとして出力する翻訳モデル作成部44と、第2の言語の文字を単位とするNグラム言語モデル50を作成言語モデル昨西部46と、第1の言語の入力単語52が与えられると、翻訳モデル48をと言語モデル50とを用いた統計的自動翻訳により入力単語52を第2の言語の単語56に音訳して出力する自動翻訳装置54とを含む。
(もっと読む)
機械翻訳装置及び機械翻訳プログラム
【課題】翻訳対象原文と翻訳用例の原文との差異部分を翻訳用例の訳文中の語句に対応付けて他の語句と区別して表示でき、翻訳用例の訳文の差異に相当する部分への編集を容易に行えるようにすることである。
【解決手段】翻訳部24は、入力された第1言語の翻訳対象原文を記憶部19の辞書部21を用いて翻訳するとともに、検索キーとして指定された翻訳対象原文に対して用例辞書部22から翻訳対象原文に類似する翻訳用例を検索する。用例処理部25は、翻訳用例の原文と翻訳対象原文との差異部分を対応付けるともに当該差異部分に対して編集が必要な翻訳用例の訳文中の語句と翻訳対象原文中の語句とを対応付ける。制御部23は、ユーザの操作指示に応じて翻訳用例の原文と翻訳対象原文との差異部分ごとに相当する箇所を他の語句と区別して表示部17に表示する。
(もっと読む)
機械翻訳装置及び機械翻訳プログラム
【課題】用例辞書の翻訳用例が適用された訳文であっても、ユーザ辞書に登録された訳語を反映できるようにすることである。
【解決手段】第一の言語と第二の言語の文とを対にした翻訳用例を記録する用例辞書30と、システム辞書に登録されていない語句を第一の言語及び第二の言語で記録するユーザ辞書31と、入力部16で指定された原文を用例辞書30から翻訳用例を検索する用例辞書検索部25と、用例辞書検索部25で検索された翻訳用例の原文中からユーザ辞書の登録語を検索するユーザ辞書検索部26と、翻訳用例の訳文中にユーザ辞書の登録訳語が使用されているか否かを判定しユーザ辞書の登録訳語が使用されていないときは原文及び訳文の該当語句に識別情報を付けて表示部17に表示する翻訳部23とを備える。
(もっと読む)
翻訳文出力方法、翻訳文出力装置、及び翻訳文出力プログラム
【課題】翻訳文の品質を容易に判断可能な翻訳文出力方法、翻訳文出力装置、及び翻訳文出力プログラムを提供すること。
【解決手段】第一言語の文章を含むコンテンツを、第一言語とは異なる第二言語に翻訳した翻訳文の一部を、コンピュータが出力する翻訳文出力装置において、まず、予め登録されている翻訳文の中から、評価用翻訳文提示要求により指定された出力対象翻訳文を特定する(S71)。続いて、抽出ルールを取得し(S72)、S71において特定された出力対象翻訳文から、取得した抽出ルールに従って一部の文章を抽出翻訳文として抽出する(S73)。そして、S73において抽出された抽出翻訳文を出力する。
(もっと読む)
電子機器、その制御方法、および、その制御プログラム
【課題】複数の言語が混在する文である多言語混在文に関し、種々の情報を取扱うことのできる電子機器、その制御方法、および、その制御プログラムを提供する。
【解決手段】電子機器では、入力文と翻訳文(出力文)が、出力文における優先出力言語と混在言語の割合を表わす画像(スライドバー表示部101)とともに表示される。スライドバー表示部101の中に、スライドバー102とともに、その下部に五段階で翻訳文(出力文)における言語の割合を示すための割合表示記号101A〜101Eを表示させる。スライドバー102は、割合表示記号101A〜101Eのいずれかに対応する位置に表示される。
(もっと読む)
機械翻訳装置、機械翻訳方法、および生成規則作成装置、生成規則作成方法、ならびにそれらのプログラムおよび記録媒体
【課題】翻訳精度を向上させることのできる機械翻訳技術を提供する。
【解決手段】機械翻訳装置2は、翻訳元または翻訳先の文を構成する部分木の階層的特徴を表現する素性を示す階層的素性119と、翻訳元に含まれずに翻訳先の文に挿入されている単語と翻訳元単語との関係を表現する素性を示す翻訳先言語挿入素性118と、ルールテーブル114に格納された翻訳モデルとを含む素性に対応した重みを、素性重み学習用対訳学習データ250に基づいて学習し、素性重み211を格納する素性重み学習手段221と、素性ベクトルと素性重みベクトルとの内積を部分仮説スコアとして算出する部分仮説スコア算出手段243と、入力文に対して適用可能な部分仮説を探索し、部分仮説を拡張することによって最終的に生成された部分仮説のうちで部分仮説スコアが最大となる部分仮説を仮説として探索する仮説探索手段244とを備える。
(もっと読む)
2カ国語コーパスからの変換マッピングの自動抽出プログラム
【課題】機械翻訳システムを改善する必要性に対処するシステムまたは方法を提供する。
【解決手段】2カ国語コーパス取得される依存構造のノードを整列させるメソッド300は、第1の段階302が、該依存構造のノードを関連付けて仮の対応を形成する2段階アプローチを含む。次いで、段階304において、該依存構造のノードを仮の対応および/または構造的考察に応じて整列させる。整列した依存構造からマッピングを取得する。翻訳実行時により流暢な翻訳が取得できるように、ローカルコンテキストの種類および量の変化に応じてマッピングを拡大することが可能である。
(もっと読む)
モビール形状概念を基礎にした構文分析方法及びこれを用いた自然語検索方法
【課題】いかなる語順倒置型構文も分析が容易なので、早く処理することができ、文章を構成する表現間の文法的関係を正確に捕捉する。
【解決手段】構文分析方法及び自然語検索方法は、文法規則データベースと、助詞と語尾を共に統語の単位として取り扱う標識理論に基づいて用言語尾の統語的地位を認定し、語彙間の統合関係が完全に文法的に規定され得るように、文章の各構成成分の語幹及び語尾など中心語が有する下位範疇の内訳が格納される下位範疇化データベースとを構築し、入力された文章を形態素分析段階と、分析された形態素を文法規則データベースに格納された文法的規則によって文章の部分的な構造をまず確立し、前記下位範疇化データベースを用いて全体的な構造を確立し、各構造の加重値を計算して、最も適した最適例を確定して出力する構文分析段階と、を備えてなる。
(もっと読む)
体験情報抽出方法及び装置及びプログラム及びコンピュータ読み取り可能な記録媒体
【課題】ある文書が与えられた時に、キーワードなどの入力がなくても、その文書の筆者が何についてどのような体験を記述しているか、体験の対象と体験した事柄を提示する。
【解決手段】本発明は、物事を利用もしくは体験・経験したことを表すような語句を体験表現とするときに、体験表現と体験の対象となる語句との関係、あるいは該体験表現と該語句を総称したカテゴリとの関係、もしくは、該体験表現と該語句と該カテゴリの関係を含む情報が格納されている体験表現辞書記憶手段を参照して、入力文書中で該当する体験表現に対応する語句やカテゴリを選定する。
(もっと読む)
1 - 20 / 38
[ Back to top ]