
Fターム[5D015AA06]の内容
Fターム[5D015AA06]に分類される特許
1 - 20 / 219
音響処理装置、音響処理方法、プログラム、記録媒体、サーバ装置、音響再生装置および音響処理システム
音声認識装置、方法及びプログラム
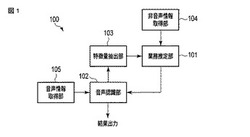
【課題】音声認識精度を向上することにある。
【解決手段】一実施形態に係る音声認識装置は、業務推定部、音声認識部及び特徴量抽出部を含む。業務推定部は、利用者の業務に関連する非音声情報を用いて利用者が行っている業務を推定し、該業務の内容を示す業務情報を生成する。音声認識部は、前記業務情報に対応する音声認識手法に従って前記利用者が発した音声情報に対して音声認識を行い、音声認識結果を生成する。特徴量抽出部は、前記音声認識結果から、前記利用者が行っている業務に関連する特徴量を抽出する。前記業務推定部は、少なくとも前記特徴量を用いて前記利用者の業務を再推定し、前記音声認識部は、再推定の結果得られる業務情報に基づいて音声認識を行う。
(もっと読む)
音判定システム、音判定方法および音判定プログラム

【課題】音によるコンテキストの理解の妨げとなる類似音を認識対象音と区別して、正しいコンテキストの理解を可能とする。
【解決手段】1つ以上の集音手段によって収集された音のデータを用いて、集音手段が配された空間内の特性であって音源からの音に基づく音特性を計測する音特性計測手段101と、音特性計測手段101によって計測された音特性が認識対象音の音特性と合致するか否かを判定して、収集された音が認識対象音であるか類似音であるかを判別する類似音判別手段102とを備える。
(もっと読む)
位置推定装置、位置推定方法、プログラムおよび位置推定システム
【課題】屋内にいる利用者の位置推定を精度よくかつ低コストで実現することを可能にする。
【解決手段】位置推定装置は、位置情報と音特性との対応関係を記憶する記憶部110と、集音器による集音結果から判定される音特性に対応する位置情報を前記記憶部から抽出する抽出部150と、固定電話端末に対して区画に設置された機器が発する区画識別音を制御する音制御部120と、利用者端末と通信を行う通信部130と、利用者端末の集音器による集音結果から区画識別音の音特性を判定する判定部140と、を備える。
(もっと読む)
通話データ管理装置及び通話データ管理システム
【課題】オペレータにかかる負担をなくし、音声データの分類の精度の低下を防止して、顧客のクレーム部分の精度高いデータ検索を可能にする。
【解決手段】顧客とオペレータとの電話での通話を音声データに変換して1処理毎の音声ファイルを音声データ用データベース9に蓄積し、蓄積した音声ファイル毎に音声データを読み出して、顧客の声のトーンから当該顧客によるクレームの有無を判断し、クレーム有りと判断した場合、その音声データにクレームであることを示すタグ種別データを付与すると共に、顧客の通話終了間際の声のトーンから当該顧客に対するオペレータの対応が適正か否かを判断して、オペレータの対応が適正、不適正に応じた対応タグデータを前記タグ種別データに付加してタグデータ用データベース10に格納する。
(もっと読む)
音声制御システム、音声制御装置、音声制御方法および音声制御プログラム
【課題】ユーザの通話を監視して感情的な音声や危険語句をオペレータに伝達する前にマスキングなどにより一律に変換処理を行なうため、オペレータに判断を委ねることなく通話内容を制御すること。
【解決手段】ユーザ端末とオペレータ端末との通話を公衆電話網を介して確立させる電話交換手段と、電話交換手段により確立された通話をモニタしてユーザ端末とオペレータ端末との通話内容を音声情報として取得する通話モニタ手段と、通話モニタ手段により取得された音声情報中に認識されるユーザ端末の音声から、あらかじめ定められた特定の感情を表わす感情的音声または否定的な語彙を含む特定語彙の音声のうちいずれかの不穏当音声を検出する不穏当音声検出手段と、不穏当音声検出手段により検出された不穏当音声を制御した制御音声を生成する音声生成手段と、を備えることを特徴とする。
(もっと読む)
音声解析装置
【課題】簡易な構成により、利用者の精神状態を解析するとともにその状態を安定化させる。
【解決手段】本体部11の一端面12には収音部13が設けられている。本体部11の他端面13からは挿入部15が突出しており、その先端には収音部16と放音部17が併設されている。解析部21は、挿入部15が利用者Sの耳の中に挿入された状態において、収音部16が耳の中から収音した音の音信号XINTと収音部13が耳の外から収音した音の音信号XEXTとを受け取る。そして、解析部21は、これら2種類の音信号XINT及びXEXTから利用者Sの会話の状態を解析し、その解析結果である解析結果データP1〜P5を記憶部23に記憶する。
(もっと読む)
音声信号処理装置
【課題】用件に対する話者間の対話時の音声信号から用件に係る必要情報を精度よく抽出することができる技術を提供する。
【解決手段】音声認識手段13は、話者間の対話時の音声信号を音声認識情報に変換する。会話単位分割手段14は、音声認識情報を会話単位に分割する。必要情報手掛かり情報付与手段16は、会話単位に含まれている必要情報手掛かり情報を会話単位に付与する。用件判別手段15は、音声認識情報に基づいて話者間の対話の用件を判別する。対話状態遷移判別手段17は、用件に対応する必要情報を抽出するための手掛かりとなる必要情報手掛かり情報が含まれている会話単位を選択する。そして、選択した会話単位と、用件に対応して対話状態判別情報データベース25に記憶されている対話状態判別情報に基づいて、対話状態が、情報要求対話状態、要求受理対話状態、情報開示対話状態、情報受理対話状態の順に遷移したことを判別することにより必要情報を抽出する。
(もっと読む)
データ検索装置およびプログラム
【課題】ユーザの想定に近い音素材が検索結果として得られるようにすること。
【解決手段】本発明の実施形態における楽音処理装置は、楽音波形信号を示す楽音データと当該楽音波形信号の複数種類の特徴量を示す特徴量データとを対応付けて登録された音素材データベースを用いて、ユーザから指定される検索条件に基づいて検索し、検索結果を表示する。このとき、ユーザの想定に近い音素材が検索結果として得られるように、ユーザによって指定された検索アルゴリズムにより検索が行われる。
(もっと読む)
楽曲区間検出装置および方法、プログラム、記録媒体、並びに楽曲信号検出装置
【課題】入力信号から楽曲部分を精度良く検出する。
【解決手段】指標算出部は、時間周波数領域に変換された入力信号の各領域の信号成分の強さ(例えばパワースペクトル)と、信号成分の強さを近似した関数(2次関数)とに基づいて、信号成分のトーンらしさの指標を算出し、楽曲判定部は、トーンらしさの指標に基づいて、入力信号の各領域に楽曲が含まれているか否かを判定する。本技術は、楽曲と雑音とが混在した入力信号から楽曲部分を検出する楽曲区間検出装置に適用することができる。
(もっと読む)
話者状態検出装置、話者状態検出方法及び話者状態検出用コンピュータプログラム
【課題】対話中の複数の話者のうちの少なくとも一人の状態を、その対話の際の音声に基づいて正確に検出可能な話者状態検出装置を提供する。
【解決手段】話者状態検出装置(1)は、第1の話者の発した第1の音声及び第2の話者の発した第2の音声を取得する音声入力部(2、3)と、第1の音声に含まれる第1の話者の第1の発話区間と、第2の音声に含まれ、第1の発話区間よりも前に開始される第2の話者の第2の発話区間との重畳期間、または第1の発話区間と第2の発話区間の間隔を検出する発話間隔検出部(11)と、第1の発話区間から第1の話者の状態を表す状態情報を抽出する状態情報抽出部(12)と、重畳期間または間隔と状態情報とに基づいて第1の発話区間における第1の話者の状態を検出する状態検出部(13、14、17)とを有する。
(もっと読む)
特定音響信号含有区間検出装置、方法、及びプログラム
【課題】音響信号の時間伸縮の可能性を考慮し、参照信号と蓄積信号上の参照信号に類似した区間の長さが異なる場合にも、参照信号と類似する音を含む区間を、蓄積信号中で精度よく検出することができるようにする。
【解決手段】周波数帯域毎に、各小領域参照信号スペクトログラムと類似する小領域蓄積信号スペクトログラムを検出する。周波数帯域毎に検出された、各小領域参照信号スペクトログラムに類似した小領域蓄積信号スペクトログラムの小領域類似度を、予め定められた区間伸縮率の範囲に基づく、該小領域蓄積信号スペクトログラムを含む蓄積信号の複数の時刻tを先頭とする区間の各々の区間類似度に加算することにより、蓄積信号の各区間に対する区間類似度を計算する。区間類似度に基づいて、蓄積信号中の参照信号と類似する音を含む区間を検出する。
(もっと読む)
オーディオデータ特徴抽出方法、オーディオデータ照合方法、オーディオデータ特徴抽出プログラム、オーディオデータ照合プログラム、オーディオデータ特徴抽出装置、オーディオデータ照合装置及びオーディオデータ照合システム
【課題】誤りのない確実なオーディオデータの照合を実現することのできるオーディオデータ照合システムを提供する。
【解決手段】本発明のオーディオデータ照合システム1は、既知のオーディオデータから特徴データを抽出するオーディオデータ特徴抽出装置2と、既知のオーディオデータから生成された特徴データに識別情報を登録してデータベース31に格納する特徴データ格納サーバ3と、未知のオーディオデータから特徴データを生成し、データベース31に格納されている特徴データと比較して照合するオーディオデータ照合装置4とを備えていることを特徴とする。
(もっと読む)
音処理装置および音処理方法
【課題】日常音のモデルの自動的な更新を可能とする。
【解決手段】日常音を特性に基づきクラスタに分類し、クラスタに基づき異常音の判定を行う。クラスタをガウス分布の表現に変換したガウス分布を決定するパラメータを、新たに採取した採取音の特性を用いて更新する。更新の際に、採取音の特性がガウス分布に含まれる確率が、パラメータに決定されるガウス分布に含まれる確率を示す値で表される学習閾値の範囲内にある場合に、パラメータの更新を行う。また、採取音の特性がガウス分布に含まれる確率が、学習閾値よりも低い確率を表す異常音検出閾値未満である場合に、採取音が異常音であると判定する。
(もっと読む)
音声認識操作装置及び音声認識操作方法
【課題】周囲の雑音に影響されることなくユーザの音声指示を正確に認識することができ、ひいては被制御機器をユーザの所望する通りに正しく制御することを可能とした音声認識操作装置及び音声認識操作方法を提供すること。
【解決手段】実施の形態によれば、音声認識操作装置は、音検出手段とキーワード検出手段と音声ミュート手段と送信手段とを備える。音検出手段は、音を検出する。キーワード検出手段は、音検出手段で音が検出された場合、特定のキーワードを音声認識により検出する。音声ミュート手段は、キーワード検出手段でキーワードが検出された場合、音声ミュートを指示する操作信号を送信する。送信手段は、キーワード検出手段でキーワードが検出された後の音声指示を認識し、当該音声指示に対応する操作信号を送信する。
(もっと読む)
信号処理装置および方法、並びに、プログラム
【課題】発音不要かつ非接触な入力操作を実現することができるようにする。
【解決手段】覆われ検出部103は、時間周波数変換部102により音響信号が変換されて得られたパワースペクトルを解析し、そのパワースペクトルに観測される共振点の特徴(例えば周波数や大きさ等)から、音響信号入力部101が覆われている様子(覆われ状態)を判定し、その判定結果(覆われ状態を示す情報)を機器制御決定部104に供給する。機器制御決定部104は、覆われ検出部103から供給される判定結果(音響信号入力部101の覆われ状態を示す情報)に応じて、図示せぬ電子機器の制御内容を決定し、その制御情報(命令やデータ等)を、その電子機器等に出力する。本発明は、例えば、画像処理装置に適用することができる。
(もっと読む)
情報処理装置、情報処理方法、プログラムおよび情報処理システム
【課題】不特定の人物の間で不定期に発生する会話を解析する。
【解決手段】情報処理装置100は、ユーザの発話および1または複数の他の人物の発話の音声情報を取得する音声取得部112と、音声情報を外部装置200に送信し、音声情報に基づいて1または複数の他の人物の中から抽出される会話メンバーとユーザとを含む会話グループの情報を用いて生成される会話グループ関連情報を外部装置200から受信する通信部170とを含み、会話メンバーは、1または複数の他の人物のうち、音声情報の音声特徴量と類似した音声特徴量を有する音声情報を外部装置200に送信する他の情報処理装置を保持する1または複数の人物である。
(もっと読む)
状態検出装置、状態検出方法および状態検出のためのプログラム
【課題】負荷を抑えつつ、特定の話者の状態を精度よく検出する状態検出装置を提供する。
【解決手段】音声に含まれる情報を利用して特定の話者の状態を精度よく検出するために、状態検出装置に、非抑圧状態における特定の話者の音声の特徴をモデル化した第1の特定話者モデルを生成する第1のモデル生成手段と、対応関係情報に基づいて、第1の不特定話者モデルに対する第2の不特定話者モデルへの変位量を、第1の特定話者モデルに反映することにより、抑圧状態における特定の話者の音声の特徴をモデル化した第2の特定話者モデルを生成する第2のモデル生成手段と、入力音声の特徴に対する第1の特定話者モデルの尤度である第1の尤度と、入力音声に対する第2の特定話者モデルの尤度である第2の尤度と、を算出する尤度算出手段と、第1の尤度および第2の尤度に基づいて、入力音声の話者の状態を判別する状態判別手段と、を備える。
(もっと読む)
音検出装置および音検出方法
【課題】雑音環境下においても容易且つ高精度に特定音を検出する。
【解決手段】信号パワー算出部および傾き算出部で、集音された観測音による音データの特徴を示す特徴値を時系列に沿って算出する。一方、検出対象の音と種類が同一で音が互いに異なる複数の学習データのそれぞれから、時系列に沿って特徴値の期待値を、スコアパラメータとして予め求める。スコア算出部で、音データから求めた特徴値と、学習データから求めた特徴値の期待値との差分に基づき、音データを評価するスコアを算出する。発生区間検出部で、スコアの極大値の位置と極小値の位置とを検出し、極大値の位置および極小値の位置に基づき、観測音による音データ中の特定音発生区間を検出する。
(もっと読む)
信号処理装置、撮像装置および信号処理プログラム
【課題】 音声信号の音質を劣化させることなく、非定常音の目立たない音声信号を取得することができる技術を提供することを目的とする。
【解決手段】 撮像装置が発する駆動音の情報を記憶する記憶部と、録音した音声と駆動音との類似の度合いを示す類似度を駆動音の情報を用いて算出する演算部と、類似度に基づいて音声と駆動音とが類似するか否かを判定し、判定結果に応じて駆動音を伴う駆動動作を制御指示する制御部と、を備える。
(もっと読む)
1 - 20 / 219
[ Back to top ]