
Fターム[5D015LL06]の内容
音声認識 (5,191) | 音声認識装置の制御 (1,048) | 認識結果の表示・出力 (271) | 合成音声による出力 (71)
Fターム[5D015LL06]に分類される特許
61 - 71 / 71
音声認識装置、方法及び音声認識方法を用いた携帯型情報端末装置
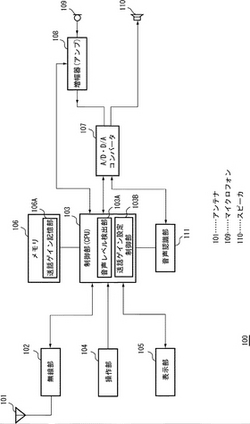
【課題】携帯型情報端末装置の使用状態に応じて入力した音声レベルを適切な音声レベルに増幅し、認識率低下の防止を行う。
【解決手段】マイクロフォンに入力する音声を認識する音声認識装置に、マイクロフォンから出力される音声信号を増幅する増幅器108と、増幅された音声レベルを検出する音声レベル検出部103Aと、送話ゲイン、適正音声レベル、送話ゲイン更新用の時定数を記憶する送話ゲイン情報記憶部106Aと、送話ゲイン、適正音声レベル、時定数を読み出し、増幅器に送話ゲインを設定し、検出された音声レベルを適正音声レベルにすべきゲインに時定数を乗じた値を送話ゲインに加算して送話ゲインを更新し、更新した送話ゲインを送話ゲイン情報記憶部に記憶させる送話ゲイン設定制御部103Bと、増幅された音声信号を入力して音声認識を行う音声認識部111とを備える。
(もっと読む)
音声認識装置及び音声認識方法
音声認識装置(1)は、不要語の集合から学習した音響モデルであるガーベージ音響モデルを予め格納するガーベージ音響モデル格納部(110)と、音響解析の単位であるフレーム毎に、非言語音声を含む未知入力音声を音響分析し、認識に必要な特徴パラメータを算出する特徴量算出部(101)と、フレーム毎に、特徴パラメータとガーベージ音響モデルとを照合し、ガーベージ音響スコアを計算するガーベージ音響スコア計算部(111)と、ガーベージ音響スコア計算部(111)が算出したガーベージ音響スコアを、非言語音声が入力されたフレームについて、上昇させるように修正するガーベージ音響スコア修正部(113)と、言語スコアと、単語音響スコアと、ガーベージ音響スコア修正手段が修正したガーベージ音響スコアとの累積スコアの最も高い単語列を、未知入力音声の認識結果として出力する認識結果出力部(105)とを備える。  (もっと読む)
(もっと読む)
音声処理システム及び方法並びに音声処理用プログラム

【課題】 未知語が含まれている入力音声に対して、精度の高い応答結果を出力する。
【解決手段】 音声データに対応する単語や文字が登録された辞書データを記憶する辞書データ記憶手段61と、文字列を区切る基準を表す予め定められた境界修正データを記憶する境界修正データ記憶手段62と、を備えると共に、入力された音声を辞書データに基づいて文字認識し、単語認識結果文字列と文字認識結果文字列とをそれぞれ生成する音声認識手段52と、単語認識結果文字列と文字認識結果文字列との少なくとも一方に基づいて単語認識結果文字列及び文字認識結果文字列のうち未知語であると判断される区間を推定する未知語区間推定手段53と、単語認識結果文字列と文字認識結果文字列とを組み合わせる文字列組み合わせ手段54と、この組み合わせられた文字列を用いて、未知語区間の境界を境界修正データに基づいて修正する未知語区間修正手段55と、を備えた。
(もっと読む)
音声入力装置及び方法、並びにプログラム及び記憶媒体
【課題】 低音量で明瞭でない音声でも音声入力や音声認識を行うことができる音声入力装置及び方法、並びにプログラム及び記憶媒体を提供することにある。
【解決手段】 音声入力装置において、咽喉マイク1は、人の声帯のある喉付近に装着され、人が音声を発したときに、その音声に応じた声帯の振動を検出して、その振動を電気信号に変換する。変換された電気信号は、A/D変換部2に送られる。A/D変換部2は、咽喉マイク1から送られてきたアナログ信号をデジタル信号に変換し、そのデジタル信号を特徴抽出部3に送る。特徴抽出部3は、デジタル信号を周波数変換し、周波数領域で特徴パラメータを抽出し、発声された特徴パラメータの列として照合部4に送る。照合部4は、認識辞書部5に記憶された各単語の標準パターンとの比較を行い、最も近似する単語を選択する。CPU6は、認識辞書部5で選択された単語を入力文字として処理する。
(もっと読む)
マルチスロット対話システムおよび方法
コンポーネントベースの手法を使用して、特定の目的またはトピック(マルチスロット対話)を達成することを目的として複数の関連する情報を集めるための、ユーザとの一連の双方向交流を構築するシステムおよび方法が開示される。本方法は、一般的には、セグメントのスロットに対する値をユーザから引き出すために一次ヘッダプロンプトを出力すること、セグメントのスロットの少なくともサブセットの各スロットに対する値を含む一次ユーザ応答を受け取ること、一次ユーザ応答を処理し一次ユーザ応答に含まれる各スロットに対する少なくとも1つの候補認識値を決定すること、一次ユーザ応答に含まれる各スロットに対応する候補認識値から選択される合致値を入力すること、および、スロットセグメントのすべてのスロットが入力されるまで、セグメントの入力されていないスロットに対して、上記のステップを繰り返すことを含む。  (もっと読む)
(もっと読む)
音声認識の方法およびシステム
ユーザの音声信号に含まれる音声情報を認識するために音声信号を分析する音声認識システムが開示されている。テスト手続きにおいて、最も確実にマッチする認識結果が、確認および/または訂正のためにユーザに出力するために、音声信号に再び変換される。分析中に、認識すべき音声信号に次に高い確率でマッチする代替的認識結果が生成される。テスト手続きにおいて、正しくない認識結果が出力される場合、ユーザはその出力を中断できる。その場合、代替的認識結果の対応するセグメントが、中断前最後に出力された認識結果のセグメントに対して自動的に出力され、ユーザはそれから選択をすることができる。供給された認識結果のセグメントは、選択された認識結果の対応するセグメントに基づき訂正される。最後に、認識すべき音声信号の残りの後続セグメントに対して、テスト手続きが継続される。対応する音声認識死すtめうも開示されている。  (もっと読む)
(もっと読む)
対話装置
【課題】対話装置で、ユーザに認識結果の候補を判別しやすく提示する従来方法は、候補のスコアや属性に応じて表示を変えるもので、属性によっては、両者の差異が明確にならない。検索の場合も、検索結果が類似している場合、差異が明確にならず、ユーザは差異を自ら認識して、所望の検索対象を選択する。
【解決手段】入力された音声を認識して認識結果の候補リストを出力する認識手段と、認識結果の候補間の差異を抽出して認識結果へ差異情報を付与する差異抽出手段と、認識結果へ付与した差異情報に基づき差異が明確になる応答を生成する差異明確化応答生成手段と、生成した応答を提示する応答提示手段を備える。
(もっと読む)
対話方法、対話装置、音声対話装置、対話プログラム、音声対話プログラム及び記録媒体
【課題】対話装置における対話の停滞の回避
【解決手段】 入力情報に含まれるパラメータを抽出する言語理解処理と、入力情報を言い回しパターンデータベースと照合して入力情報の言い回しタイプを抽出する言い回しタイプ抽出処理と、応答内容を決定する応答内容決定処理と、応答文の言い回しタイプを決定する応答文の言い回しタイプ決定処理と、応答内容と、応答文の言い回しタイプを参照して応答文を生成する応答文生成処理と、入力情報から抽出したパラメータと、入力情報から抽出された言い回しタイプと、応答内容と、応答文の言い回しタイプと、応答文とからなる履歴情報を記憶する履歴情報記憶処理とを実行させ、応答内容決定処理は言い換え応答出力判定処理を有し、対話の状況によっては一つの応答の中においてある概念について重複させて言及するような応答内容を決定し、異なる種類の言い回しタイプをそれぞれの言及に用いるように決定する。
(もっと読む)
ユーザとシステムとの間の通信方法及びシステム
本発明は、ユーザとシステムとの間での通信方法に関し、この通信方法においては、ユーザがシステムを見ているか、あるいは何処か他の所を見ているかが検出され、この検出に基づいて通信が調整される。  (もっと読む)
(もっと読む)
車載電子装置
【課題】運転開始前に運転者に対して交通安全に関する標語を発声することを半ば強制する機能を備えた車載電子装置を提供する。
【解決手段】車載電子装置が起動された時にデータベースから交通安全標語を取り出して表示手段に表示すると共に音声出力手段で発声させる。同時に表示した標語を発声するように音声と表示により運転者に促す。それに応えて運転者が標語を発声した場合には、発声した音声を認識して表示手段に表示した標語を正しく発声したか否かを判定し、正しかった場合のみ車載電子装置の機能の利用を認める。
(もっと読む)
対話的システムおよび対話的システムを制御する方法
本発明は、対話手段(2)と、該対話手段(2)を制御するための制御手段(6)とを有する対話的システム(1)を記載する。制御手段(6)は制御パラメータに反応する。制御パラメータは継承パラメータ(IP)と対話パラメータとを有する。継承パラメータ(IP)は一定であり、対話パラメータは外的因子(EF)によって影響される。外的因子(EF)の対話パラメータへの影響は、継承パラメータ(IP)に依存している。  (もっと読む)
(もっと読む)
61 - 71 / 71
[ Back to top ]