
国際特許分類[G06F15/17]の内容
物理学 (1,541,580) | 計算;計数 (381,677) | 電気的デジタルデータ処理 (228,215) | デジタル計算機一般 (4,503) | 各々が少くとも算術演算ユニット,プログラム・ユニットおよびレジスタをもつ2つ以上のデジタル計算機が結合されたもの,例.数個のプログラムの同時処理を行うためのもの (694) | プロセッサ間通信 (496) | 入力/出力型接続,例.チャネル,I/Oポート,を用いるもの (101)
国際特許分類[G06F15/17]に分類される特許
1 - 10 / 101
マルチコアプロセッサシステム、レジスタ利用方法、およびレジスタ利用プログラム
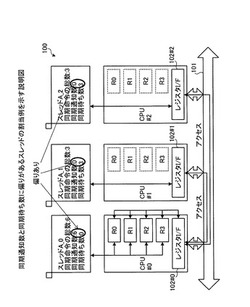
【課題】マルチコアプロセッサシステムでの処理能力の向上を図ること。
【解決手段】初めに、CPU#0は、CPU#0〜CPU#2に割り当てられるスレッドA_0〜スレッドA_2に関する同期命令に偏りがあることを示す情報を取得する。次に、CPU#0は、CPU#0のレジスタを共有元として、CPU#1、CPU#2がレジスタI/F102を通してCPU#0のレジスタにアクセスするようにレジスタI/F102#0〜レジスタI/F102#2に通知する。このように、マルチコアプロセッサシステム100は、CPU#0〜CPU#2のうち同期通知を実行するCPU#0のレジスタをCPU#1とCPU#2に共有させることにより、CPU#0〜CPU#2にてスレッドA_0〜スレッドA_2を実行する。
(もっと読む)
I/O制御装置およびI/O制御方法

【課題】他のコアプロセッサが初期化したI/O装置に対するI/O要求を受けた場合であっても、コアプロセッサがそのI/O要求に対応することができるようにすること。
【解決手段】I/O制御装置1において、マルチコアプロセッサ6と、マルチコアプロセッサ6のうち、SASコントローラ1d、DMAコントローラ1eの初期化を行ったコアプロセッサ1b、1cの識別情報を記憶する記憶手段3aと、を備え、コアプロセッサ1b、1cと異なるコアプロセッサ1aがSASコントローラ1dについてのI/O要求を受けると、コアプロセッサ1aは、記憶手段3aを参照して特定される、コアプロセッサ1bに対して、I/O要求の処理を依頼する。
(もっと読む)
データ中継制御装置、リンク間転送設定支援装置およびリンク間転送設定方法
【課題】共有メモリ方式のサイクリック伝送されているネットワークが複数存在する制御システムで、一つのネットワークの通信ノードから別のネットワークの通信ノードへ共有メモリ領域のデータを転送するリンク間転送の設定を人手によらず設定することができるデータ中継制御装置を得ること。
【解決手段】複数のネットワークにそれぞれ接続される複数のノード31,32と、複数のノード31,32間を通信路で接続するベースと、リンク間転送設定に基づいて、データを一のネットワークに接続されるノードから前記他のネットワークに接続されるノードに転送するリンク間転送制御部35と、プログラムで使用されるメモリ領域に付されたラベルと、ラベルが演算前にデータを格納する動作か、演算後のデータの行き先となる動作かを示すフラグ情報と、を有するラベル割付情報に基づいて、リンク間転送設定を生成するリンク間転送設定生成部33と、を備える。
(もっと読む)
情報処理装置及び画像形成装置
【課題】一つのチップの機能ブロックから別のチップの機能ブロックへデータを転送する場合に、予め定められた機能ブロックからのデータについては、転送遅延が生じないようにする。
【解決手段】監視部37は、第1の送信バッファ25に蓄積されているデータ量が、所定のしきい値を超えていれば、第1のチップ11と第2のチップ13との間でデータの転送遅延が発生するとみなす。しきい値を超えれば、第2にチップ13に配置された複数の第2の機能ブロックのうち予め定められた第2の機能ブロックについては、第2のチップ13において、第2の送信バッファを経由させずに第2の追越用ラインを経由させ、第1のチップ11において、第1の受信バッファ35を経由させずに第1の追越用ライン39を経由させて、宛先となる第1の機能ブロック19へ転送させる。
(もっと読む)
分散共有メモリ管理システム、分散共有メモリ管理方法、および分散共有メモリ管理プログラム
【課題】メモリを共有する異なるノードにおけるメモリ資源・通信資源の使用効率を高める。
【解決手段】固有メモリに格納されたデータ値を更新し、更新された値が予め設定された共通初期値と異なる場合に更新された値と該値の固有メモリにおけるアドレスを送出する計算ノードと、共有メモリに格納されたデータを共通初期値で初期化するデータ初期化機能と、計算ノードから更新データが送り込まれた場合に前記更新データに基づき前記共有メモリにおける対応するアドレスのデータを前記更新値へと更新する共有メモリデータ更新機能を有するメモリ管理装置を備える。
(もっと読む)
マルチプロセッサおよびそれを用いた画像処理システム
【課題】データの共有やデータ転送のバッファリングを容易に行なうことが可能なマルチプロセッサを提供すること。
【解決手段】複数の共有ローカルメモリ5−0〜5−(n−1)のそれぞれが、複数のプロセッサユニットPU0〜PU(n−1)(1−0〜1−(n−1))の中の2つのプロセッサに接続されており、複数のプロセッサユニットPU0〜PU(n−1)(1−0〜1−(n−1))と複数の共有ローカルメモリ5−0〜5−(n−1)とがリング状に接続される。したがって、データの共有やデータ転送のバッファリングを容易に行なうことが可能となる。
(もっと読む)
ルーティングのための方法及び装置
【課題】データプロセッサコアのサイズ及び遅延を小さくすること。
【解決手段】データプロセッサが開示され、該データプロセッサが、該データプロセッサ外部のデータ経路を通して要求をルーティングすることによって該データプロセッサのローカルメモリをアクセスする。予約/修飾コントローラが、ローカルメモリをアクセスするための受信される要求に関連される特定動作を実行される。特定動作に加えて、データプロセッサコアのローカルメモリをアクセスするために予約/修飾コントローラに関連するメモリコントローラが相当するアクセス要求をデータプロセッサコアにルーティングする。
(もっと読む)
プロセッサ、マルチプロセッサシステムおよびメモリ制御方法
【課題】ローカル命令メモリのサイズを実質的に拡大する形態でローカル命令メモリを各プロセッサ間で共有できるマルチプロセッサシステムにおけるプロセッサを提供する。
【解決手段】第1CPU100は、メモリ共有モード設定レジスタ107に格納された情報を参照することで、第1CPU100が命令フェッチを行うアドレスが、ローカル命令メモリ先頭アドレスレジスタ103とローカル命令メモリ終了アドレスレジスタ104とで定義される領域内であるか、または、共有命令メモリ先頭アドレスレジスタ105と共有命令メモリ終了アドレスレジスタ106とで定義される領域内であるかを判定し、その判定の結果に基づいてセレクタ102を制御することで、命令メモリ101と命令メモリ201とを切り替え、切り替え後の命令メモリから命令をフェッチして実行する。
(もっと読む)
アクセス装置及びアクセス方法
【課題】他の処理から見たときのアクセス処理によるオーバーヘッドを削減することを可能とするアクセス装置を提供する。
【解決手段】拡張ユニットと、前記拡張ユニットにアクセスする機能を有する1以上のアクセス装置と、を備える拡張記憶装置におけるアクセス装置であって、マルチコアCPU又は複数のCPUにより当該アクセス装置に複数のコアが備わるようにし、第1のコアでは、拡張ユニットアクセス専用ファームウェアが実行され、第2のコアでは、拡張記憶装置ファームウェアが実行され、前記拡張ユニットアクセス専用ファームウェアは、前記拡張ユニットにアクセスする処理の少なくとも一部を前記第1のコアに実行させるものであり、前記拡張記憶装置ファームウェアは、前記第2のコアで実行されるプログラムと前記拡張ユニットアクセス専用ファームウェアとの仲介をする処理を前記第2のコアに実行させるものである。
(もっと読む)
並列処理システム及び並列処理システムの動作方法
【課題】複雑な制御機能を設けることなく、処理性能を向上させることのできる、並列処理システム及び並列処理システムの動作方法を提供する。
【解決手段】並列処理システムは、ネットワークを介して互いにアクセス可能に接続され、複数の処理を分散して実行する、複数の計算機を具備する。前記複数の計算機の各々は、割り当てられた処理を実行する演算処理装置と、第1領域及び第2領域を有する、ローカルメモリ群と、入出力制御回路とを備える。前記演算処理装置は、第1期間において、前記第1領域をアクセス先アドレスとして処理を実行し、前記第1期間に続く第2期間において、前記第2領域をアクセス先アドレスとして処理を実行する。前記入出力制御回路は、前記複数の計算機間で通信を行なうことにより、前記ローカルメモリ群に格納されたデータを最新のデータになるように更新する、更新部を備える。前記更新部は、前記第2期間において、前記第1領域に格納されたデータを更新するように構成されている。
(もっと読む)
1 - 10 / 101
[ Back to top ]