
国際特許分類[G06F17/27]の内容
物理学 (1,541,580) | 計算;計数 (381,677) | 電気的デジタルデータ処理 (228,215) | 特定の機能に特に適合したデジタル計算またはデータ処理の装置または方法 (34,028) | 自然言語データの取扱い (7,890) | 自動言語解析,例.構文解析,綴字訂正 (543)
国際特許分類[G06F17/27]に分類される特許
21 - 30 / 543
注記データ翻訳装置、注記データ翻訳方法および注記データ翻訳プログラム
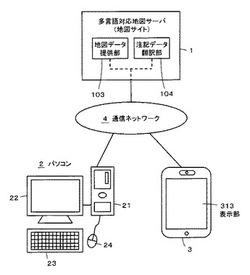
【課題】日本語の地図用の注記データを他の言語の地図用の注記データに適切に翻訳できるようにする。
【解決手段】抽出部104Aにより、ユーザからの提供要求に応じた地域の注記データを日本語注記DB106から抽出する。抽出した注記データのそれぞれの漢字部分について、第1の翻訳部104Dが、地域別漢字読み方辞書108を用いて正確な読み方の情報に翻訳する。抽出した注記データのそれぞれについて、第1の翻訳部104Dによっては翻訳できなかった漢字部分と、漢字以外の部分については、第2の翻訳部104Eがユーザからの要求に応じた言語の汎用翻訳辞書110を用いて翻訳する。
(もっと読む)
換喩判定プログラム及び情報処理装置

【課題】換喩を考慮せずに格要素が記述された格フレーム辞書を用いた場合であっても、文に換喩が含まれるか否かを判定する換喩判定プログラム及び情報処理装置を提供する。
【解決手段】情報処理装置1は、文から動詞及び当該動詞の格要素を抽出する換喩判定対象抽出手段101と、格フレーム情報111から、抽出した動詞と動詞の格要素の少なくとも1つとが一致する格フレームを検索する格フレーム検索手段102と、検索した格フレームのうち抽出した動詞と動詞の格要素とが一致する数の最も多い格フレームを基本格フレームとし、他の格フレームと比較する格フレーム比較手段103と、基本格フレームと他の格フレームとで一致しない格に含まれる格要素どうしから予め定めた方法で用例を生成し、当該用例が換喩判定用情報112に予め定めた頻度で出現する場合、文に換喩が含まれると判定する換喩判定手段104とを有する。
(もっと読む)
辞書作成装置、辞書作成方法、およびプログラム
【課題】効率的に言語解析用の辞書を作成する辞書作成装置等を提供する。
【解決手段】未知語判定プログラム25は、記憶部から書籍のOCRデータを入力し、書誌情報データベース21と照合して作者及びジャンルを特定するとともに、処理対象の語句が、未知語か否かを判定する。未知語の語句については、辞書登録プログラム26に処理を引き渡す。辞書登録プログラム26は、作者別辞書登録プログラム26A、ジャンル別辞書登録プログラム26Bを含み、作者別辞書データベース22、ジャンル別辞書データベース23、および標準辞書データベース24に未知語を登録する。
(もっと読む)
構文解析情報作成装置、翻訳装置、翻訳システム、構文解析情報作成方法およびコンピュータプログラム
【課題】 文字認識処理および翻訳処理の高精度化を図りつつ、文字を認識する速度の向上を図る。
【解決手段】 構文解析情報作成装置は、情報作成部1を備える。情報作成部1は、文法制約条件を示す第1構文解析情報(例えば、翻訳用の構文解析情報)から、解析対象の単語候補に対応する文法情報を抽出し、当該抽出した文法情報に基づいて、前記単語候補に対応する文法制約条件を示す第2構文解析情報(例えば、文字認識用の構文解析情報)を作成する。
(もっと読む)
単語対応付け装置、方法、及びプログラム
【課題】ベースとなる単語対応付けアルゴリズムに依存することなく、高精度かつ汎用性の高い単語対応付けを行う。
【解決手段】目的分野単語対応付け学習部12により、目的分野の対訳データを用いて目的モデルMinを学習し、一般分野単語対応付け学習部14により、一般分野の対訳データを用いて一般モデルMgenを学習する。目的分野対応付け確率推定部16により、目的モデルMinを用いて目的分野の対訳データを単語対応付けしたときの単語対応行列Ainに相当する確率Tij及びtijを推定し、一般分野対応付け確率推定部18により、一般モデルMgenを用いて同一の目的分野の対訳データを単語対応付けしたときの単語対応行列Agenに相当する確率Gij及びgijを推定する。単語対応行列生成部20により、確率Tij、tij、Gij及びgijを統合することにより、単語対応行列Aを生成する。
(もっと読む)
文書分析補助装置及び方法及びプログラム
【課題】 ブログやチャット等の短い文書の文書解析における曖昧性を解消する。
【解決手段】 本発明は、テキスト及び時刻を含む文書情報とユーザ情報を取得し、該文書情報を文書情報記憶手段に格納し、ユーザ情報に基づいてマイクロブログサービスから関係ユーザ情報を取得し、関係ユーザ情報に基づいてマイクロブログサービスから文書情報の時刻の任意の期間範囲の関係文書情報を取得して、文書情報記憶手段に格納し、文書情報記憶手段に格納されている文書情報と関係文書情報を時刻順にソートして1文として結合した解析対象文書を生成する。その上で解析対象文書を解析する。
(もっと読む)
同義語抽出システム、方法およびプログラム
【課題】情報システム構築に関する提案書や仕様書等、所定の案件に関する文書で、意義は同じで語形が異なる同義語のある文章の曖昧さを改善する。
【解決手段】文章に使用されている各単語毎の品詞や格、組み合される助詞、単語間の係り受け関係に関する単語情報の抽出を行う単語分析部と、任意の単語を基軸単語として選択し、基軸単語と共起関係にある共起語とその共起数に基づく基軸単語共起ベクトルを全基軸単語についてまとめた基軸単語共起表を作成する基軸単語共起表作成部と、単語の一般概念情報を概念データベースに問い合わせ、各基軸単語共起ベクトルの各共起語を概念に変換した基軸単語概念ベクトルを全基軸単語についてまとめた基軸単語概念表を作成する単語概念推定部と、各基軸単語概念ベクトル間の類似性を判定し、類似性が高い基軸単語の組合せを同義語候補として抽出する同義語候補推定部と、同義語候補を出力する同義語候補出力部とを備える。
(もっと読む)
複合語概念分析システム、方法およびプログラム
【課題】専門領域での複合語の多い文書中の複合語の概念を推定すること。
【解決手段】複合語を構成語に分割し、同一の構成語を持つ複合語間の共起ベクトルの距離に基づく集約度を構成語支配度として算出し、構成語支配度に基づき各構成語の概念に重み付けを行った合成概念として未知の複合語の概念を抽出することで、専門領域での複合語の多い文書中の複合語の概念を推定する。
(もっと読む)
多義語抽出システム、多義語抽出方法、およびプログラム
【課題】情報システム構築に関する提案書や仕様書といった特定の案件に関する文書群で一般的な意味と異なる意味を有して使用されている多義語を判別してその文章の曖昧さを改善する。
【解決手段】多義語抽出システムとして、入力を受けた所定の文章中の各単語を抽出する単語分析部と、任意の単語を基軸単語として選択し、該基軸単語と共起関係とみなされる基軸単語共起語とその共起数とで表される基軸単語共起ベクトルを抽出する基軸単語共起ベクトル抽出部と、基軸単語共起ベクトルの各基軸単語共起語の共起語概念を一般概念から推定する共起語概念推定部と、推定した共起語概念群について、対応する共起語概念間の類似性に基づき、選択した基軸単語に関する各基軸単語共起語のクラスタリングを行う共起語分類部と、複数のクラスタが存在した際に多義語候補として抽出する多義語候補推定部と、抽出した候補を出力する多義語候補出力部とを設ける。
(もっと読む)
同義語辞書生成装置、その方法、及びプログラム
【課題】文書テキストだけではなく音声テキストに基づいても、精度の高い同義語辞書を作成することができる同義語辞書生成技術を提供する。
【解決手段】同義語辞書を作成する際に基準となる基準語彙を含む文脈と、基準語彙に関連する関連語彙を含む文脈の類似性を算出し、基準語彙の表記と関連語彙の表記の類似性を算出し、基準語彙の読みと関連語彙の読みの類似性を算出し、算出された文脈、表記及び読みの類似性を用いて基準語彙及び関連語彙についての同義指標を求め、その同義指標の大きさに基づき関連語彙が基準語彙の同義語であるか否かを判定する。
(もっと読む)
21 - 30 / 543
[ Back to top ]