
国際特許分類[G06F17/27]の内容
物理学 (1,541,580) | 計算;計数 (381,677) | 電気的デジタルデータ処理 (228,215) | 特定の機能に特に適合したデジタル計算またはデータ処理の装置または方法 (34,028) | 自然言語データの取扱い (7,890) | 自動言語解析,例.構文解析,綴字訂正 (543)
国際特許分類[G06F17/27]に分類される特許
71 - 80 / 543
言語変換装置、言語変換方法及び言語変換プログラム
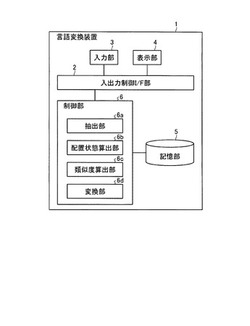
【課題】トレーサビリティマトリクスを容易に作成すること。
【解決手段】抽出部は、文字ファイルに含まれる文字列を相互の関連性に従って解析することで求めた文字ファイルの木構造において、各ノードに配置された文字列から第1の言語で示された所定の文字列群である第1文字列群と第2の言語で示された所定の文字列群である第2文字列群とをそれぞれ抽出する。配置状態算出部は、第1文字列群及び第2文字列群に含まれる文字列それぞれについて、木構造における配置状態から文字列相互の影響度を算出する。類似度算出部は、影響度に基づいて、第1文字列群に含まれる第1文字列に対する第2文字列群に含まれる第2文字列の関連性の高低を示す類似度をそれぞれ算出する。変換部は、文字ファイルにおける第1文字列を類似度が最も高い第2文字列に変換する。
(もっと読む)
文書処理装置及びプログラム

【課題】曖昧文を検出する際に、過剰検出や不適切な指摘内容の発生を低減させ、曖昧文の検出精度を向上できる。
【解決手段】実施形態の構文解析手段は、前記入力を受け付けた文を構文解析し、構文解析結果を得る。実施形態の抽出手段は、この構文解析結果に基づいて、前記場合に該当する文の構文解析結果から係り受け元、複数の係り受け先を含む係り受け情報を抽出する。実施形態の関係情報補正手段は、前記構文解析結果及び前記関係情報補正ルールに基づいて、前記係り受け情報が前記第1乃至第4の関係のいずれかに該当するか否かを検査すし、該当する係り受け情報に対して、前記関係情報補正ルールに規定された補正処理を行う。実施形態の指摘情報生成手段は、前記関係情報補正手段による処理の結果に基づいて、前記第1乃至第4の関係のいずれにも該当しないとき、前記曖昧文である旨を指摘する指摘情報を生成し、この指摘情報を出力する。
(もっと読む)
機能表現解析装置、素性重み学習装置、機能表現解析方法、素性重み学習方法、プログラム
【課題】同じ表層形を持つ機能表現が複数存在していても、形態素列に適切な意味ラベルを選択する。
【解決手段】本発明の素性重み学習装置と機能表現解析装置は、ラティス構築手段と最尤パス探索手段とを有するデコーディング部を備える。ラティス構築手段は、入力された形態素列に対して、意味ラベルが付与されたフレーズラティスを作成する。フレーズラティスは、機能表現辞書と形態素列表記が一致するフレーズ、機能語に分類される品詞を持つ形態素のフレーズ、述語に分類される品詞を持つ形態素のフレーズ、述語および機能表現ではないことを示す形態素のフレーズを含む。最尤パス探索手段は、素性に対する重みを格納したパラメータテーブルを用いてフレーズラティスから尤もらしいパスである最尤パスを探索する。素性には、形態素列と意味ラベルを対応つける素性と意味ラベル列を表す素性の両方が含まれる。
(もっと読む)
特徴語抽出装置、プログラム及び方法
【課題】テキストマイニングの対象となる文書のデータに対して適切な語の区切りを自動的に設定する。
【解決手段】本特徴語抽出装置は、複数の文書のデータが格納されている文書格納部と、当該複数の文書のデータのうち第1の文書のデータにおける文節の各々を、区切り位置及び区切りの数を変化させつつ分割し、当該分割により得られた文字列をデータ格納部に格納する生成部と、データ格納部に格納されている文字列の各々について、当該文字列が第1の文書のデータに出現する回数と文書格納部に格納されている複数の文書のデータのうち当該文字列が出現する文書のデータの件数とを用いて特徴度を算出する算出部と、第1の文書のデータにおける文節の各々について、当該文節についての文字列のうち特徴度が最も高い文字列を特定し、特徴語格納部に格納する特定部とを有する。
(もっと読む)
文章入力支援システム、文章入力支援装置、参照情報作成装置及びプログラム
【課題】利用者による操作入力に基づく作成中の文について、その続きに入力されることが予測される候補を提示するに際し、文が有する係り受け関係の情報を用いて候補となる語を提示する。
【解決手段】テキスト分割部32が、テキスト取得部31により得られた作成中(編集中)の文を形態素解析して形態素単位の語(文字列)に分割し、構文・意味解析部33がテキスト分割部32により得られた各語の係り関係及び意味役割を解析し、補完候補評価部34が、構文・意味解析部33による解析結果(文字入力位置の前の語に対する他の語の係り関係及び意味役割の関係)に基づいて、各種スコアDB12を参照して補完入力候補となる候補語を検索すると共に各候補語のスコアを算出し、補完候補提示部36が、補完候補評価部34により得られた候補語をスコア順に提示する。
(もっと読む)
学習装置、判定装置、学習方法、判定方法、学習プログラム及び判定プログラム
【課題】照応解析において先行詞及び照応詞を判定する精度を向上可能な照応解析技術を提供する。
【解決手段】学習装置は、文章と、前記文章内で照応関係を有する各要素の後方境界と、先行詞となる第1の要素及び照応詞となる第2の要素の対応関係とを示す訓練データの入力を受け付け、訓練データに基づいて、任意の文章において照応関係の有無を判定するための判定基準を学習する。判定装置は、文章と、前記文章内で照応関係を有する可能性のある各要素の後方境界とを示すユーザデータの入力を受け付け、ユーザデータに基づいて、学習装置が学習した判定基準に従って、文章において照応関係の有無を判定する。
(もっと読む)
形態素列変換装置、形態素変換学習装置とそれらの方法とプログラム
【課題】形態素体系の異なる2つの形態素解析システムを用いずに、或る形態素列を異なる品詞体系の形態素列に変換する形態素列変換装置を提供する。
【解決手段】この発明の形態素列変換装置は、フレーズテーブルと未知語テーブルとパラメータテーブルとラティス構造構築部と最尤フレーズ対列探索部と出力形態素列作成部と、を具備する。ラティス構造構築部は、変換元形態素列に対して、フレーズテーブルと未知語テーブルを参照して入力形態素列に対応するフレーズ対を取得してフレーズラティスを構築し、最尤フレーズ対列探索部は、フレーズラティスの最尤フレーズ対列をパラメータテーブルを参照して探索する。そして、出力形態素列作成部が、最尤フレーズ対列から変換先形態素を取り出して出力することで、形態素解析器を用いることなく、変換元の形態素列を変換先の形態素列に変換する。
(もっと読む)
データ抽出装置、データ抽出方法、及びプログラム
【課題】人手による修正コストを小さくし、かつ、セマンティックドリフトを効率的に軽減する
【解決手段】正例エンティティに対応する正例トピック情報を正例エンティティの素性の少なくとも一部とし、負例エンティティに対応する負例トピック情報を負例エンティティの素性の少なくとも一部とし、正例エンティティの素性と負例エンティティの素性とを教師あり学習データとした学習処理によって識別モデルを生成し、対象エンティティに対応するトピック情報を当該対象エンティティの素性の少なくとも一部とし、対象エンティティが正例エンティティか負例エンティティかを識別する。また、トピック情報の関する情報を人手によって修正する。
(もっと読む)
言語モデル学習装置、言語モデル学習方法、言語解析装置、及びプログラム
【課題】事前に与えた基準を守りつつ、それと異なる新しい文字列又は記号列を高精度に分割する。
【解決手段】識別モデルパラメータ更新部25によって、NPYLMをCRFに変換し、変換したCRFの各エッジの重みと、CRFにおける対応するエッジの重みとを用いて第1の統合モデルを作成し、第1の統合モデルを、教師ありデータに基づいて学習する。生成モデルパラメータ更新部26によって、CRFをSemi−Markov CRFに変換し、Semi−Markov CRFの各エッジの重みとNPYLMの対応するエッジの重みとを用いて第2の統合モデルを作成し、第2の統合モデルを、教師なしデータに基づいて学習する。収束判定部27によって所定の収束条件を満たしたと判定されるまで、識別モデルパラメータ更新部25による更新と生成モデルパラメータ更新部26による更新とを交互に繰り返す。
(もっと読む)
要求獲得支援装置、要求獲得支援方法、およびプログラム
【課題】各種システムやソフトウェアに対する顧客からの要求をより確実に獲得することができる要求獲得支援装置を提供する。
【解決手段】要求獲得支援装置として、ヒアリング案件に関する要求関連文書データを入力する情報登録手段と、要求関連文書データ文章中の多義的に捉えられ得る曖昧ポイントを抽出し、抽出した個々の曖昧ポイントについて曖昧性の特徴に基づく曖昧性の種類を示す曖昧性分類を決定する要求関連文章分析手段と、要求関連文書データの曖昧性をヒアリング実施者の立場から定量化して要件把握性として定義する要件把握性評価手段と、要求関連文書データにおける個々の曖昧ポイントについて、曖昧性分類と要件把握性に基づき分析して、質問に適したヒアリング時に提供するヒアリングアドバイスを候補から選択するヒアリングアドバイス分析手段と、選択されたヒアリングアドバイスを表示するヒアリングアドバイス表示手段とを設ける。
(もっと読む)
71 - 80 / 543
[ Back to top ]