
国際特許分類[G10L15/02]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 音声認識 (6,879) | 音声認識のための特徴抽出;認識単位の選択 (203)
国際特許分類[G10L15/02]に分類される特許
41 - 50 / 203
周期特定装置およびプログラム

【課題】音響信号が倍音成分を含む場合でもピッチ周期を高精度に特定する。
【解決手段】ピーク検出部24は、音響信号Aの正側ピークQPの強度LPと負側ピークQMの強度LMとを特定する。指標算定部32は、強度LP[n-2]および強度LP[n]の平均値と強度LP[n-1]との差分値の絶対値と、強度LM[n-2]および強度LM[n]の平均値と強度LM[n-1]との差分値の絶対値とを加算することで変化指標値F[n]を算定する。周期特定部44は、変化指標値F[n]が閾値TH[n]を下回る場合には正側ピークQP[n-1]や負側ピークQM[n-1]を考慮して音響信号Aのピッチ周期Tpを特定し、変化指標値F[n]が閾値TH[n]を上回る場合には正側ピークQP[n-1]や負側ピークQM[n-1]を無視して音響信号Aのピッチ周期Tpを特定する。
(もっと読む)
音声推定インタフェースおよび通信システム
ユーザが騒々しい環境または社会的に敏感な環境で、声を出さずに、または聞こえるように話す間、ユーザの音声を推定するために、閾値下の音波でユーザの声道を探る音声推定(VE)インタフェースを有する装置。一実施形態では、VEインタフェースは携帯電話に組み込まれ、携帯電話がネットワークを通じて推定音声信号を遠隔通話相手に送り、(i)ユーザは、例えばミーティング、会議、映画、または公演において他の人々に迷惑をかけることなく遠隔通話相手と会話することができるようになる、(ii)遠隔通話相手は、そうでなければユーザが例えばナイトクラブ、ディスコ、もしくは飛行中の航空機にいることによる比較的大きな周囲雑音によってかき消されることになるユーザの声をより明瞭に聞くことができるようになる。 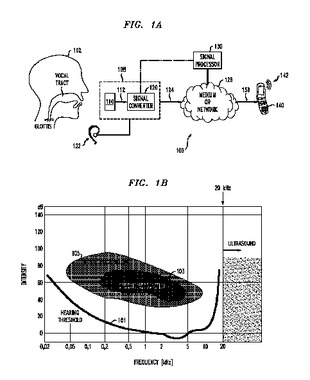 (もっと読む)
(もっと読む)
音響分析パラメータ生成方法とその装置と、プログラムと記録媒体

【課題】音響分析パラメータ生成方法を高速・省メモリ化する。
【解決手段】この発明の音響分析パラメータ生成方法は、入力フレーム選択過程と、出力確率計算過程と、スコア計算過程と、スコア評価過程と、最適調整パラメータ候補記録過程と、調整パラメータ管理過程とを含む。入力フレーム選択過程においてスコア計算に用いる音声ディジタル信号の一部の区間を選択する。選択した区間の音響特徴量と音響モデルとを用いてフレーム毎の各状態の出力確率を計算し、最尤状態系列を所定フレーム数に渡って累積して出力確率スコアを求め、出力確率スコアが最大になる調整パラメータを、それ以降に使用する最適調整パラメータとして出力する。
(もっと読む)
基本周波数変化量抽出装置、方法及びプログラム
【課題】基本周期の範囲を事前に限定せずとも、背景雑音の影響が低減された基本周波数変化量が得ることが可能な技術を提供する。
【解決手段】対数周波数スペクトログラム計算部101は、フレーム毎に入力された音声信号について、対数周波数スペクトログラムを計算する。ハフ変換部102は、対数周波数スペクトログラム計算部101が計算した対数周波数スペクトログラムについて、周波数成分の強さを用いて投票を行うことにより、直線を検出するためのハフ変換を行う。直線群抽出部103は、ハフ変換部102が出力した投票値を用いて、基本周波数変化量の計算に用いる対象となる直線群と対象投票値とを抽出する。基本周波数変化量計算部104は、直線群抽出部103が抽出した直線群に含まれる個々の直線の傾きと対象投票値とを用いて、基本周波数変化量を計算する。
(もっと読む)
調音特徴抽出装置、調音特徴抽出方法、及び調音特徴抽出プログラム
【課題】未知語への対応が可能であり、音声対話や音声検索からの要求に耐えうる高い音素識別精度を有する調音特徴抽出装置、調音特徴抽出方法、及び調音特徴抽出プログラムを提供する。
【解決手段】調音特徴抽出装置では、入力部201より入力された音声がA/D変換部202においてデジタル変換され、特徴分析部210においてフーリエ解析及びフィルタリングされた結果、音声スペクトルデータが得られる。次いで、調音特徴抽出部220において、調音特徴の時系列データである調音特徴系列が抽出される。そして調音運動修正部230において、調音特徴系列の変位成分より速度成分と加速度成分とが抽出され、さらに各成分に基づき、ニューラルネットワークを経ることにより、調音運動が修正される。そして修正された調音運動に基づき、単語分類部204において該当する単語が検索され、音声認識処理が実行される。
(もっと読む)
音声認識装置及びそれを搭載した輸送機器
【課題】単語辞書の作成に事前調査を必要としない音声認識装置を提供する。
【解決手段】音声認識装置10は、音響信号の中から音声信号を含む発話区間を検出する発話区間検出部11と、発話区間検出部11により検出された発話区間内の音声信号を分析することにより、その音声信号から音響特徴量を抽出する特徴量抽出部12と、複数種類の単語がモーラ数でソートされて登録されている単語辞書13と、単語辞書13に登録された単語の音響特徴量が登録されている音響モデル14と、単語辞書13及び音響モデル14を参照し、特徴量抽出部12により抽出された音響特徴量を単語辞書13に登録された各単語の音響特徴量と照合することにより各単語の尤度を算出し、最尤度の単語を認識結果とする照合部15とを備える。
(もっと読む)
発話区間検出装置
【課題】複数のマイクが不要で、単チャネルの音声に対しても適用可能な発話区間検出装置を提供する。
【解決手段】発話区間検出装置22は、音響データを所定時間ごとにフレームに分割するフレーム分割部23と、フレーム分割部23により分割された音響データをフレームごとに高速フーリエ変換する高速フーリエ変換部14と、高速フーリエ変換部24によりフーリエ変換された音響データを微分して微分係数を算出する微分部25と、微分部25により算出された微分係数の度数分布に基づいて音声を含む音声フレームを判定する音声フレーム判定部26とを備える。
(もっと読む)
発話区間話者分類装置とその方法と、その装置を用いた音声認識装置とその方法と、プログラムと記録媒体
【課題】事前の話者登録を無くす。
【解決手段】この発明の発話区間話者分類装置は、音量音声区間分割部と、特徴量分析部と、代表特徴量抽出部と、セグメント分類部と、セグメント統合部と、を具備する。音量音声区間分割部は、離散値化された音声信号の音声区間検出を行い音声区間セグメントを出力する。特徴量分析部は、音声区間セグメントの音響特徴量分析を行い音響特徴量を出力する。代表特徴量抽出部は、音響特徴量から音声区間セグメントの代表特徴量を抽出する。セグメント分類部は、代表特徴量のそれぞれの間の距離を計算して距離に基づいて音声区間セグメントをクラスタに分類する。セグメント統合部は、隣接する上記音声区間セグメントが同一クラスタに属する場合に、隣接する音声区間セグメントを1個のセグメントとして統合する。
(もっと読む)
音響分析パラメータ生成装置とその方法と、それを用いた音声認識装置と、プログラムと記録媒体
【課題】音響分析パラメータ生成装置を高速・省メモリ化する。
【解決手段】この発明の音響分析パラメータ生成装置の出力確率計算部は、調整パラメータを用いて算出されたフレーム単位の音響特徴量と音響モデルとを入力としてフレーム毎の各状態の出力確率を計算する。スコア計算部が、出力確率の最尤状態系列を所定フレーム数に渡って累積して出力確率スコアを求める。スコア評価部は、出力確率スコアを評価して出力確率スコアが最大になる調整パラメータを最適調整パラメータ候補として出力する。最適調整パラメータ候補記録部が、その最適調整パラメータ候補を記録する。所定フレーム数に対して調整パラメータをそれぞれ出力した後に記録した最適調整パラメータ候補を調整パラメータとして出力する。
(もっと読む)
話者認識装置と話者認識方法およびプログラム
【課題】簡単かつ容易に話者認識を行うことができるようにする。
【解決手段】係数蓄積部40には、音声波形を予測するための予測係数を話者毎に蓄積させておく。予測波形生成部33は、入力音声の音声データと予測係数を用いた演算を行い、話者毎に予測波形を生成する。予測誤差算出部34は、入力音声の音声波形に対する予測波形の誤差を話者毎に算出する。話者特定部35は、算出された話者毎の誤差に基づいて、入力音声の話者を特定する。予測係数は、話者の音声データに対して線形予測分析を行って得られた線形予測係数を用いる。時間領域を周波数領域に変換する処理等を行う必要がなく、時間領域で話者認識を行えるようになる。
(もっと読む)
41 - 50 / 203
[ Back to top ]