
日本電信電話株式会社により出願された特許
1,101 - 1,110 / 13,992
音素ラベリングデータ音素継続時間長変換方法とその装置とプログラム
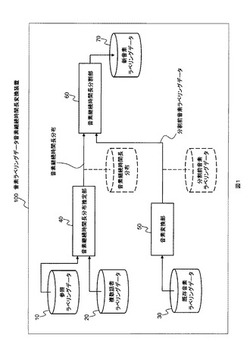
【課題】少量の音素ラベリングデータから新音素体系の大量の音素ラベリングデータを精度良く生成する音素ラベリングデータ音素継続時間長変換装置を提供する。
【解決手段】音素継続時間長分布推定部は、変換対象話者の新音素体系における少数の音素ラベリングデータである参照ラベリングデータと、複数話者のある音素体系における音素種別の音素継続時間長の平均値・分散値を、統計的に信頼できる値として得ることが可能な数の複数話者ラベリングデータを入力として、参照ラベリングデータを複数話者ラベリングデータで直線回帰し、複数話者ラベリングデータの全ての音素種別に対応する変換対象話者の音素継続時間長の平均値と分散値である音素継続時間長分布を求め、1個の音素継続時間長に対して複数の音素情報を持つ音素ラベリングデータを、音素情報毎に時間長を分割して新音素ラベリングデータとして出力する。
(もっと読む)
文書分割スコアリング装置、方法、及びプログラム

【課題】各文書の最終的なスコアを、より適切なものとする。
【解決手段】文書分割手段11で、他の文書へのリンクを持ちうる文書の集合中の一部または全部の文書に対し、各文書を同一トピックの区間であるトピック区間に分割し、文書置換手段12で、文書分割手段11の処理後の各文書Aと文書Aへの各リンクLとに対し、リンクLを持つ文書中の、リンクLのアンカーテキスト、または、リンクLを含むトピック区間との類似度が、所定の閾値以上または上位所定順位以内の文書Aのトピック区間の集合の異なりを新たな文書A’として生成し、リンクLに文書A’を対応付け、文書A’が対応付けられたリンクのみを文書A’へのリンクとし、文書Aを文書A’の集合に置き換え、文書スコアリング手段13で、文書置換手段12の処理後の文書集合とリンク集合とから、文書集合中の各文書のスコアを算出する。
(もっと読む)
モデル生成方法及びモデル生成装置
【課題】購入履歴のないユーザのロイヤルティを計測可能にすること。
【解決手段】実施形態に係るモデル生成装置は、商品の購入履歴を説明変数としてロイヤルティである目的変数を求める既存モデルに対して、説明変数を購入履歴以外の他の履歴情報に置き換えた代替モデルを複数生成する。また、モデル生成装置は、代替モデルに対する他の履歴情報の適合度を示す評価値を算出する。また、モデル生成装置は、使用可能な説明変数である使用可能変数の入力を受け付ける。また、モデル生成装置は、複数の代替モデルから使用可能変数に他の履歴情報が含まれる代替モデルを抽出し、抽出した代替モデルのうち評価値が最も高い代替モデルを提示する。
(もっと読む)
ゲストOS配置システム及びゲストOS配置方法
【課題】ゲストOSが配置される最適なホストコンピュータを決定すること。
【解決手段】決定部30aは、ネットワークを介して複数のホストコンピュータ(ホスト群)と接続されるユーザ端末の位置情報に基づいて、ユーザ端末との距離が最短となるホストコンピュータをホスト群から選択し、当該選択したホストコンピュータを、ユーザ端末が使用するゲストOSを配置するホストコンピュータとして決定する。制御部30bは、決定部30aが決定したホストコンピュータをアクセス先とするようにユーザ端末を制御する。
(もっと読む)
ソート時のキー削減方法及び装置及びプログラム
【課題】 基数ソート毎に発生する読み出しと書き出しデータ量の削減を行う。
【解決手段】 本発明は、入力された並び替え対象の整数列を部分ソート列記憶手段に格納し、入力された並び替え対象の整数列の上位Kビットを対象として、ソート処理手段から指定された上位Kビットのビット位置の出現頻度のヒストグラムを作成し、ヒストグラム記憶手段に格納し、ヒストグラム記憶手段から読み出したヒストグラムに基づいて、上位Kビットを並び替えた部分ソート列を部分ソート列記憶手段に格納する処理をM/K(但し、M:整数対象、K:基数ソートを行う単位)回繰り返し、整列済みの整数列を生成する。
(もっと読む)
情報検索方法、情報検索装置及び情報検索プログラム
【課題】ある語句に関連した文書を文書集合から容易に抽出することを可能とすること。
【解決手段】属性値が付与されている複数の文書からなる文書集合を対象として、指定された特定の語句の出現頻度と属性値との関係を求め、前記特定の語句の出現頻度が高い属性値を特定し、前記文書集合を対象として、前記特定の語句とは異なる複数の他の語句それぞれについて出現頻度と属性値との関係を求め、前記複数の他の語句の中から、前記特定の語句と同じ属性値で前記出現頻度が高くなる語句を関連語句の候補として選択し、前記特定の語句を含む前記文書と、前記関連語句の候補を含む前記文書と、に基づいて、前記特定の語句によって指し示される概念と関連性の高い文書を検索し、前記検索の結果を出力する。
(もっと読む)
WEB情報先読み方法、先読み代理サーバ装置および情報蓄積サーバ装置
【課題】データ先読みによって、WEB閲覧装置で表示されるWEB情報の文字化けおよびレイアウトの崩れを解消する。
【解決手段】先読み代理サーバは、WEB閲覧装置から送信された第1の要求データをWEBサーバに転送し、WEBサーバから送信された第1の要求データに対応するWEB情報をWEB閲覧装置に転送し、さらに当該WEB情報から第2の要求データを生成してWEBサーバに送信し、WEBサーバから第2の要求データに対応する先読みのWEB情報を受信し、さらに第1の要求データに対応するWEB情報を取得したWEB閲覧装置から第3の要求データを受信し、同一のWEB情報を要求する前記第2の要求データと当該第3の要求データのヘッダ情報が一致するときに、先読みのWEB情報をWEB閲覧装置に転送し、両者が不一致のときに第2の要求データおよび先読みのWEB情報を削除し当該第3の要求データをWEBサーバに送信する。
(もっと読む)
WEB情報先読み方法および先読み代理サーバ装置
【課題】WEB閲覧装置と先読み代理サーバのブラウザの違いによるWEB情報の不具合発生を防止する。
【解決手段】先読み代理サーバは、WEB閲覧装置から送信された第1の要求データをWEBサーバに転送して、WEBサーバから送信された第1の要求データに対応するWEB情報をWEB閲覧装置に転送するとともに、当該WEB情報から第2の要求データを生成し、当該第2の要求データのヘッダ情報を第1の要求データから抽出されたヘッダ情報に置き換えてWEBサーバに送信し、WEBサーバから送信された第2の要求データに対応する先読みのWEB情報を受信するとともに、第1の要求データに対応するWEB情報を取得したWEB閲覧装置から送信された第3の要求データを受信し、第2の要求データと第3の要求データが一致するときに先読みのWEB情報をWEB閲覧装置に転送する。
(もっと読む)
辞書管理装置、辞書管理方法、辞書管理プログラム
【課題】オンライン辞書について辞書管理の負担を軽減させた高品質な類似検索機能を提供する。
【解決手段】類似検索部3は、辞書管理者の入力表記に基づき全体辞書を検索し、入力表記に類似する表記を特定する。主要部特定部4は、類似検索手段で特定された類似表記と入力表記との共通部分を特定し、特定された共通部分が主要部辞書に存在すれば、該共通部分を主要部候補と判定する。この主要部候補を類似表記から除外した付加部候補が付加部辞書に存在するか否かを判定し、判定結果に応じて主要部候補を主要部と確定する。距離算出部5は、確定された各類似表記の主要部と入力表記の主要部との編集距離を算出する。更新確認部6は、算出された編集距離順に類似表記・主要部・付加部を辞書管理者に提示する。
(もっと読む)
検索条件抽出装置、検索条件抽出方法および検索条件抽出プログラム
【課題】検索の隠れ条件となる語句を、検索クエリとして使われやすい語句を用いて表現し抽出することができるようにする。
【解決手段】検索実行時の入力クエリ情報とその検索結果情報と閲覧有無情報とを入力とし、前記検索結果情報を語句に分割し、各語句の出現情報を集計して出現語句バッファ260bに出力する閲覧情報解析部250と、出現語句バッファ260b中の情報を解析し、閲覧した検索結果情報中で有意に出現頻度が高い語句を隠れ条件候補語句として候補語句バッファ270bに出力する候補語句抽出部260と、候補語句バッファ270b中の候補語について、検索対象データベース220中で入力クエリ語句と共起する確率と、検索クエリデータベース230上で入力クエリ情報と共起する確率とを比較し、有意に検索クエリとして使われやすい語句を隠れ条件語句として出力する候補語句絞込部270とを備える。
(もっと読む)
1,101 - 1,110 / 13,992
[ Back to top ]