
グーグル・インコーポレーテッドにより出願された特許
71 - 80 / 191
メディアコンテンツアイテムへの注釈付け
一般的な一態様では、メディアコンテンツアイテムが複数のユーザに提供され、メディアコンテンツアイテムは時間的長さを有する。メディアコンテンツアイテムに対する注釈が、複数のユーザから受信され、注釈はそれぞれ、時間的長さの間の提示時間を定義する、関連する時間データを有する。受信された注釈が、メディアコンテンツアイテムに関連付けられ、その結果、注釈が、メディアコンテンツアイテムの提示中に、時間的長さの間のほぼ提示時間に提示される。  (もっと読む)
(もっと読む)
検索クエリーに応答したディスカッションスレッドへの投稿の提供
検索クエリーに応答してディスカッションスレッドへの投稿を提供する、コンピュータプログラム製品を含む、システム、方法、および装置である。この方法は、検索エンジンにより検索クエリーを満たすと識別された複数のリソースを識別する情報を受信し、複数のリソースの中で第1のリソースをディスカッションフォーラムへの投稿を含むと識別し、各々が第1のリソースと異なる1つまたは複数の第2のリソースを識別することを含む。第2のリソースの各々は第1のリソースに直接または間接にリンクされ、ディスカッションフォーラムへの1つまたは複数の他の投稿を含む。さらに、この方法は、ディスカッションフォーラムについて第1のリソースおよび1つまたは複数の第2のリソースから情報を抽出し、検索クエリーへの応答の一部として、抽出された情報を第1のリソースへのリンクとともにユーザへの表示のためにユーザ装置に提供することを含む。  (もっと読む)
(もっと読む)
コンテンツアイテムの選択
表示環境に対するリクエストに応答して、表示環境で(例えば、マップ上またはマップの隣に)掲載するためのコンテンツアイテム、例えばアイコンまたは広告コンテンツが、表示環境を要求しているユーザにコンテンツアイテムが関係する確率に基づいて選択される。上記選択は、マップスペースが提示されている間にユーザデバイスから受信されうるコンテンツターゲティングデータ(例えば、特徴の選択や照会の提出)によって容易に行える。  (もっと読む)
(もっと読む)
クエリ識別および関連付け
広告用の予測的クエリ識別のための装置、システム、および方法が開示される。候補クエリが、クエリログに格納されたクエリから識別される。複数のウェブ文書について関連性スコアが生成され、各関連性スコアは、対応するウェブ文書に関連付けられ、かつ、ウェブ文書に対する候補クエリの前記関連性の尺度である。関連性閾値を超える関連付けられた関連性スコアを有するウェブ文書が選択される。選択されたウェブ文書は候補クエリに関連付けられる。  (もっと読む)
(もっと読む)
埋込みアプリケーションにおける地理的コンテキスト、およびキーワードコンテキスト
埋込みクライアントアプリケーションを使用して、埋込みクライアントアプリケーションを保持するコンテナ文書についてのキーワードコンテキストを生成するステップと、埋込みクライアントアプリケーションを使用して、コンテナ文書が表示される装置に関連付けられた地理的コンテキストを生成するステップと、キーワードコンテキストおよび地理的コンテキストを遠隔サーバに提出するステップと、キーワードコンテキストおよび地理的基準の提出に応答して取得された情報を使用して対話型アプリケーションを表示するステップとを含む、コンピュータで実行される方法。  (もっと読む)
(もっと読む)
広告のためのパノラマ又は3Dマッピング環境における不動産の請求
不動産のオンライン地理的表示で特徴のグループを識別し、広告情報で特徴のグループを置換及び/又は補強する方法が開示される。方法は、オンライン財産管理システムの中に財産の地理的表示を提供するステップと、不動産領域の少なくとも一部を含む地理的表示において関心領域を識別するステップと、不動産領域の上に配置された地理的表示の中の1又は複数の販売促進特徴の位置を決めるために地理的表示を分析するステップと、地理的表示における関心領域に関連付けられたユーザが選択可能なリンクを提供するステップと、ユーザが選択可能なリンクを介して地理的表示における関心領域についてリクエストを受信するステップと、関心領域の動き又は外観のうちの少なくとも1つを変更するためのデータを受信するステップと、地理的表示と関連してデータを格納するステップと、受信されたデータに基づき地理的表示の中の関心領域を更新するステップとを含む。  (もっと読む)
(もっと読む)
入力文字列からのリソースロケータの提案
コンピュータプログラム製品を含む方法、システム、及び装置であって、インプットメソッドエディタが、ローマ字入力を受け取り、非ローマ字の候補セットに関するキーワードを識別し、関連するリソースロケーションを識別する、コンピュータプログラム製品を含む方法、システム、及び装置が提供される。関連するリソースロケーションを識別すると、非ローマ字の候補セットに、リソースロケーションを関連付ける。  (もっと読む)
(もっと読む)
並列認識タスクを用いた音声認識
本明細書の主題はとりわけ、音声信号を受け取ること、および複数の音声認識システム(SRS)で音声認識タスクを開始することを含む方法で実施される。各SRSは、音声信号内に含まれる予想される音声を指定する認識結果と、音声結果の正確さの信頼度を示す信頼値とを生成するように構成される。この方法はまた、1つまたは複数の認識結果、および1つまたは複数の認識結果に関する1つまたは複数の信頼値を生成することを含む音声認識タスクの一部を完了すること、1つまたは複数の信頼値が信頼閾値を満たすかどうかを判定すること、認識結果の生成を完了していないSRSに関する音声認識タスクの残りの部分を停止すること、および生成した1つまたは複数の音声結果のうちの少なくとも1つに基づいて最終的な認識結果を出力することをも含む。  (もっと読む)
(もっと読む)
機械翻訳に対するパラメータの最適化
言語翻訳のための、コンピュータプログラム製品を含む、方法、システム、および装置が開示される。一実施形態では、方法が提供される。この方法は、仮説空間にアクセスするステップと、証拠空間に関して計算された分類の予想される誤りを最小化する翻訳仮説を得るために仮説空間上でデコードを実行するステップと、ターゲット翻訳において提案された翻訳としてユーザーが使用するための得られた翻訳仮説を提供するステップとを含む。 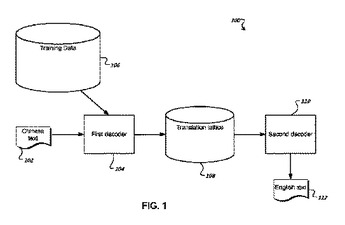 (もっと読む)
(もっと読む)
ウェブページコンテンツの注釈
特に、ウェブページコンテンツを注釈するためのコンピュータで実行される方法は、ブラウザでウェブページにアクセスするステップを含み、前記ウェブページはサードパーティによって制御される。記憶場所に格納された注釈の集合が検索される。前記注釈の集合は、前記ウェブページと注釈作成者とに関連づけられている。前記ウェブページは、前記検索された注釈の集合が前記アクセスされたウェブページ上にオーバレイされるように表示される。  (もっと読む)
(もっと読む)
71 - 80 / 191
[ Back to top ]