
Fターム[5B034BB04]の内容
ハードウェアの冗長性 (4,130) | 能動的冗長 (1,216) | 切替 (670) | 選択 (77)
Fターム[5B034BB04]の下位に属するFターム
信頼度 (13)
Fターム[5B034BB04]に分類される特許
1 - 20 / 64
半導体装置
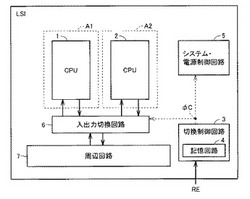
【課題】寿命が長い半導体装置を提供する。
【解決手段】このLSIは、2つのCPU1,2と、CPU1,2のうちのいずれか1つのCPUを示す論理レベルのデータ信号が書き込まれた記憶回路4と、リセット信号REが非活性化レベルにされてLSIのリセットが解除された場合、記憶回路4の記憶データの論理レベルに対応するCPUのみに電源電圧を供給するとともに、記憶回路4の記憶データを現在の論理レベルと異なる論理レベルのデータ信号に書き換える制御回路3,5とを備える。したがって、故障の検知や、厳密なタイミング制御を必要とせずに、CPUの長寿命化を図ることができる。
(もっと読む)
冗長化システム

【課題】N+m冗長化構成において、複数台の現用系ルータに障害が発生したときにでも、通信性能の低下を抑制すること。
【解決手段】N+m冗長化する冗長化システムであって、ルータ1のイベント検出部13が、所定のVRRPグループに属する現用系のルータ1に障害が発生したときに、新たな現用系として切り替える旨の切り替えイベントを、設定記憶部12のステートを監視することで検出し、イベント対処部14が、イベント検出部13により検出された切り替えイベントの対象となる所定のVRRPグループを特定し、その特定した所定のVRRPグループ以外のVRRPグループについて、自身の現用系の選出頻度を下げる。
(もっと読む)
マスター/スレーブシステム、制御装置、マスター/スレーブ切替方法、および、マスター/スレーブ切替プログラム
【課題】マスター/スレーブ構成のシステムにおいて、マスターとスレーブの切替を適切に行い、システムの信頼性を高める。
【解決手段】スレーブ状態の制御装置10Bは、他の全ての制御装置から各制御装置自身に関する情報を取得する情報取得手段と、取得した情報に基づいて自制御装置が新たなマスター候補であるか否かを判別し、新たなマスター候補である場合にマスター状態の制御装置10Aにマスター交代要求を送信する判別手段とを備え、マスター状態の制御装置10Aは、スレーブ状態の複数の制御装置10Bからマスター交代要求を受信すると、マスター交代要求を送信したいずれかの制御装置を、新たなマスターとして決定するマスター決定手段を備える。
(もっと読む)
冗長構成をとるコントローラ
【課題】冗長系の切り替えを安全に実施し、制御の引き継ぎが完了するまでの時間を短縮する。
【解決手段】コントローラ1は、ホスト機能部30を有する主系制御モジュール10と、ファンクション機能部71を有する入出力モジュール70−n(nは自然数)と、ファンクション機能部60−nおよびホスト機能部30A−nを有する待機系制御モジュール10A−nがシステムバス90で接続されている。主系制御モジュール10は、入出力モジュール70−nを制御すると共に、ファンクション機能部71の接続を構成する構成情報31を、ファンクション機能部60−nへ所定のタイミングで繰り返し通知し、待機系制御モジュール10A−nは、ファンクション機能部60−nが受信した構成情報31を保持し、構成情報31の通知が途絶したとき、構成情報31−nに基づいて入出力モジュール70−nを引き継いて制御する。
(もっと読む)
計算機システムでの部分障害処理方法
【課題】 論理分割可能な計算機では、ハードウェア障害が発生しても、障害の影響を受けないLPARは実行を継続可能な場合がある。この場合、ハードウェア保守で計算機全体を停止しなければならない時に、継続稼働しているLPARを停止してよいのか容易に判断できない。
【解決手段】 計算機で発生したハードウェア障害について、ハイパバイザが、実行継続可能なLPARに実行継続可能なハードウェア障害として障害発生を通知し、それを受けたLPARが障害対応処理を実行したことをハイパバイザに通知し、その通知状況を取得するためのインタフェイスをハイパバイザが提供する。このインタフェイスを通じて、LPARごとの実行継続可能なハードウェア障害への対応状況を登録・取得可能とし、計算機全体での対応状況を判定可能とする。
(もっと読む)
マルチプロセッサシステム
【課題】メインプロセッサの故障が発生した場合でもシステムとしての稼働率の低下を防止し、ライフサイクルコストの上昇を抑えることのできるマルチプロセッサシステムを得る。
【解決手段】C0A動作監視手段306は、ボードの起動処理を行うメインプロセッサの状態を監視する。C0A動作監視手段306がメインプロセッサの非動作状態を検知した場合、C0A隔離手段307はメインプロセッサとなっているプロセッサを隔離すると共に、特権管理表更新手段303は特権管理表を更新する。C0B通知手段308は、更新された特権管理表に基づいて新たなプロセッサに対してメインプロセッサとなることを通知する。
(もっと読む)
計算機システム
【課題】 リソースの使用量などの選択条件を考慮して、機能を引継ぐ計算機を適切に選択できる計算機システムを提供することである。
【解決手段】 この発明の計算機システムは、計算機11と計算機21と計算機31とで構成され、故障が発生した計算機21を検知して故障が発生した計算機21の仮想計算機14上で動作していたf2機能を引継ぐ計算機を選択してf2機能を引継がせる構成制御12を備える計算機システムにおいて、仮想計算機14上で同時に実行可能な機能の組合せである第1のパラメータを設定するAテーブルを備え、構成制御12は、Aテーブルを参照して、故障が発生した計算機21で動作していたf2機能が第1のパラメータにある計算機11を選択するものである。
(もっと読む)
フェイルオーバシステム、記憶処理装置及びフェイルオーバ制御方法
【課題】簡易にフェイルオーバを構成することが可能なフェイルオーバシステム、記憶処理装置及びフェイルオーバ制御方法を提供する。
【解決手段】メイン機であるNAS10は、NAS20からの応答がない場合に、新規のバックアップ機となるNASを検索するための検索パケットを送信する。検索パケットを受信したNAS30乃至NAS50は、フェイルオーバ機能のバージョン番号、及び、記憶容量情報を含んだ装置情報パケットをNAS10へ送信する。NAS10は、各装置情報パケットに含まれるフェイルオーバ機能のバージョン番号、及び、記憶容量情報に基づいて、新規のバックアップ機となるNASを選択する。
(もっと読む)
業務引き継ぎ方法、計算機システム、及び管理サーバ
【課題】外部のディスク装置を利用してブートするサーバにおいて障害が発生した場合に、不均質なハードウェア構成を持つシステムの中から業務の引き継ぎ先となるサーバの選択作業やパーティション構成作業を不要とすることで、システムの初期構築の工数と導入コストの削減を可能とするフェールオーバ方法を実現する。
【解決手段】業務を稼動中である現用サーバ102の障害発生時に、計算機システム内の業務を稼動中でないサーバ102へと業務処理を引き継ぐ際に、現用サーバ102の障害発生を検知し、計算機システム内において現用サーバ102と同じハードウェア構成を持つ業務を稼動中でないサーバ102を検索し、検索の結果発見したサーバ102から外部ディスク装置103へのアクセスを可能として、そのサーバ102を外部ディスク装置103からブートすることで業務の引き継ぎを行う。
(もっと読む)
フェイルオーバ方法、およびその計算機システム。
【課題】障害回復時の可用性を高める。
【解決手段】複数のサーバがネットワーク上の外部ディスク装置に接続され、サーバ上に1つ以上の論理区画を構築する論理区画機構を有し、論理区画は外部ディスク装置のブートディスクからオペレーティングシステムをブートする計算機システムにおいて、業務を稼動中であるサーバの障害発生時に計算機システム内の業務を別のサーバへと引き継ぐ際に、障害の影響を受ける論理区画のみフェイルオーバを行う。サーバの障害発生の検知921、障害の部位の特定、障害部位から障害の影響をうける論理区画の特定924、前記論理区画の停止912、計算機システム内から引き継ぎ先となる予備サーバの検索926、予備サーバに前記障害の影響を受ける論理区画の構築952、前記構築した論理区画に前記障害の影響を受ける論理区画のブートディスクの引き継ぎ941、前記構築した論理区画の起動953を行う。
(もっと読む)
台数制御装置、台数制御方法及び台数制御プログラム
【課題】サーバのリソース使用量に応じて稼動するサーバの台数が変更される分散処理システムにおいて、待機サーバによるリソース使用量を抑えつつ、必要なタイミングで稼動サーバの台数を増やし、負荷上昇への対応を可能とすることを目的とする。
【解決手段】待機サーバを稼動サーバへ切り替える指標となる閾値にリソース使用量が達するまでの予測時間を計算して、計算した予測時間内に生成可能な待機サーバの待機方式を選択し、その待機方式の待機サーバを生成する。
(もっと読む)
仮想マシンシステムおよび仮想マシン配置方法
【課題】災害に応じて、仮想マシンシステム内の仮想マシンを他の仮想マシンシステムに再配置する。
【解決手段】仮想マシン10,11が構築された仮想マシンサーバ12を含み、ネットワーク2を介して他の仮想マシンシステム3,4に接続されている仮想マシンシステムであって、災害情報から所定の災害を検出し、検出した災害の情報を通知する災害検出部13と、災害の種類に応じた対応処理が登録された処理設定情報と、仮想マシンの再配置先の候補となる仮想マシンサーバの仮想マシンシステム3,4におけるシステム情報とを格納する格納部14と、通知された災害の情報と、処理設定情報およびシステム情報とに基づいて、再配置を行う仮想マシン10と再配置先の仮想マシンサーバ31とを決定する対応決定部15と、仮想マシンサーバ12に、仮想マシン10を再配置先の仮想マシンサーバ31に再配置させるサーバマネージャ部16とを備える。
(もっと読む)
仮想計算機の移動方法、仮想計算機システム及びプログラム
【課題】仮想サーバの引き継ぎ先の物理サーバのリソースが、引き継ぎ元の物理サーバよりも少ない場合であっても、仮想サーバを引き継ぐことを可能にする。
【解決手段】複数の仮想計算機を構築する仮想化部を有する複数の物理計算機とネットワークで接続された管理計算機と、を有し、管理計算機が、複数の物理計算機のうち第1の物理計算機の計算機リソースを仮想計算機に割り当てて当該仮想計算機を稼働させ、仮想計算機に割り当てた計算機リソースの情報を仮想計算機の定義情報として保持し、仮想計算機が第1の物理計算機で実際に使用した計算機リソースを実使用量として取得し、所定条件が成立したときに、仮想計算機の移動先として複数の物理計算機のうち実使用量以上の計算機リソースを確保可能な物理計算機を第2の物理計算機として選択し、定義情報を実使用量に更新して仮想計算機を前記第2の物理計算機に移動させる。
(もっと読む)
分散処理システム及び故障復帰方法
【課題】演算プロセッサとは別に演算処理部の故障を検出するための専用のハードウェアを設けなくても、演算処理部の故障の検出及び故障からの復帰を行う。
【解決手段】演算処理部11は、自身が実行する処理要素の処理が終了し、次に実行される処理要素に処理を依頼した後、当該次に実行される処理要素からの応答がなかった場合、当該次に実行される処理要素を実行する演算処理部11が故障したと判定する。管理部12は、自己と同一の演算ユニット10に含まれる演算処理部11によりある処理要素を実行する演算処理部11が故障したと判定された場合、当該処理要素を代わりに実行する演算処理部11を決定し、決定した演算処理部11に当該処理要素を実行させるために全ての演算ユニット10に代替要求信号を送信する。
(もっと読む)
サーバ切替方法、プログラムおよび管理サーバ
【課題】サーバ装置の障害発生時において、異なるハードウェア構成を有するサーバ装置間においても、業務の引き継ぎを可能とする。
【解決手段】現用サーバ、待機用サーバなどの、ストレージ装置30に接続しているサーバ装置20を含む計算機システム1において、現用サーバから、待機用サーバにストレージ装置30への接続を切り替えることで、業務を引き継がせる管理サーバ10において、サーバ装置20における機器情報と、切替方法とが対応付けられている切替戦略テーブル123を参照し、現用サーバおよび待機用サーバの機器および優先度を考慮して切替戦略を選択する。
(もっと読む)
故障処理装置
【課題】故障発生時に、適正な故障処理動作を行う。
【解決手段】CPU110は、3個の第1VCPU12、22、32上にそれぞれ配設され、3個の第1VCPU12、22、32上でそれぞれ動作する第1ソフトウェア11、21、31が故障を検出した場合の処理を規定する第1故障レベル情報を予め格納する3個の第1レジスタ13、23、33と、第1ソフトウェア11、21、31が故障を検出した場合に、故障を検出した第1ソフトウェアに対応する第1故障レベル情報を第1レジスタ13、23、33から読み出し、故障処理動作を規定する故障レベルとして設定する故障レベル設定部451と、設定された故障レベルに対応する故障処理動作を実行する処理実行部453と、を備える。
(もっと読む)
キャッシュクラスタを構成可能モードで用いるキャッシュデータ処理
キャッシュデータを処理することは、複数のキャッシュサービス・ノードを含むキャッシュクラスタ内のマスタ・キャッシュサービス・ノードに、キャッシュ処理要求を送信することを含んでいる。そのキャッシュクラスタは、複数のキャッシュサービス・ノードのすべてが稼働状態にあって、マスタ・キャッシュサービス・ノードが複数のキャッシュサービス・ノードの中から選択されるアクティブ・クラスタ構成モードか、あるいは、複数のキャッシュサービス・ノードの中で唯一稼働状態にあるノードがマスタ・キャッシュサービス・ノードであるスタンバイ・クラスタ構成モードに構成可能である。キャッシュデータの処理は、さらに、マスタ・キャッシュサービス・ノードからの応答を待つこと、マスタ・キャッシュサービス・ノードに障害が発生したか否か判断すること、および、マスタ・キャッシュサービス・ノードに障害が発生した場合にバックアップ・キャッシュサービス・ノードを選択することを含んでいる。 (もっと読む)
コンピュータシステム、障害処理方法、及びプログラム
【課題】 ボード上のコア領域を含むメモリユニットが故障した場合でも、コンピュータシステムを停止せずにFRUを交換する。
【解決手段】 コンピュータシステムにおいて、ボードで障害が発生したときに、障害情報と故障辞書に基づいて、故障被擬ユニットを判定する故障被擬ユニット判定処理部と、障害が発生したメモリユニットと同じボード上のメモリユニットに、コア領域が設定されているか否かを判定するコア領域判定処理部と、同じボード上のメモリユニットに、コア領域が設定されているときに、ボード以外のボード内のメモリユニットに、コア領域を設定するコア領域設定処理部と、を備える。
(もっと読む)
情報処理装置の障害復旧システム及び情報処理装置の障害復旧方法
【課題】サーバのハードウェア構成を若干変更することにより、障害発生時にはサーバ間の優先度に応じた迅速な障害復旧を可能にするコストの安い情報処理装置の障害復旧システムを提供すること。
【解決手段】サーバ100,110,120は、ホットスワップ可能なローカルディスクを2個ずつ実装している。また、代替サーバを用意する。サーバ100,110,120のいずれかにサーバ障害が発生した場合には、障害発生サーバの同期データ(バックアップデータ)が入っているローカルディスクを、ホットスワップにて取り外し、代替サーバに実装して起動する。
(もっと読む)
情報処理システム、ディザスタリカバリ方法及びディザスタリカバリプログラム
【課題】障害が発生した場合に、ジョブの引継を適切に行うことができる情報処理システム、ディザスタリカバリ方法及びディザスタリカバリプログラムを提供すること。
【解決手段】本発明にかかる情報処理システムは、ジョブ実行システム1と、障害管理部2を備えている。障害管理部2は、自拠点及び他拠点の障害を検出し、障害拠点情報を記憶手段に格納する障害検出復旧手段21と、自拠点システムがマスタの場合には、障害拠点情報により特定される障害拠点のジョブが引き継ぎ可能かを他の拠点システムに対して問い合わせ、自拠点システムがマスタでない場合には、ジョブの引継が可能かの問い合せに対して障害拠点のジョブの実行環境定義書に基づいて当該ジョブの引継の可否について決定してマスタである拠点システムに対して回答するジョブ実行引継手段23とを備えている。
(もっと読む)
1 - 20 / 64
[ Back to top ]