
Fターム[5B034BB11]の内容
ハードウェアの冗長性 (4,130) | 能動的冗長 (1,216) | 再構成 (300)
Fターム[5B034BB11]の下位に属するFターム
Fターム[5B034BB11]に分類される特許
1 - 20 / 246
広域分散構成変更システム
マルチプロセッサシステムの障害回復方法
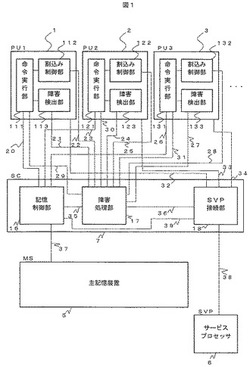
【課題】本発明の課題はマルチプロセッサシステムでAPがない状態であっても、障害の発生したIPが実行する処理の優先度が高いならば、優先度の低い処理を実行するIPに対して動的IP交代を実施し、優先度の高い処理を保証することにある。
【解決手段】複数の処理装置と、前記複数の処理装置に共有される主記憶装置とを有するマルチプロセッサシステムの障害回復方法において、構成内に交代用のプロセッサが存在しない場合であっても、各プロセッサが実行する処理の優先度を保持することによって、より優先度の高い処理を実行するプロセッサをシステムに残す処理を特徴とするマルチプロセッサシステムの障害回復方法。
(もっと読む)
フォールトトレラントシステム

【課題】可用性と信頼性を向上させるために必要なテスト機能を備えるフォールトトレラントシステムを提供する。
【解決手段】保守用計算機102は、指定した演算用計算機103に対し、演算用計算機103に組み込まれている擬似故障処理部302を実行させる命令を、プログラム起動制御部204から送信する。入出力制御部203は、同期検出部205が演算用計算機103の同期が外れたことを確認したことを受けて、演算用計算機103の再組み込み処理部303に再組み込みを指示する。その後、入出力制御部203は、同期検出部205が演算用計算機103の再組み込み処理が失敗したことを確認したら、ログ記録部305を通じてログファイル307からエラーログを収集する。以上の一連の動作は、テスト機能制御テーブル206に記載された内容に従って、各演算用計算機103に対して繰り返し実行される。このため、効率よくエラーログを収集できる。
(もっと読む)
障害監視システムおよび障害監視ソフトウェアによる監視方法
【課題】ネットワークに連接した複数の情報処理装置を利用してソフトウェアサービスを提供するシステムにおいて、ソフトウェアサービスの提供を継続するための情報処理装置とソフトウェアの無応答を含む障害監視をハートビート方式等により一括して行なった場合、短周期監視時のシステム内の監視負荷増大、または、長周期監視時のサービス停止時間増大の課題がある。
【解決手段】短周期ハートビート監視の必要な無応答を含むソフトウェアの障害監視範囲を個々の情報処理装置内に限定して障害発生時の障害情報を情報処理装置間で情報共有装置を使用して共有し、かつ、情報共有装置の障害情報を使用して障害監視装置が障害対処する。情報共有装置により、任意の情報処理装置が障害監視装置の障害を検出した場合に自律的に障害監視装置となって、システム障害への継続対処を図る。
(もっと読む)
情報処理装置、プロセス監視方法、プロセス監視プログラム、記録媒体
【課題】アプリケーションに起因してプロセスが異常終了する可能性を検出する。
【解決手段】収集部73は、複数の業務アプリケーション4に基づき処理を実行する複数の業務プロセス3のそれぞれについて、業務プロセス3の特性を表す特性情報を収集する。比較部74は、複数のプロセスの各々から収集した特性情報を比較する。判断部75は、複数の業務プロセス3のうちのある業務プロセス3に関する特性情報が、複数の業務プロセス3のうち、ある業務プロセス3を除いた業務プロセス3のいずれの特性情報とも特性が異なる場合に、ある業務プロセス3について異常が発生したと判断する。
(もっと読む)
縮退処理装置、縮退処理システム、縮退処理装置の縮退処理方法および縮退処理プログラム
【課題】障害が発生した場合、複数の業務処理で構成される業務フローを少なくとも一部の業務処理が異なる縮退フローに変更できるようにすることを目的とする。
【解決手段】障害ルール対応表291は、複数の業務処理で構成される特定の業務フローの業務処理毎に、当該業務処理で障害が発生した場合に特定の業務フローの代わりに実行する業務フローを縮退フローとして特定する縮退フロー情報を含む。特定の業務フローのいずれかの業務処理で障害が発生した場合、障害ルール解釈部230は、障害が発生した業務処理に対応する縮退フロー情報を障害ルール対応表291から取得する。サービス制御部250は、障害ルール解釈部230によって取得された縮退フロー情報によって特定される縮退フローを特定の業務フローの代わりに実行する。
(もっと読む)
情報処理システム運用管理装置、運用管理方法及び運用管理プログラム
【課題】
並列分散処理システム、例えばMapReduce方式のように、複数の情報処理装置から取得した監視データを基に障害検知を行おうとしても、どの装置の間に相関関係が生じるかが事前に決定できない。また、稼働中に相関関係が生じる組み合わせが変化するようなシステムにおいて、障害の検知を行う。
【解決手段】
複数の情報処理装置が協調して動作する情報処理システムを運用管理する情報処理システム運用管理装置であって、前記情報処理装置を、その特性によって分類し、2つの前記情報処理装置の間の典型的な関係を各々の前記特性の組をキーとして記憶し、記憶された前記典型的な関係を用いて前記情報処理装置の状態を判定する。
(もっと読む)
冗長化システム
【課題】N+m冗長化構成において、複数台の現用系ルータに障害が発生したときにでも、通信性能の低下を抑制すること。
【解決手段】N+m冗長化する冗長化システムであって、ルータ1のイベント検出部13が、所定のVRRPグループに属する現用系のルータ1に障害が発生したときに、新たな現用系として切り替える旨の切り替えイベントを、設定記憶部12のステートを監視することで検出し、イベント対処部14が、イベント検出部13により検出された切り替えイベントの対象となる所定のVRRPグループを特定し、その特定した所定のVRRPグループ以外のVRRPグループについて、自身の現用系の選出頻度を下げる。
(もっと読む)
スロットインターフェースアクセス装置、その方法及びそのプログラム並びに主装置の冗長構成及び代替方法
【課題】単一の主装置が、ネットワークにつながる全ての主装置のハードウェアのリソース等の情報を一元管理する。
【解決手段】入出力制御モジュールとその下位のスロットインターフェースとの間に、スロット管理モジュール、スロット制御モジュール及び物理スロット/管理スロット対照表を備え、入出力制御モジュールは、仮想スロット識別情報を用いてスロットインターフェースにアクセスし、スロット管理モジュールが、物理スロット/管理スロット対照表を参照して、仮想スロット識別情報を物理スロット識別情報に変換し、変換により得られた物理スロット識別情報に対応するスロット制御モジュールにアクセスすることにより、入出力制御モジュールによるスロットインターフェースへの物理的なアクセスが実現される。
(もっと読む)
マスター/スレーブシステム、制御装置、マスター/スレーブ切替方法、および、マスター/スレーブ切替プログラム
【課題】マスター/スレーブ構成のシステムにおいて、マスターとスレーブの切替を適切に行い、システムの信頼性を高める。
【解決手段】スレーブ状態の制御装置10Bは、他の全ての制御装置から各制御装置自身に関する情報を取得する情報取得手段と、取得した情報に基づいて自制御装置が新たなマスター候補であるか否かを判別し、新たなマスター候補である場合にマスター状態の制御装置10Aにマスター交代要求を送信する判別手段とを備え、マスター状態の制御装置10Aは、スレーブ状態の複数の制御装置10Bからマスター交代要求を受信すると、マスター交代要求を送信したいずれかの制御装置を、新たなマスターとして決定するマスター決定手段を備える。
(もっと読む)
負荷分散サーバシステム
【課題】サーバシステムの冗長化と負荷分散を同時に行い、サーバ資源の有効利用とシステムの信頼性を高める。
【解決手段】複数のサーバがネットワークを介して接続されたクライアント装置からの要求に対し複数のサービスを上記クライアント装置に対し提供するサーバシステムにおいて、前記複数のサーバは前記クライアント装置に対し仮想サーバとして動作し、前記複数のサーバは、前記複数のサービスをサービス機能毎に分担して受け持つとともに、相互に死活監視メッセージを送受信し、少なくとも1つのサーバの前記死活監視メッセージを受信しなくなったとき、予め決められたサービス機能の優先度に基づいて、他の少なくとも1つのサーバに対し、前記死活監視メッセージを受信しなくなったサーバのサービス機能を割り当てて、対応する仮想サーバを起動して当該サービス機能のサービスを提供する。
(もっと読む)
情報処理システム、通信制御装置、及びプログラム
【課題】情報処理システムにおいてサーバ装置の利用率を向上させる。
【解決手段】通信制御装置105は、情報処理システムにおいて、通信回線を介して複数のサーバ装置に接続される。通信制御装置105は、実行状況情報141を記憶している記憶部211と、タスクの実行を要求する要求情報をクライアント装置から受信してサーバ装置へ転送する要求転送部231とを備える。実行状況情報141は、通信回線を介して接続された各サーバ装置が複数のサービスのそれぞれを実行しているか否かを示す。要求転送部231は、要求情報を受信した場合に、実行状況情報141を参照し、実行状況情報141において複数のサーバ装置のうち、受信した要求情報に係るタスクに対応するサービスを実行していると示されるサーバ装置へ、受信した要求情報を転送する。
(もっと読む)
車載電子制御装置
【課題】マルチコア構成の車載ECUにおいて優先度の高い制御の中断期間を短縮
【解決手段】車載ECU内のCPUは、コア21〜23を備える。コア21は優先度が高い処理(以下、重要処理という)を実行する。コア22(23)は、サブスケジューラ(以下SSという)31(41),32(42)と、SS31(41),32(42)を管理するメインスケジューラ(以下MSという)35(45)を動作させる。MS35(45)は、コア21で異常がない場合に、リソースをSS31(41)に割当てSS32(42)に割当てないようにして、優先度が低い処理(以下、通常処理という)をSS31(41)に実行させるとともにSS32(42)を停止させ、コア21で異常がある場合に、リソースをSS31(41)及びSS32(42)に割当てることで、SS31(41)に通常処理を実行させSS32(42)に重要処理を実行させる。
(もっと読む)
冗長構成をとるコントローラ
【課題】冗長系の切り替えを安全に実施し、制御の引き継ぎが完了するまでの時間を短縮する。
【解決手段】コントローラ1は、ホスト機能部30を有する主系制御モジュール10と、ファンクション機能部71を有する入出力モジュール70−n(nは自然数)と、ファンクション機能部60−nおよびホスト機能部30A−nを有する待機系制御モジュール10A−nがシステムバス90で接続されている。主系制御モジュール10は、入出力モジュール70−nを制御すると共に、ファンクション機能部71の接続を構成する構成情報31を、ファンクション機能部60−nへ所定のタイミングで繰り返し通知し、待機系制御モジュール10A−nは、ファンクション機能部60−nが受信した構成情報31を保持し、構成情報31の通知が途絶したとき、構成情報31−nに基づいて入出力モジュール70−nを引き継いて制御する。
(もっと読む)
信号振分複製先決定システム、信号振分複製先決定方法およびプログラム
【課題】クラスタのノード数が増減した場合において、呼情報を複製する処理時間を低減し、クラスタ全体として、スケーラブルに呼処理性能を向上させる。
【解決手段】呼処理を行う複数のノード20と、呼制御信号を一括して受信し、各ノード20に振り分け、セッション継続に必要な呼情報の複製先を決定する信号振分複製先決定装置10とを備える信号振分複製先決定システム1において、信号振分複製先決定装置10は、各ノード20のIDを、閉じたID空間上に配置し、自ノード20が配置された位置から所定回りに最初に配置された他のノード20を、自ノード20が記憶する呼情報の複製先(バディ)に決定する。ノード20が故障した場合に、信号振分複製先決定装置10は、故障したノード20が処理すべき呼制御情報を受信すると、その故障したノード20の呼情報の複製を記憶するノード20(バディ)に、振分先を決定する。
(もっと読む)
クラスタシステム、同期制御方法、サーバ装置および同期制御プログラム
【課題】新たにクラスタシステムに組み込んだサーバのデータ同期が完了するまでの時間を短縮することを課題とする。
【解決手段】クラスタシステムは、現用系サーバと組み込みサーバとを有し、クライアントのデータと該データの所在を示す情報とレコードの状況を示す情報とをレコードとして記憶するDBを各サーバが有する。現用系サーバは、DBが有するレコードを第1の情報として第1の情報を示す種別の情報と共に組み込みサーバに送信するとともに、レコードの更新が発生した場合には、更新されたレコードを第2の情報として第2の情報を示す種別の情報と共に組み込みサーバに送信する。組み込みサーバは、現用系サーバから第1の情報または第2の情報を受信する。そして、組み込みサーバは、受信した種別の情報と、前記受信した情報によって特定されるDBのレコードの状況とに応じて、受信した情報に基づいたレコードをDBに生成する。
(もっと読む)
計算機システムでの部分障害処理方法
【課題】 論理分割可能な計算機では、ハードウェア障害が発生しても、障害の影響を受けないLPARは実行を継続可能な場合がある。この場合、ハードウェア保守で計算機全体を停止しなければならない時に、継続稼働しているLPARを停止してよいのか容易に判断できない。
【解決手段】 計算機で発生したハードウェア障害について、ハイパバイザが、実行継続可能なLPARに実行継続可能なハードウェア障害として障害発生を通知し、それを受けたLPARが障害対応処理を実行したことをハイパバイザに通知し、その通知状況を取得するためのインタフェイスをハイパバイザが提供する。このインタフェイスを通じて、LPARごとの実行継続可能なハードウェア障害への対応状況を登録・取得可能とし、計算機全体での対応状況を判定可能とする。
(もっと読む)
ファイルシステム、ファイルシステムの管理方法、ファイル排他制御装置
【課題】複数のホストにより共有ファイルをアクセスするファイルシステムにおいて、障害が発生したときの信頼性の向上を図る。
【解決手段】ホスト2a、2bと、ホスト2a、2bによりアクセス可能な共有ファイル3と、ホスト2a、2bが共有ファイル3を排他的にアクセスするように排他制御を行うファイル排他制御装置1a、1bとからなるファイルシステムで、ファイル排他制御装置1a、1bに、2つの排他制御ユニット10a、10bを設け、排他制御ユニット10a、10bの排他制御情報を互いにバックアップする。障害が発生し、障害部位が特定できない場合に、排他制御ユニット10a、10bをマスタ/スレーブの構成に再構築する。
(もっと読む)
アプリケーションの高可用運用方法、オンラインバージョン変更方法及び計算機システム
【課題】リークしたリソースを含む実行環境の一部を解放することで、障害の発生を抑止しつつ、実行環境の一部がまだメモリ等に残っていることによりCold Cacheによって発生する性能低下を最小限に抑える。
【解決手段】処理要求を受け付ける第1のアプリケーションApp1と第2のアプリケーションApp2を入れ替えるアプリケーションの高可用制御方法であって、第1のアプリケーションApp1を起動して、処理要求を第1のアプリケーションApp1へ転送する手順と、所定の条件を満たしたときには、第2のアプリケーションApp2を起動し、新たな処理要求を第2のアプリケーションApp2へ転送する手順と、第2のアプリケーションApp2が起動した後に、前記第1のアプリケーションApp1で前記処理要求を完了すると、当該第1のアプリケーションApp1を終了する手順と、を含む。
(もっと読む)
分析装置制御システム
【課題】分析装置を操作するための分析装置制御用システムにおいて、分析装置制御サーバに障害が発生すると、分析装置は正常に稼働していても、実行中の分析を中断し、改めて再分析を行うことが必要である。
【解決手段】分析装置制御サーバから、制御している分析に関する分析条件情報と分析データとを所定の時間間隔で、システム制御サーバに送信する。システム制御サーバが分析装置制御サーバの障害を検知すると、システム制御サーバは正常に稼働している他の分析装置制御サーバの中から新しい割当先を決定し、分析情報保存部に保存してある分析条件情報と分析データとをこの割当先の分析装置制御サーバに対して送信するとともに、その分析装置制御サーバに対して、分析装置の分析の制御を引継実行する命令を送信する。
(もっと読む)
1 - 20 / 246
[ Back to top ]