
Fターム[5B042JJ30]の内容
デバッグ、監視 (27,428) | 動作監視、異常又は誤りの検出 (3,508) | 異常又は誤りの検出方法 (1,125) | 比較によるもの (456) | 過去の値との比較 (88)
Fターム[5B042JJ30]に分類される特許
1 - 20 / 88
プログラムの新旧バージョンに対する差分比較テストシステム及びテスト方法
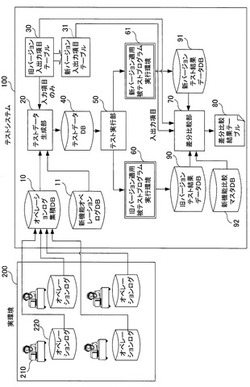
【課題】実環境でのオペレーションログからテストデータを自動的に作成し、新旧バージョンのプログラムの出力結果の差分を容易に比較する手段を提供する。
【解決手段】プログラムの旧バージョンが稼動する実環境におけるオペレーションログを記録し、新旧バージョンのプログラムの操作画面を介した入出力項目をそれぞれ定義した新旧バージョン入出力項目テーブルを用いて、オペレーションログからテストデータを生成する。生成したテストデータを、新旧バージョンのプログラムを適用したテスト環境それぞれに対して投入しテストを自動実行させ、新旧テスト環境それぞれからテスト結果を取得する。そして、そのテスト結果から新旧バージョン入出力項目テーブルを再び用いて比較項目を取り出し、旧バージョンのテスト結果と新バージョンのテスト結果の差分を抽出して差分比較結果テーブルに出力する。
(もっと読む)
コア監視装置、情報処理装置

【課題】マルチコアマイコンにおいて、異常の生じたコアをソフト的な負荷増大を抑制して判別可能なコア監視装置を提供すること。
【解決手段】複数のコアから共通の周期で通知を受け付けるコア監視装置17であって、 コアから通知を受け付けた際、各コアに固有のコア識別数値(例えば、カウンタ値×ID)をコア毎に生成するコア識別数値生成手段31と、複数のコアのコア識別数値を合計した合計値を算出する合計値算出手段32と、最後に算出された合計値を記憶する合計値記憶手段36と、合計値算出手段が算出した合計値と、合計値記憶手段に記憶された合計値との差である第一の差を算出する第一の差算出手段33と、第一の差を記憶する第一の差記憶手段37と、第一の差算出手段が算出した第一の差と第一の差記憶手段に記憶された第一の差との差である第二の差を算出する第二の差算出手段34と、を有する。
(もっと読む)
情報処理装置、情報処理システム、情報処理装置の異常兆候検出方法、及び異常兆候検出プログラム
【課題】他の情報処理装置のCPUとの間で同期ずれが発生したCPUで、異常兆候を検出する。
【解決手段】情報処理装置10は、CPU11と、入出力関連装置13と、同期制御部14と、他の情報処理装置20との間で情報を送受信する通信部17とを備える。同期制御部14は、CPU11を初期化する初期化設定部140と、CPU11と入出力関連装置13間のトランザクションを監視するトランザクション監視部141と、トランザクションの監視情報と他の情報処理装置20から受信したトランザクションの監視情報とからCPU11の同期ずれを判定する同期判定部142と、トランザクションの監視情報に基づき、異常兆候関連情報を取得する異常兆候関連情報取得部143と、同期ずれ有りのとき、異常兆候関連情報に基づき、CPU11の異常兆候の有無を判定する異常判定部144とを備える。
(もっと読む)
情報処理装置及びプログラム
【課題】制御プログラムの動作検証を行い、リソースへの不適切なアクセスを検出する情報処理装置を提供する。
【解決手段】情報処理装置は、制御プログラム実行するCPUシミュレータ301がリソースにアクセスする場合、当該リソースを特定する情報及び当該アクセス種別がデータの読み込みであるか書き込みであるかを示す情報を含むアクセス情報を出力するシミュレータ部101と、アクセス情報を受け取り、各リソースに対するアクセス種別の履歴を示す履歴パターン情報を保存する履歴情報保存部106と、履歴情報保存部106がアクセス情報を受け取ることにより、当該アクセス情報のリソースを特定する情報が示すリソースの履歴パターン情報を更新すると、当該リソースの履歴パターン情報と、検出パターン情報を比較することで、検出パターン情報が示すアクセス種別の時間順序でのリソースへのアクセスを検出する検出部108と、を備えている。
(もっと読む)
運用管理装置、運用管理方法、及び運用管理プログラム
【課題】管理対象ノードの性能情報を収集することなく、異常を検知する。
【解決手段】運用管理装置21のメッセージ取得部201は、管理対象ノードが出力したメッセージを取得してメッセージDB202に記録する。学習情報生成部204が、指定した期間内における管理対象ノード毎、メッセージの識別情報毎、単位時間毎のメッセージの数の最大値、又は最小値を算出して学習結果情報DB205に記録する。分析情報生成部206が、対象ノード毎、メッセージの識別情報毎、単位時間毎のメッセージ出力数を算出して分析結果情報DB207に記録する。分析判定部208は、学習結果情報DB205に記録された最大最小値情報と、分析結果情報DB207から読み出した分析データ情報とに基づいて、分析対象の各管理対象ノードが正常であるか否かを判定し、判定結果を分析結果情報DB207に記録し、出力部209に出力する。
(もっと読む)
プログラム監視システム
【課題】 複数プログラムが動作するシステム環境で、動作障害を検出し、復旧させる。
【解決手段】 この発明に係るプログラム監視システムは、複数のプログラムの設定情報を記憶した管理テーブルに基づいて、各プログラムの起動時に、監視先プログラムと監視元プログラムとを関係付けるプログラム管理手段と、監視先プログラムとして、正常に動作する過程で、正常動作状態を示す正常情報を一定時間以内の間隔で繰り返し更新するプログラム正常情報更新手段と、監視元プログラムとして、正常情報を監視するタイミングを定期的に指示するタイマー手段と、タイマー手段の指示で正常情報を参照し、前回参照時に保存した正常情報との比較に基づいて、監視先プログラムの動作の異常を検出する他プログラム監視手段と、動作の異常の検出を通知された場合に、監視先プログラムを強制終了させて再起動する他プログラム再起動手段とを備えた。
(もっと読む)
自律マイクロセル型の分散データ処理システム、及び情報処理装置
【課題】従来のデータセンタに対して、構築・運用・利用コストなどの面において有利なデータセンタを実現できる技術を提供する。
【解決手段】本システム100は、複数の自律マイクロセルCが近距離通信方式で接続されるネットワークにより構成される。各セルCは、制御部、近距離通信装置部、自律電源装置部、サービス処理を提供するサービス部などを有する。制御部は、情報管理部、多重化部、及び状態検出部などを有する。状態検出部は、近距離通信を含む観測手段を用いて、セル間で自セルまたは近セルの良好ではない所定の状態を検出/予見する。制御部は、所定の状態に応じて、セル間で、例えば、多重化部を用いて、当該セルのサービス処理を他のセルへ移管する処理、及び当該サービス処理のデータを他のセルへコピーする処理を実行する。これにより可用性を維持する。
(もっと読む)
異常状態検知装置及び異常状態検知方法
【課題】原因の特定方法が必ずしも明らかではない種々の異常を予知することのできる異常状態検知装置及び異常状態検知方法を提供する。
【解決手段】情報処理装置(3)から、当該装置の稼動状態を表す状態データを周期的に取得して、前記情報処理装置に異常が発生する前の状態データを記憶装置(11)に少なくとも一つ蓄積し、蓄積された状態データをグループにクラスタリングする準備処理手段と、前記情報処理装置から状態データを取得するデータ取得手段と、取得した状態データが前記グループに属するか否かを判定する判定手段と、前記判定手段が属すると判定した場合は、この判定結果を出力する出力手段とを備えたことを異常状態検知装置(1)。
(もっと読む)
ネットワーク運用管理システム、ネットワーク監視サーバ、ネットワーク監視方法およびプログラム
【課題】複数のイベントが複合的に原因となる不具合の発生原因およびその対策を特定することを可能とするネットワーク運用管理システム等を提供する。
【解決手段】ネットワーク監視サーバ10は、各監視対象装置からメッセージを受信するアラート受信部113と、メッセージを事象ごとにグループ化するグループ化部116と、グループ化されたメッセージをパターン定義と照合するパターン照合部118と、パターン定義に該当する場合に予め記憶された対策情報を出力する対策情報出力部119とを備えると共に、パターン定義に含まれない内容のイベントを一次フィルタとして抽出する一次フィルタ抽出部115と、一次フィルタとして抽出されたイベントの発生を該当する監視対象装置に監視させる監視要求部117と、グループ化部による処理より先にメッセージに一次フィルタを適用する一次フィルタ部112とを備える。
(もっと読む)
移行テスト支援システム、移行テスト支援プログラム、移行テスト支援方法
【課題】システム移行テストにおいて、現行システムと新システムとの間の差分を解析するにあたり、アプリケーションが改修されている部分を解析対象から除外し、新旧システム間の相違原因を分析し易くすることを目的とする。
【解決手段】本発明に係る移行テスト支援システムは、アプリケーションが改修されている箇所を記述した改修タグをアプリケーションの実行結果トレースから読み込み、その部分を現行システムと新システムの間の比較対象から除外する。
(もっと読む)
ログ収集システム、装置、方法及びプログラム
【課題】端末装置の稼働状況を遠隔でリアルタイムに監視する際に、端末装置のログ情報の収集管理及び設定の手間を軽減する。
【解決手段】端末機器とサーバ装置とを備え、端末機器は、ログ情報を収集し蓄積するログ収集蓄積手段と、蓄積したログ情報を解析し、異常状態を検出する異常検出手段と、異常状態を検出すると、サーバ装置に異常状態を通知する異常通知手段とを含み、サーバ装置は、端末機器に蓄積されたログ情報を収集するログ収集手段と、通知された異常状態を解析する異常解析手段と、異常状態の内容に応じて、異常検出手段に対して異常状態の検出方法の設定を指示する異常検出指示手段と、ログ収集蓄積手段に対して収集し蓄積するログ情報の粒度及び内容と収集し蓄積する頻度との設定を指示する端末ログ収集蓄積指示手段と、ログ収集手段に対して端末機器から収集するログ情報の内容と収集頻度との設定を指示するログ収集指示手段とを含む。
(もっと読む)
障害予測サーバ、障害予測システム、障害予測方法及び障害予測プログラム
【課題】簡単に適切な障害予測を行うことを目的としている。
【解決手段】稼働情報に含まれる情報の項目が設定された項目情報と、稼働情報が障害の予兆を示すか否かを判断するために用いる閾値とが格納された記憶手段と、稼働情報データベースに格納された最も新しい稼働情報を取得する最新稼働情報取得手段と、項目情報に基づき、最新稼働情報と項目情報に設定された項目の値が等しい稼働情報を稼働情報データベースから抽出する情報抽出手段と、最新稼働情報における所定項目の値と抽出された稼働情報における所定項目の値との差分と閾値とに基づき、障害予測に関する通知情報を作成する通知情報作成手段と、を有する。
(もっと読む)
異常検知方法およびそれを用いた情報処理システム
【課題】予想しないソフトウェアの異常動作に対しても、ソフトウェアの稼働中に状態遷移モデルに基づく状態遷移毎の遷移確率を利用して異常を検知し、さらにソフトウェアの異常箇所を特定する。
【解決手段】ソフトウェアの状態遷移モデル202に基づいた状態遷移確率モデルにおいて、基準となる第1の状態遷移確率モデル203と、ソフトウェアの運用中に、状態遷移確率を算出して求めた第2の状態遷移確率モデル215と、あらかじめ設定した状態遷移毎の遷移確率を比較することにより異常度を求め、異常判定手段216は、異常度としきい値情報204とを比較し、異常度が異常を示す値か否かを判断し、異常と判断された状態遷移に対応したソフトウェアの実行箇所を特定する。
(もっと読む)
モデル作成装置、モデル作成プログラムおよびモデル作成方法
【課題】同時に実行されたイベントの数が多い場合にもモデルを作成する。
【解決手段】モデル作成装置1は、イベントの実行が開始された時刻とイベントの実行が終了した時刻とイベントの種別とをイベント情報として取得する。また、モデル作成装置1は、取得されたイベント情報に基づいて、イベントが他のイベントを引き起こす関係を示したモデルの候補の組合せを推定する。また、モデル作成装置1は、推定されたモデルの候補のうち、既知のモデルと合致する候補を検索する。そして、モデル作成装置1は、検索したモデルの候補をモデルの候補の組合せから除外するとともに、検索結果であるモデルの候補の除外によってモデルの候補の組合せから外れる候補をモデルの候補の組合せから除外することで、モデルの候補の組合せを更新する。その後、モデル作成装置1は、更新されたモデルの候補の組合せに基づいて、新たなモデルを特定する。
(もっと読む)
異常検知装置、異常検知プログラムおよび異常検知方法
【課題】不正なプログラムにより攻撃や侵入されたアプリケーションの異常な動作を検知することを課題とする。
【解決手段】異常検知装置100は、監視対象とする特定の関数がアプリケーションプログラムにより呼び出されるまでの関数間の正常な呼び出し関係と、監視対象とする特定の関数を呼び出すイベントに応じて特定の関数がアプリケーションプログラムにより呼び出されるまでの関数間の呼び出し関係とを比較する。そして、異常検知装置100は、比較の結果、呼び出し関係が一致しない場合には、イベントに伴う関数の呼び出し動作を異常な動作として検知する。
(もっと読む)
ソフトエラー検出回路およびソフトエラー検出方法
【課題】 ソフトエラー検出の信頼性を確保しつつ、メモリオーバヘッドを抑制するとともに実行時間増を抑制し、さらにプログラムに対するハードウェアの互換性を有するソフトエラー検出回路およびソフトエラー検出方法を提供する。
【解決手段】 プログラム実行中のプログラムカウンタ値および命令から所定のパスを検出するパス検出手段3と、パスの開始から終了までに対応する制御信号系列の圧縮値を生成するシグネチャ生成手段5と、シグネチャ生成手段により生成された圧縮値を登録するシグネチャ登録手段4と、同一パスについて生成された最新の圧縮値を先行して登録された圧縮値と比較する比較手段3とを備える。
(もっと読む)
メモリ検査システム、メモリ検査方法、メモリ検査用プログラム、記憶媒体、及び集積回路。
【課題】メモリリークや異常データ書き込みなどの、CPUが管理するメモリ領域に発生する異常状態を検知することができるメモリ検査システムを提供する。
【解決手段】メモリ領域を管理するために用いるメモリ管理情報がメモリ領域内のデータの更新を許容する旨を表す属性を含んでいるにも関わらず、メモリ領域に記憶されているデータのハッシュ値の時間変化がない場合、メモリ領域の利用に異常が発生している可能性があると判定する。
(もっと読む)
異常検知方法およびそれを用いた情報処理システム
【課題】 データマイニング手法を用いた異常判定において、異常と誤判定する確率が低い異常検知方法を提供する。
【解決手段】 運用中に、異なる稼働構成からなる複数の機器から、機器の稼働中の状態の特徴を表す稼働情報を受信し、稼働情報から統計的な手法を用いた学習を行い、学習データを更新して保存する第1の学習手段と、異なる構成の機器を識別する稼働構成と、第1の学習手段において同一の稼働構成の機器から得た稼働情報を使った学習量から、稼働構成毎のしきい値を更新して保存する第2の学習手段を備え、異常度解析手段は、受信した稼働情報と、第1の学習手段が保存した学習データから異常度を算出し、異常判定手段は、異常度と受信した稼働情報の機器の稼働構成に対応する第2の学習手段が保存したしきい値を比較し、異常度が異常を示す値か否かを判断する。
(もっと読む)
計算機の状態監視装置、計算機の監視システムおよび計算機の状態監視方法
【課題】計算機の消費電力を監視することにより計算機の状態を監視する計算機の状態監視装置を提供する。
【解決手段】監視サーバ300(計算機の状態監視装置)は、監視対象となる計算機500の消費電力を測定する消費電力測定装置100の測定データを用いて計算機500の状態を監視する。監視サーバ300は、計算機500の状態別の消費電力のパターンが格納されている電力状態データベース400と、消費電力測定装置100が測定した消費電力の測定データを取得するデータ取得部205と、取得した測定データの推移パターンが、電力状態データベース400に格納されているどの状態のパターンと類似するか否かを判定し、類似すると判定したパターンに対応する状態を、監視対象の計算機500の状態として検出する計算機状態検出部220とを有する。
(もっと読む)
コンピュータ、コンピュータの障害検知方法、及びプログラム
【課題】
コンピュータに生じた障害を、異常終了等に至る前に迅速に検知することを可能とする。
【解決手段】
コンピュータ1は、実行するプログラム132を構成する各プロセス132A、BがCPU110によって処理開始されてから処理終了するまでにわたって、プロセッサ使用時間とプロセッサ不使用時間とを順次複数回計測して取得し、所定の統計処理に従って、遷移時間802及び状態待機時間803を算出して記憶する。CPU110により前記プロセスのいずれかが処理されているときに、当該プロセスについて、前記プロセッサ使用時間及び前記プロセッサ不使用時間を計測して、逐次当該プロセスについて記憶されている遷移時間802及び状態待機時間803と比較し、当該比較結果が所定の判定基準を満たしていないと判定した場合に、当該プロセス処理中に障害が発生したと判定する。
(もっと読む)
1 - 20 / 88
[ Back to top ]