
Fターム[5B075QP02]の内容
Fターム[5B075QP02]に分類される特許
1 - 16 / 16
情報検索システム、情報収集装置、情報検索装置、情報収集方法、プログラムおよび記録媒体

【課題】 複数のデータソースに格納されたデータ群を横断的に検索すること。
【解決手段】 本発明の情報収集装置(110,140)は、複数のデータソース160A〜160Cそれぞれにアクセスし、検索対象について属性および属性値を含む検索対象データを収集する収集手段114と、データソース160それぞれに定義される属性および属性値の組を、データソース間共通の正規化属性および正規化属性値の組へ対応付ける属性定義テーブル120と、属性定義テーブルを参照して検索対象データを正規化し、対応する正規化属性に関連付けて、正規化属性値と正規化前の属性値とを付与する正規化手段116と、収集元データソースを識別する情報と、対応する正規化属性と、正規化属性値と、正規化前の属性値とを関連付けて、検索用データとして、データベース142に登録する手段114とを含む。
(もっと読む)
情報検索装置およびプログラム

【課題】利用者からの検索要求文に基づいて適切な検索結果を得ることを可能とする。
【解決手段】入力処理部31は、検索要求文を入力する。構文解析部32は、検索要求文の構文解析結果を検索要求文解析結果格納部22に格納する。一次検索部33は、検索要求文に含まれる自立語を含む検索対象文を検索する。部分検索要求生成部34は、言い換えパタン格納部24を参照して検索要求文の部分検索要求文を生成する。言い換え検索部35は、言い換えパタン格納部24を参照して検索された検索対象文の言い換え文を生成する。言い換え検索部35は、部分検索要求文および検索対象文の言い換え文が類似するかを判定する。検索結果決定部36は、部分検索要求文および検索対象文の言い換え文が類似すると判定された場合、一次検索部33によって検索された検索対象文を検索要求文に対する検索結果として決定する。
(もっと読む)
言語間検索結果をハイライト化する注釈コールアウトの点滅
【課題】本発明は、電子文書、ウェブサイトまたはインターネットから情報を言語間検索するシステム及び方法を提供する。
【解決手段】本発明は、電子文書、ウェブサイトまたはインターネットから情報を言語間検索するシステム及び方法を提供する。本システムはまず、ユーザにより入力された入力言語による主エントリを地理的言語標準化し、標準化されたエントリをオブジェクト言語(またはターゲット言語と呼ばれる)による検索クエリに翻訳及び最適化する。この最適化した検索クエリを利用して、本システムは、検索を実行し、ユーザによる検索結果のナビゲートを支援するため、注釈コールアウトまたはバブルにより各一致フレーズまたはオブジェクトをハイライト化する。
(もっと読む)
語彙誤り検出装置及び語彙誤り検出方法
【課題】製品の仕様を行列形式で表す仕様データにおいて用いられている語彙と、標準辞書で定義された語彙との相違を容易に検出可能な検出技術を提供する。
【解決手段】表データ解析部22は、文書入力部21が入力を受け付けた技術文書から仕様データを抽出する。アトリビュート推定部24は、分類入力部23に入力された分類識別子によって分類が特定された辞書データと表データ解析部22が抽出した仕様データとを用いて、仕様データにおける各列がどのアトリビュートに対応するか否かを推定する。類似プロパティ検索部25は、仕様データにおける列に対して推定されたアトリビュートを用いて、類似プロパティを検索する。語彙照合部27は、仕様データにおける行に対する類似プロパティと当該行とを照合して、語彙の相違を検出する。照合結果出力部28は、検出された語彙の相違を照合結果として出力する。
(もっと読む)
同義性判定装置、その方法、プログラム及び記録媒体
【課題】定型的な文字列の追加、または読みを保存しての表記変換、あるいは省略化等を伴う文字列表現の同義性を精度高く判定すること。
【解決手段】同義語侯補ペア生成部1により、入力されたテキストを解析処理し、その解析結果に基づいて前記テキストから同義語侯補表現を抽出するとともに対応する解析結果を付与し、逆変換ルール3並びに音節正規化ルール4を用いて前記同義語侯補表現の表記及び読みの正規化を行った後、同義語侯補表現同士を組み合わせて一対の同義語侯補表現よりなる同義語侯補ペアを生成し、同義性判定部2により、音節類似度テーブル5及び省略判定モデル6を用いて前記同義語侯補ペア中の同義語侯補表現同士が同義か否かを判定し、同義であれば当該同義語侯補ペアを同義語ペアとして出力する。
(もっと読む)
データ処理システム、データ処理方法およびデータ処理プログラム
【課題】特許文献の数が膨大である場合でも、企業の事業場ごとに重要な特許をユーザが容易に把握することができるデータ処理システムを提供する。
【解決手段】このデータ処理システムは、複数の特許文献を出力する際に、指定された事業場に対応する特許文献や、当該事業場の事業に関する設計書やカタログなどの事業場文書を取得する。システムは、取得した特許文献から特定の特許文献用語を検索し、検索した特許文献用語を事業場文書で用いられる文書用語に変換する。システムは、取得した事業場文書から文書用語を検索し、その検索結果によって特許文献の重要度を計算する。そして、その重要度の高い順に上から特許文献を配列したリストを作成し、ユーザの端末に出力させる。
(もっと読む)
オブジェクト間の競合指標計算方法およびシステム
【課題】2オブジェクト(製品/企業等)間の競合指標を得るための方法およびシステムを提供する。
【解決手段】オブジェクト間の競合指標を計算するための方法とシステムが提供される。この方法は、複数の属性から成る第1および第2のプロファイルを各々有する第1のオブジェクトと第2のオブジェクトとを取得するステップと、オントロジ情報を参照して第1および第2のプロファイルを正規化するステップと、正規化された第1および第2のプロファイルに基づいて、第1および第2のオブジェクト間の競合指標を計算するステップとを備える。
(もっと読む)
同義疾患名選定装置
【課題】 新規な疾患概念のようなコード化が行なわれていない疾患名表記で、かつ、表層文字列が全く異なる疾患名表記であっても、同義の疾患を表現する異表記の疾患名を選定可能な技術を提案する。
【解決手段】 文書格納手段1は、患者の疾患名とその診断に係る日時とを含む医療文書を記憶しており、疾患名出現分布計算手段4が、文書格納手段1に記憶された複数の医療文書に基づいて各疾患名の所定期間別の出現頻度を取得し、同義疾患名判定手段5が、一の疾患名に係る出現頻度の時期的変化の傾向と他の疾患名に係る出現頻度の時期的変化の傾向との類似性を判定し、同義疾患名出力手段6が、出現頻度の時期的変化の傾向が類似すると判定された疾患名同士を同義として出力する。
(もっと読む)
構造化文書管理システム
【課題】要素毎に、その要素に適した種別の索引を構築することにより、良好な更新検索性能を維持しながら検索の厳密性を維持することができるようにする。
【解決手段】データ検索部16内の検索式処理部は、外部から与えられる検索式を解析して検索条件を抽出し、その検索条件に合致する検索結果の候補の集合を取得する。索引管理部15内の値抽出部は、構造化文書DB21に格納された構造化文書に含まれる各要素毎に、当該要素に対して適用された検索条件の履歴を取得する。索引管理部15内の索引種別決定部は、索引を付与すべき、構造化文書に含まれる各要素毎に、当該要素に対して適用された検索条件の履歴において最も多い検索種別に基づいて索引種別を決定する。索引管理部15内の索引構築部は、索引種別決定部によって決定された索引種別の索引を構築して、Nグラム索引DB22、単語索引DB23またはB木索引DB24に格納する。
(もっと読む)
データマップ作成サーバ、データマップ作成方法、およびデータマップ作成プログラム
【課題】文書集合から抽出される特徴的単語の関係を定式化し、そのシソーラスを明確に可視化する。
【解決手段】検索キーワードに基づき抽出された複数の文書データに含まれるワードデータの頻度に基づき、頻度の高いワードデータを抽出し、そのワードデータを含む文書集合の関係に基づき、ワードデータの直上或いは直下の関係を決定し、そのワードデータ間に直上或いは直下の関係が成立した場合、ワードデータを表示し、そのワードデータ表示51間が直上或いは直下である場合にそのワードデータ表示51の間を連結線52により連結して表示する。
(もっと読む)
文書管理システム及び文書管理方法
【課題】
インデクスの入力を自由形式にした場合、入力する人により記述がゆれてしまい、検索で漏れが起きる場合がある。
【解決手段】
入力された文書に対して索引となる文字列を、切り出し規則データにもとづき検索種別と共に切り出す切り出し処理部と、文字列を正式の表現に変換する個々の規則を持ち、文字列をそれぞれの規則に従い変換する複数の整形処理部と、該切り出し処理部が検索種別とともに切り出した文字列を、対応した整形規則データに従い、対応する該整形処理部を呼び出すことで、正式の表現に置き換える指示を行い、結果を整形文書ととして出力する整形処理制御部と、を持つ。
【効果】
別名や略称で記述されたインデクスを適宜正式名に置き換えることができ、漏れのない検索や解析を行うことが可能となる。
(もっと読む)
同義語辞書生成システム、同義語辞書生成方法および同義語辞書生成プログラム
【課題】同義語抽出ルールを人手で用意することなく、データベースからの同義語の自動生成を可能にする。
【解決手段】共通パターンルール化手段2は、同義語格納部1から供給された複数の同義語グループに共通して現れる部分文字列対を同義語ルールとして抽出する。そして抽出したルールをデータベース3内の単語に適用することにより同義語を自動生する。生成した同義語が同義語格納部1に格納されていなければ、追加格納する。これにより、同義語辞書の登録語彙数を自動的に増やしていくことができる。
(もっと読む)
異表記正規化方法、文書検索方法、文書検索装置、プログラム及び記録媒体
【課題】構成要素の違いによる異体字関係を利用し、語(表記)の入力語に対して、最も適切な異表記正規化処理を施し、文書検索において、検索漏れの発生を防止できる異表記正規化を実現すること。
【解決手段】入力テキストを受け付ける入力処理ステップと、前記入力テキストを1文字単位に抽出するステップと、異表記正規化規則に基づいて、抽出した原表記に異表記正規化する異表記正規化ステップと、異表記正規化規則が複数存在する場合、規化規則選択部において、前記のデータを1つもしくは複数を選択して使用することができる異表記正規化処理方法であって、前記異表記正規化規則が文字を構成する要素による異表記正規化規則を有することを特徴とする。
(もっと読む)
データベース利用システム及びデータベース利用プログラム
【課題】 複数のデータベース間で機械的に同期を取ることなく、利用者に対して最も信頼性の高いデータの組合せを提示することを可能とする技術の実現。
【解決手段】 少なくとも一部に重複するデータを備えた複数のデータベースα、β、γと、各データベース内に設定された特定のデータ項目に関するそれぞれの信頼度ポイントをレコード毎に登録しておく信頼度判定DB30と、検索条件が入力された場合に信頼度判定DB30を参照し、必要なレコードのデータ項目に関し信頼度ポイントが1位のデータベースから検索条件に合致するデータを抽出するデータ処理部24と、ユーザから抽出されたデータに対し訂正候補データを明示した訂正要求が入力された場合に、信頼度判定DB30のポイントを調整する信頼度更新部26を備えたデータベース利用システム10。
(もっと読む)
分散潜在的意味インデキシングを使った情報検索およびテキストマイニングのための、方法、および、システム
情報検索およびテキストマイニング操作のための潜在的意味インデキシング(LSI)の使用が、大規模な異種のものからなるデータ集合を、まず、データ集合を、類似の概念ドメインを持ついくつかのより小さい区分に区分化することによって処理するように適合される。その次に、問い合わせベクトルを拡張する際のみならず、どのドメインに問い合わせるか決定する際にも利用される、概念ドメイン間のリンクを顕在化させるために類似性グラフネットワークが生成される。ユーザ問い合わせまたはテキストマイニング操作に関連する情報を含む可能性が最も高い区分化されたデータ集合に対してLSIが実行される。このようにして、LSIが、これまで拡張可能性の問題を提示したデータ集合に適用される。さらに、用語×文書行列の特異値分解の計算が、様々な分散コンピュータにおいて達成され、検索およびテキストマイニングシステムの頑強性が向上すると同時に、サーチ時間が短縮される。 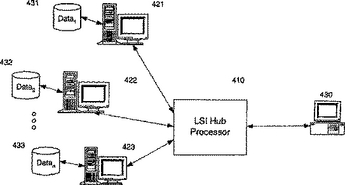 (もっと読む)
(もっと読む)
複数のクエリ言語を用いて情報を検索するシステム、方法およびソフトウェア
例示的な実施形態は、クエリ言語の記述を受信することと、受信した該クエリ言語の記述に基づいて言語変換機を自動的に構成することとを包含する。該言語変換機、または言語翻訳機は、クエリ言語の変化に対してシステムを適合させるように用いられ得る。クエリ言語の記述を受信することと、該受信した該クエリ言語の記述に基づいて言語変換機を自動的に構成することとを包含する、方法。クエリ言語の記述を受信する手段と、受信した言語変換機の記述に基づいて該言語変換機を自動的に構成する手段とを備えている、システム。  (もっと読む)
(もっと読む)
1 - 16 / 16
[ Back to top ]