
Fターム[5B091AA05]の内容
Fターム[5B091AA05]に分類される特許
1 - 20 / 89
並替モデル生成装置、語順並替装置、方法及びプログラム
電子ペン・システム、コンピュータ装置、端末及びプログラム
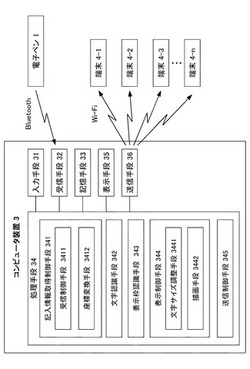
【課題】電子ペンで記入されたストロークにより表わされる第1言語の文字列の適切な配置状態を維持したまま、翻訳した第2言語の文字列を表示させる。
【解決手段】コンピュータ装置3は、電子ペンから受信したストローク情報を第1言語の文字列の文字情報として認識し、認識された第1言語の文字列を表示する表示枠を、そのサイズ及び配置を認識し、認識された文字情報、並びに、認識された表示枠のサイズ及び配置を含む情報を端末4へ送信する。端末4は、コンピュータ装置3から送信されてくる情報を取得し、取得された情報のうち、文字情報により表わされる第1言語の文字列を、第2言語の文字列に翻訳し、第2言語への翻訳後の文字列を表示枠に対応する枠に、文字サイズを調整して表示させる。
(もっと読む)
翻訳装置、翻訳プログラムおよび翻訳方法

【課題】各翻訳部品を整合性のとれた自然な文に組み合わせること。
【解決手段】翻訳装置100は、翻訳対象となる文章を、複数の構造部品に分割し、各構造部品のパターンに対応する文法によって機械翻訳することで、複数の翻訳部品を作成する。そして、翻訳装置100は、翻訳部品の主要部を特定し、主要部を変数に置き換えた検索キーおよび主要部をそのままにした検索キーを作成する。翻訳装置100は、主要部を変数に置き換えた検索キーよりも、変数に置き換えていない検索キーのほうが優位になるように、検索キーに重みをつける。翻訳装置100は、各検索キーを利用して、コーパスデータ103dを検索し、ヒット数と検索キーの重みに基づいて、翻訳候補を評価する。
(もっと読む)
電子コミックのビューワ装置、電子コミックの閲覧システム、ビューワプログラム、該ビューワプログラムが記録された記録媒体ならびに電子コミックの表示方法
【課題】電子コミックにおいて、オリジナルの言語から任意の言語に変換されたセリフの文字列を過不足なく配置する吹き出しを描画する。
【解決手段】コンテンツ表示制御部25は、表示部24の画面サイズ情報(DB21に記憶されている)に従ってその文字サイズを維持したままテキスト情報が吹き出しに収まるか判断する。コンテンツ表示制御部25は、収まらないと判断した場合は、さらに、レイアウト変更可であるか否かを付帯情報に基づいて判断し、レイアウト変更可であれば、表示指定のあった画像領域に対応する吹き出しの話者を起点に、横置き用の吹き出しを描画する。
(もっと読む)
音声翻訳装置、方法、及びプログラム
【課題】円滑なコミュニケーションを実現できる。
【解決手段】音声翻訳装置は、入力部、音声認識部、感情認識部、平静文生成部、翻訳部、補足文生成部、及び音声合成部を含む。入力部は、第1言語の音声を音声信号に変換する。音声認識部は、音声信号を音声認識処理し文字列を生成する。感情識別部は、文字列がどの感情種別を含むかを識別して1以上の感情種別を含む感情識別情報を得る。平静文生成部は、感情に伴って語句が変化した非平静語句と、非平静語句に対応しかつ感情による変化を伴わない平静語句とを対応付けたモデルより、文字列に第1言語の非平静語句が含まれる場合、第1言語の非平静語句を対応する第1言語の平静語句に変換した平静文を生成する。翻訳部は、平静文を第2言語に翻訳した訳文を生成する。補足文生成部は、感情識別情報の感情種別を第2言語で説明する補足文を生成する。音声合成部は、訳文と補足文とを音声信号に変換する。
(もっと読む)
文校正プログラム及び文校正装置
【課題】修飾先の候補を2以上有する形態素を含む文について、当該形態素の修飾先の候補を1つに特定するように当該文を校正する文校正プログラム及び文校正装置を提供する。
【解決手段】文校正装置1は、対象とする文に含まれる形態素を解析する形態素解析手段101と、形態素のうち修飾先の候補を2以上有する形態素を検出する曖昧性検出手段102と、文に対する、連体修飾を受けない少なくとも1つの連用修飾文節の挿入により、曖昧性検出手段102により検出された形態素である修飾先不特定形態素の修飾先の候補が1つとなるように文を校正する文校正手段103とを有する。
(もっと読む)
機械翻訳装置及び機械翻訳プログラム
【課題】第一言語の原文には必ずしも表現されておらず、解釈に言外の知識を要する曖昧性がある場合であっても精度よく翻訳可能とすることである。
【解決手段】実施形態の機械翻訳装置によれば、曖昧箇所検出手段は、翻訳対象となる第一言語文書では明示されていないが文書解析翻訳手段で得た第二言語の訳文には必要となる情報が欠落している曖昧箇所を検出する。質問文作成手段は、曖昧箇所ごとに第二言語の訳文に必要となる情報を得るためのユーザへの質問文を作成する。質問文付与手段は第一言語の原文の該当箇所にその質問文を付与し、表示装置に第一言語の原文及び質問文を表示する。回答解析手段は、質問文に対するユーザからの回答から第二言語の訳文に必要となる情報を獲得して第二言語の訳文に反映させる。
(もっと読む)
機械翻訳装置、機械翻訳方法、およびそのプログラム
【課題】高い翻訳精度の機械翻訳技術を提供する。
【解決手段】本発明は、部分仮説を拡張する手法によって、翻訳元言語の単語列から翻訳先言語の単語列を生成する機械翻訳装置2であって、(a)翻訳候補となる翻訳先言語の単語列だけでなく、少なくとも、(b)翻訳元言語の文を翻訳先言語の語順に並び替えた単語列、および、(c)翻訳先言語の文を翻訳元言語の語順に並び替えた単語列、のいずれかを考慮して部分仮説の評価値を示す部分仮説スコアを算出することで、翻訳精度を向上させることができる。
(もっと読む)
翻訳支援装置、方法及びプログラム
【課題】翻訳者の訳語決定作業を適切に支援する。
【解決手段】本装置は、第1言語の単語と当該単語に対する第2言語の訳語とを格納する訳語格納部と、第2言語による例文を格納するコーパス格納部と、第1言語の複合語の入力を受け付けた際、当該複合語に含まれる各単語について、訳語格納部から当該単語に対する訳語を取得する取得部と、取得した訳語の組み合わせで表される第1訳語列の一部分である第2訳語列を生成する訳語列生成部と、第1訳語列に含まれ且つ第2訳語列には含まれない単語である差分単語の代わりとしてワイルドカード検索のための所定のデータを第2訳語列に付して検索キーを生成するキー生成部と、検索キーを用いてコーパス格納部を検索し、当該検索キーにて検出された単語列から第2訳語列以外の単語である代替訳語を抽出する抽出部と、第1訳語列と共に、差分単語の該当部分に対応付けて、抽出された代替訳語を列挙して提示する出力部とを有する。
(もっと読む)
翻訳装置、方法、及びプログラム
【課題】ソフトウェアのドキュメントの翻訳に好適な翻訳装置、方法、及びプログラムを提供する。
【解決手段】ソフトウェアのソースコードを記憶するソースコード記憶部32と、ソースコードの仕様が記載されたドキュメントを原言語で生成する生成部45と、生成されたドキュメントを記憶するドキュメント記憶部34と、ドキュメント記憶部からドキュメントを取得するとともに、ドキュメントの生成元のソースコードをソースコード記憶部から取得する取得部50と、取得されたソースコードを参照して、取得されたドキュメントからソースコード中に出現するプログラム要素を検出する検出部60と、検出されたプログラム要素を、目的言語への翻訳が不要な翻訳不用語句に設定する設定部70と、ドキュメントの翻訳不要語句以外の語句を目的言語に翻訳する翻訳部80と、ドキュメントの翻訳結果を出力する出力部20と、を備える。
(もっと読む)
文書画像表示装置、文書画像表示方法、及びプログラム
【課題】文書と、その文書に対応する適切な画像とを表示する文書画像表示装置を提供する。
【解決手段】文書が記憶される文書記憶部11、文書をチャンクに分割し、各チャンクの係り受けを示す係り受け情報を取得する文書解析部12、その係り受け情報を用い、一のチャンクとそのチャンクのみから係りを受けるチャンクとの関係である単受け関係によってつながる複数のチャンクを一のチャンクに併合する併合部13、併合後のチャンク及び併合されなかったチャンクのうち、少なくとも併合後のチャンクを含む1以上のチャンクに対応する複数の画像をそれぞれ取得する画像取得部14、文書に対応するチャンク列と、チャンク列に含まれる各チャンクに対応する、画像取得部14が取得した2以上の画像とを、チャンクと2以上の画像との対応が分かるように表示する表示部16、を備える。
(もっと読む)
音声翻訳装置、方法、およびプログラム
【課題】発話内容の修正にかかる利用者の負担を軽減させることができる音声翻訳装置、方法、およびプログラムを提供する。
【解決手段】音声入力受付部100は、日本語の発話音声の入力を受け付け、音声認識部120は、発話音声の入力が受け付けられる毎に、当該発話音声を認識して文字列を生成し、蓄積部42は文字列を順次蓄積し、判定部130は、新たに蓄積する候補である第2文字列が先に蓄積された第1文字列の言い直しであるか否かを判定し、修正部140は、言い直しでない場合には、第2文字列を蓄積部42に蓄積させ、言い直しである場合には、第1文字列を第2文字列に修正して蓄積部42に蓄積させ、翻訳部150は、蓄積部42に蓄積される毎に、蓄積されている文字列を英語に翻訳し、出力部30は、翻訳結果を出力する。
(もっと読む)
翻訳支援プログラム、及び該システム
【課題】1回のキーワード検索で訳語候補リストを入手することができる翻訳支援プログラムを目的とする。
【解決手段】日本語と外国語が混在した原文に含まれる補正対象文字を補正し、補正済み原文を構成する各文字を文字種記号に置換し、隣接する同一の文字種記号を共通化したものである文字種記号列を生成し、文字種記号列を構成する各文字種記号を言語記号に置換し、隣接する同一の言語記号を共通化したものである言語記号列を生成し、言語記号列中の隣接する言語記号のうち相互に異なる言語記号を対として抽出し、その対のうち日本語を示す言語記号に係る文字種記号の組み合わせパターンに対応する日本語の単語と、対応する外国語の単語との単語対を取得し、取得した単語対の一方の単語に対して他方の単語を、該一方の単語の訳語候補として登録することにより、上記課題の解決を図る。
(もっと読む)
情報処理装置および情報処理方法
【課題】ユーザが所望の例文および訳文を容易に検索できる装置を提供する。
【解決手段】キーワード選択部442は、予測キーワードリスト428に基づき、入力部410が受け付けた文字入力に対応するキーワードを表示部462に表示する。例文選択部444は、入力部410が受け付けた指示に基づいて表示されたキーワードの中から選択キーワードを決定する。そして、例文選択部444は、選択キーワードに関連する例文を、テンプレートデータベース422およびインデックスデータ424に基づいて取得し、表示部462に表示する。訳文出力部446は、入力部410が受け付けた指示に基づいて表示されたキーワードの中から1つの例文を選択し、選択された例文の訳文を、テンプレートデータベース422および辞書423に基づいて取得する。そして、訳文出力部446は、取得した訳文を出力部460に出力させる。
(もっと読む)
情報処理装置および情報処理方法
【課題】ユーザが、所望するコンテンツを容易に検索できる装置を提供する。
【解決手段】会話アシスト装置100は、入力部410と記憶部420と処理部440と出力部460とを備える。記憶部422に格納されているテンプレートデータベース422は、複数のテンプレート500からなる。各テンプレート500は、複数の言語のカテゴリ文と、キーワードとを対応付けている。キーワードは、1つのキーワードの表記と、1つまたは複数の文字入力(キーワードの読み)とで指定される。入力部410が複数の文字入力のいずれかを受け付けると、例文選択部440は、入力された文字入力に対応するキーワードをもつテンプレート500を抽出する。
(もっと読む)
機械翻訳装置及び機械翻訳プログラム
【課題】ユーザにより辞書登録または訳語学習された語句の関連語の辞書登録/訳語学習を何度も行う手間を省き、翻訳処理の効率を上げることである。
【解決手段】ユーザによって指定された第一言語の原文中の辞書登録または訳語学習の対象となる原文語句、その原文語句に対応する訳文語句及び訳文語句の訳語情報を辞書登録/訳語学習指定部26aで受け付け、登録見出し語・訳語対応付け部26bで原文語句の構成語と訳文語句の構成語との対応付けを行い、関連表現パターン展開部27aは、関連表現パターン定義格納部27cに格納された関連表現パターンに基づいて辞書登録または訳語学習の対象となる原文語句の関連表現を展開し原文語句から派生する関連語句を作成し、訳出パターン作成部27bは関連表現パターン展開部27aで作成された関連語句に対して関連語句の訳語を作成する。
(もっと読む)
機械翻訳装置及びプログラム
【課題】訳文の論理の展開が訳文言語として明確になっている訳文を作成することができる機械翻訳装置を提供することである。
【解決手段】入力装置から入力された第1言語の原文を入力処理部25で入力し、入力された原文に対して入力装置から語句が指定されたとき、主要キーワード指定部30は、指定された第1言語の語句を主要キーワードとして翻訳部27に通知する。翻訳部27は、主要キーワード指定部30から通知された第1言語の語句またはその語句を含むフレーズが翻訳後の第2言語の訳文の文頭に最も近い位置に存在するという条件を満たした訳文を生成する知識情報を翻訳辞書部32の中から選択して翻訳を行い、出力処理部35は、翻訳対象の原文や翻訳部による翻訳後の第2言語の訳文を出力装置に出力する。
(もっと読む)
対訳表現処理装置およびプログラム
【課題】対訳表現同士を推定する処理であって、複数単語同士のアラインメントができるとともに、長い対訳表現のアラインメントを可能とする対訳表現処理装置を提供する。
【解決手段】対訳表現処理装置が、複数言語による対訳文書の組である対訳文書組データを複数記憶する対訳文書組群データ記憶部と、前記対訳文書組データ記憶部から読み出した前記対訳文書組データに基づき、単一の前記対訳文書組データ内に出現する語系列の前記複数の言語間での共起頻度をカウントし、全ての前記対訳文書組データにおける前記共起頻度の合計値が所定の頻度閾値以上となるような、前記複数言語による前記語系列の組を対訳フレーズ組候補として抽出して出力する対訳文書組群データ分析処理部とを具備する。
(もっと読む)
翻訳支援システム、翻訳支援方法および翻訳支援用プログラム
【課題】「部品となる複数の文字列を組み合わせて訳文を作成する」という作業フローにおいて、訳文作成の過程で収集される部品文字列の再利用性を高め、効率的な訳文の確認や再編集をし易くする翻訳支援システムを提供する。
【解決手段】編集手段201は、原文を表示する原文表示欄と、訳文の入力および表示を行うための訳文表示欄と、部品文字列の入力および表示を行うための部品表示欄とを表示する。部品登録手段203は、翻訳システムが生成した翻訳結果の一部の文字列が部品表示欄にコピー等されると、その文字列を部品文字列として部品記憶手段303に記憶させるとともに、翻訳システムが保持するその部品文字列の部品情報も記憶させる。また、部品制御手段203は、表示された部品文字列の部品情報を表示する。
(もっと読む)
音声翻訳装置、音声翻訳方法、及びプログラム
【課題】フィラーも翻訳する音声翻訳装置を提供する。
【解決手段】原言語音声情報を受け付ける音声情報受付部11、原言語音声情報を音声認識する音声認識部13、音声認識結果情報を機械翻訳する機械翻訳部15、翻訳結果情報に対応する目的言語音声情報を生成する音声生成部17、原言語音声情報でのフィラー位置を特定するフィラー時間位置特定部20、フィラーのパラ言語を含む原言語フィラー情報を抽出するフィラー情報抽出部21、音声認識結果情報でのフィラー位置を特定するフィラーテキスト位置特定部22、目的言語音声情報でのフィラー位置であるフィラー挿入位置を特定するフィラー挿入位置特定部23、原言語フィラー情報に対応する目的言語フィラー情報をフィラー挿入位置に挿入するフィラー情報挿入部25、目的言語フィラー情報を含む目的言語音声情報を出力する音声情報出力部19を備える。
(もっと読む)
1 - 20 / 89
[ Back to top ]