
Fターム[5B091AA15]の内容
Fターム[5B091AA15]に分類される特許
201 - 220 / 617
ユーザ質問及びテキスト文書の意味ラベリングに基づく質問応答システム及び方法
ユーザにより自然言語で表現された質問に対する的確な答えを電子的又はデジタルの形態で提供されるテキスト文書群の中からサーチするための質問応答システムは、テキスト文書群とユーザの質問の自動意味ラベリングに基づいている。このシステムは、基礎的知識タイプ、それらの構成要素及び属性に関するマーカー、ターゲットについての所定の分類辞からの質問タイプに関するマーカー、及びあり得る答えの構成要素に関するマーカーの助けにより意味ラベリングを実行する。照合処理では、意味ラベルの対応を利用して、質問に対する的確な答えを求め、ユーザに対してそれら答えを文の断片又は新たに合成された自然言語の句の形で提示する。ユーザは、独立的に、システムの分類器に新たなタイプの質問を追加し、システムの言語知識ベースのために必要な言語パターンを生成することができる。  (もっと読む)
(もっと読む)
意味解析装置、方法、およびプログラム
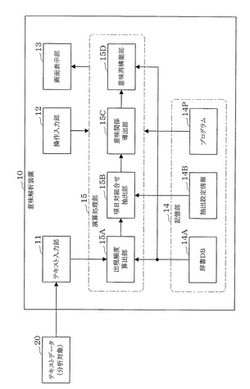
【課題】通信サービス提供時に得られるテキストデータからその特徴として抽出した単語間の意味関係を的確に導出する。
【解決手段】項目対組合せ抽出部15Bにより、これら項目のうちから当該出現頻度の大きい項目を抽出し、抽出したこれら項目からなるすべての項目対ごとに、当該項目対を構成する2つの項目に属する単語が同時に出現する頻度を示す共起度を算出して、これら項目対のうちから共起度の大きい項目対を抽出し、抽出したこれら項目対のすべての組合せごとに共起度を算出して、これら組合せのうちから当該共起度の大きい組合せを抽出し、意味関係導出部により、項目対組合せ抽出部で抽出された組合せのうち異なる3つの項目を含む組合せを選択し、当該組合せに含まれる項目間の共起度の大小関係に基づいて、これら項目間の意味的関係を示す意味関係情報を導出する。
(もっと読む)
機械学習装置及び方法

【課題】機械学習のための教師データに追加する用語の中から不適切な用語を省き、教師データに適合する用語を追加し、教師データの精度を向上させる機械学習装置及び方法を提供すること。
【解決手段】本発明に係る機械学習装置10は、教師データDB31と、NE辞書DB41とを備え、教師データDB31から教師データを取得し、取得した教師データとともに出現する用語との組合せを取得し、取得した組合せにおいて、教師データの出現部分を任意の置き換え可能な用語が入るとみなしたパターンとして抽出し、抽出したパターンの置き換え可能な部分に入る用語であるパターン対応用語を、コーパスの中から取得する。そして、取得した、パターン対応用語がNE辞書DB41に基づいて固有の表現に適合するか否かを判定し、判定に基づいて適合するパターン対応用語を取得し、取得した適合するパターン対応用語を教師データDB31に追加する。
(もっと読む)
オントロジーの類似性行列の効率的な計算
【課題】 本発明は、オントロジーの類似性行列の効率的な計算を提供する。
【解決手段】 一実施形態では、オントロジーを生成する段階は、複数の逆索引リストを有する逆索引にアクセスする段階を有する。逆索引リストは言語の言葉に対応してよい。各逆索引リストは、言葉の言葉識別子及び言葉が現れる文書セットの1又は複数の文書を示す1又は複数の文書識別子を有してよい。実施形態は、逆索引に従って言葉識別子索引を生成する段階も有する。言葉識別子索引は、複数のセクションを有し、各セクションは1つの文書に対応する。各セクションは、文書内に現れる1又は複数の言葉の1又は複数の言葉識別子を有してよい。
(もっと読む)
多人数思考喚起型対話装置、多人数思考喚起型対話方法、多人数思考喚起型対話プログラム並びにそのプログラムを記録したコンピュータ読み取り可能な記録媒体
【課題】対話の状況に応じてエージェントの発言の内容やタイミングを決定できる多人数思考喚起型対話装置を提供する。
【解決手段】対話状況に応じてエージェントの対話行為を選択する対話制御ルールと、エージェントの発言表現を対話状況等に応じて選択する発言生成ルールとを記憶し、ユーザ発言を対話行為に変換して発言キュー6と対話状態5に書き込むユーザ発言理解部2と、発言キュー6の先頭の対話行為と対話状態5に記憶された対話行為の履歴を参照して対話制御ルールを適用してエージェントに関する対話行為を選択してエージェント発言生成部4に送り発言キュー6の先頭の対話行為を取り除く対話制御部3と、対話行為を取得したときに対話行為の履歴を参照して発言生成ルールに基づいてエージェントの発言表現を生成してユーザに提示し、この対話行為を対話状態5に格納して発言キュー6に追加するエージェント発言生成部4とを備える。
(もっと読む)
出現表記レコード同定装置、削除規則生成装置、その方法、プログラム及び記録媒体
【課題】登録表記と実体との対応リストを網羅的に作成することなく、実体データベースのレコードへの出現表記の対応付けを可能とする。
【解決手段】候補生成手段8により、削除規則DBを用いて出現表記を削除表記に変換し、削除表記DB2から当該削除表記を含む登録削除表記を候補として取得し、対応するIDを削除表記−IDリスト対応表3から取得して登録削除表記の候補とそのIDとの対からなる候補IDリストを生成し、曖昧性解消手段10により、処理済みの入力文章から特徴語を抽出して出現表記特徴語リストを生成し、特徴語DB4から候補IDリスト中の各IDに対応する特徴語とその重み値を取得して登録削除表記の候補毎の特徴語リストを生成し、候補毎の特徴語リストと出現表記特徴語リストとの類似度を求め、最も高い類似度を有する候補の信頼度を算出し、所定の閾値以上であれば当該候補のIDを前記出現表記とともに出力する。
(もっと読む)
絵文字を含む文章ファイルを評価する評価分析サーバ、方法及びプログラム
【課題】携帯電話機から投稿される絵文字を含む文章ファイルであっても、評判分析のための評価レベルを導出することができる評価分析サーバ等を提供する。
【解決手段】評価分析サーバは、文字列及び絵文字を含む文章ファイルにおける評価レベルを分析する。評価分析サーバは、特定絵文字に評価レベルを対応付けた評価絵文字を登録する絵文字辞書手段と、文章ファイルを形態素に分解する形態素解析手段と、絵文字辞書手段を用いて、評価絵文字に対応する形態素を抽出する絵文字抽出手段と、絵文字辞書手段を用いて、抽出された評価絵文字に対する評価レベルを検索する絵文字レベル検索手段と、評価絵文字全ての評価レベルの和に基づいて、文章ファイルの評価レベルを決定する評価レベル決定手段とを有する。
(もっと読む)
読み生成装置
【課題】固有名詞における多様な表記の違いの影響を回避して、読み情報の生成における誤りを軽減し、読み情報の精度を向上させる。
【解決手段】読み生成装置10は、固有名詞辞書103、104と、一般単語辞書102と、代替辞書201、202と、入力部1と、一般単語辞書102および固有名詞辞書103、104から、入力テキストに部分一致する単語を検索して単語候補とする単語検索部2と、固有名詞辞書103、104に格納された単語を、代替辞書201、202に登録された代替情報によって代替したときに、入力テキストに部分一致する単語を検索して単語候補とする代替単語検索部3と、単語検索部2および代替単語検索部3によって検索された単語候補の中から、入力テキストに相当する単語の組み合わせを特定する単語特定部4と、入力テキストの読みを示す情報を生成する読み生成部5とを備える。
(もっと読む)
言語処理システムおよびプログラム
【課題】入力文の記号論理式レベルの文への単純化、記号論理式レベルの単純な文を用いた推論、及び記号論理式レベルの文に基づく出力文の生成の統一的、単純な方法による実現、並びに同様な方法による論理又は言語表現の自動的学習の実現。
【解決手段】従来記号論理式によって行われている推論処理を、記号論理式と同レベルの単純さの自然言語文を用いて行い、それにより入力文から出力文への変換処理を統一する。また、入力文から記号論理式レベルの文への言い換えを逆用して、出力文生成を実現する。さらに、同様の言い換えを利用して、単純化された論理又は言語表現を抽出する。
(もっと読む)
言語モデル作成方法、言語モデル作成装置および言語モデル作成プログラム
【課題】教師データを用いずとも、言語モデルの作成と単語分割とを行えるようにする。
【解決手段】言語モデル作成装置は、文字列データ131に格納された複数の文をランダムな順に選択し、言語モデル132を用いて、この選択した文における単語の区切り目の候補となる文字列を示した文字列分割パターン群を作成する。また、その文がその文字列分割パターン群の文字列分割パターンに該当する確率を記憶部に記録しておき、この確率に従って、文字列分割パターン群の中から、文字列分割パターンを選択する。そして、この選択した文字列分割パターンを用いて言語モデル132を更新する。このような処理を、文字列データ131に格納された複数の文すべてについて実行し、言語モデル132を最適化する。そして、このようにして最適化された言語モデル132を用いて、文の最尤単語分割を実行する。
(もっと読む)
対話装置、対話プログラムおよび対話方法
【課題】ユーザの発話に対してユーザの関心に応じた応答を行うことができる対話装置を提供する。
【解決手段】対話装置1は、ユーザ情報入力手段10、主要語抽出手段20、関心度判定手段30、関連語データベース40、関連語選択手段50、定形文データベース60、応答文作成手段70、および、応答文出力手段80を具備する。主要語抽出手段20は、ユーザが表した言語を構成する単語から主要語を抽出する。関心度判定手段30は、ユーザの関心度について少なくとも高低を示すユーザ関心度を判定する。関連語選択手段50は、ユーザ関心度に応じて、複数の単語のそれぞれに関連する関連語を収納した関連語データベース40内から主要語と関連する関連語を選択する。応答文作成手段70は、定形文データベースに収納された定形文に関連語を挿入してユーザが表した言語に対する応答文を作成する。
(もっと読む)
地域特性辞書生成方法及び装置
【課題】地域毎に特徴語を抽出して、特徴語に関する地域特性辞書を生成する方法及び装置を提供すること。
【解決手段】地域特性辞書生成サーバ1は、ブログサーバ2に格納されているブログのうち、地域ブログの情報を収集するブログ情報収集部11と、収集された地域ブログの情報より用語を抽出して、用語の出現数の合計値を地域毎に計数する用語出現数計数部12と、地域ブログの数量及び用語が含まれている地域ブログの数量を計数するブログ数計数部13と、地域における用語の出現数の合計値、地域ブログの数量、及び用語が含まれている地域ブログの数量に基づいて所定の演算を行い、地域における用語の出現頻度の偏差を算出する用語出現偏差算出部14と、算出した用語の出現頻度の偏差が予め定めた閾値よりも大きい場合に、用語の出現頻度の偏差を算出した地域の地域特性辞書である辞書DB22に、当該用語を登録する辞書登録部15とを備える。
(もっと読む)
漢字文における単語区分方法
【課題】単語である可能性がある文字の組み合わせを、自然言語の文字列から選択するファシリティを提供する。
【解決手段】ファシリティは、複数の文字の各々について、(a)当該文字で始まる単語の第2位置に現れる文字、および(b)文字が単語内において現れる位置の指示を用いる。シーケンス内に現れる複数の文字の連続する組み合わせの各々について、ファシリティは、組み合わせの第2位置に現れる文字が、組み合わせの第1位置に現れる文字で始まる単語の中に現れるか否かについて判定を行なう。現れる場合、ファシリティは、組み合わせの各文字が、当該組み合わせの中でそれが現れる位置において、単語の中で現れることが示されているか否かについて判定を行なう。示されている場合、ファシリティは、文字の組み合わせが単語である可能性があると判定する。
(もっと読む)
テキスト・データに含まれる固有表現又は専門用語から用語辞書を作成するためのコンピュータ・システム、並びにその方法及びコンピュータ・プログラム
【課題】単語カテゴリの用語辞書を構築する場合に、新規追加されたテキストから、登録すべき単語を漏れなく見つけ、且つ作業を効率的に行う。
【解決手段】テキスト・データの形態素解析を行い、トークン列データを取得する形態素解析部と、上記トークン列データの各トークンをカテゴリ辞書を用いて判別し、未カテゴリ語を抽出するカテゴリ判別部と、抽出した未カテゴリ語を未カテゴリ語照合ルールと照合し、該未カテゴリ語照合ルールに合致する未カテゴリ語を登録候補語として抽出する未カテゴリ語照合部と、上記未カテゴリ照合部と、上記トークン列データのトークン列をトークン列照合ルールと照合し、該トークン列照合ルールに合致するトークン列を登録候補語として抽出するトークン列照合部とを含み、上記カテゴリ辞書に上記登録候補語を登録するかどうかの選択をユーザに許す許可部とで構成されるコンピュータシステム。
(もっと読む)
能動学習装置及び方法
【課題】日本語係り受け解析において、受動学習の場合よりも、より少ない人手コストで高い精度が得られる能動学習装置及び方法を提供すること。
【解決手段】能動学習装置10は、日本語を構成する文節の係り関係の正解事例データDB41に基づいて、文節の係り関係を判定する係り関係モデルDB31を作成する。そして、能動学習装置10は、一の文を係り関係モデルDB31を用いて係り受け解析を行い、解析結果を出力し、出力した解析結果が所定の場合に一の文を選択し、選択した一の文をユーザ端末60に提示し、提示した一の文を構成する文節の係り関係についての判定情報を受け付け、受け付けた判定情報に基づく正解データを正解事例データDB41に追加し、追加された正解事例データDB41に基づいて係り関係モデルDB31を更新する。
(もっと読む)
類似表現抽出装置、サーバ装置及びプログラム
【課題】シソーラスに登録されていない表現が多い電子文書でも、十分な精度を保証しつつ、類似表現を抽出する。
【解決手段】類似表現抽出装置30は、入力された電子文書内の文を形態素解析、構文解析及び共起表現抽出し、単語属性値及び単語ベクトルを作成し、単語ベクトル間の単語類似度から単語グループを作成し、シソーラス情報の表現を学習データとして生成し、学習データ間の類似度に基づき学習データグループを作成し、統合された単語グループ毎に、学習データグループ内の学習データを含む度合を示す大域評価値を計算し、単語グループの単語類似度の分散を計算し、得られた分散を局所評価値とし、両評価値に基づいて単語グループの境界を調整し、単語グループ内の各単語を類似表現として抽出して出力する。
(もっと読む)
表現補完装置およびコンピュータプログラム
【課題】大量のルール等を予め準備する手間をかけずに、与えられる文データに基づき、文中において欠落している評価表現を補完する表現補完装置を提供する。
【解決手段】情報抽出処理部は、文のうち、評価表現を含む文については当該文の特徴データと当該文の評価表現とを抽出して評価付き抽出情報として評価付き抽出情報記憶部に書き込み、評価表現を含まない文については当該文の特徴データを抽出して評価欠落抽出情報として評価欠落抽出情報記憶部に書き込む。評価補完処理部は、クラスタリング処理を行なうことにより前記特徴データ間の類似度を算出し、前記評価欠落抽出情報に含まれる前記特徴データとの類似度が高い所定範囲の前記特徴データを有する前記評価付き抽出情報を特定し、該特定された評価付き抽出情報に含まれる前記評価表現を用いて当該評価欠落抽出情報の評価表現を補完する。
(もっと読む)
未知語登録方法及び装置及びプログラム及びコンピュータ読取可能な記録媒体
【課題】形態素解析装置で用いるための未知語を高精度で抽出する。
【解決手段】本発明は、一つの複合語文節からなる検索キーワードの集合で入力されることの多いクエリログの1クエリをスペースで分割して得られる検索キーワードの異なりの集合である検索キーワード集合から未知語候補を抽出し、未知語候補の中から多用されているものを未知語として抽出し基準辞書に登録する。未知語抽出の方法として、未知語候補の集合と基準辞書とをマージして暫定辞書を生成し、該暫定辞書を用いてコーパスの形態素解析を行い、未知語候補の出現頻度をカウントし、該出現頻度が所定の閾値より多い未知語候補を未知語とする。または、未知語候補を検索クエリとして検索システムで検索を行い、検索結果件数が所定の閾値より多い未知語候補を未知語とする。
(もっと読む)
対話装置、対話方法、対話プログラムおよび記録媒体
【課題】 社会的対話の仕方を適宜変更することが可能な対話システムを実現する。
【解決手段】 対話装置1の発話理解部2は、ユーザの発話を解析して、該発話の意味内容を示す対話行為タイプを求める。対話管理部3は、ドメイン知識データベース5を参照して発話理解部2の取得情報に対して応答可能な対話行為タイプ列を取得し、設定パラメータから自己開示および共感の対話行為を行う生起確率を求める。そして、取得した対話行為タイプ列と前記生起確率のそれぞれで表現される自己開示および共感の特徴量を比較して、該両特徴量が合致する対話行為タイプ列を選択し、付随情報を付加して対話行為列を生成する。発話生成部4は、対話管理部3の生成した対話行為列を自然な文章に変換し、音声またはテキストによりユーザに提示する。
(もっと読む)
フレーズ間関係解析装置、フレーズ間関係解析方法、フレーズ間関係解析プログラム、および、フレーズ間関係解析プログラムを記録したコンピュータ読み取り可能な記録媒体
【課題】所定のインスタンスとの関係がオントロジ上での特定の関係に該当するフレーズを、入力された解析対象記事から抽出するに際して、該抽出に係る再現率および適合率の向上が図られるようにする。
【解決手段】関係解析部10によって、所定のインスタンスとの関係がオントロジ上での特定の関係に該当するフレーズを解析対象記事から抽出すると共に、間接的関係解析部20によって、所定のインスタンスとの関係がオントロジ上での特定の間接的関係に該当する間接的関係フレーズを解析対象記事から抽出する。
(もっと読む)
201 - 220 / 617
[ Back to top ]