
Fターム[5B091AB06]の内容
Fターム[5B091AB06]に分類される特許
1 - 20 / 79
CJK名前検出
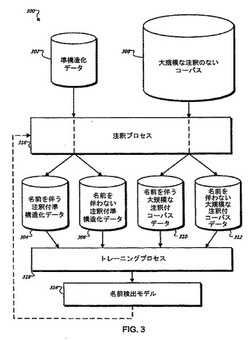
【課題】中国、日本、および韓国の言語のための名前を検出する。
【解決手段】名前検出に関する実施例が提供される。方法は、姓のコレクションと、n-グラムのコレクションを含む注釈付コーパスとを使用することで、未加工名前検出モデルを生成するステップを含み、各n-グラムは、前記注釈付コーパスにおいて名前として出現することの対応する確率を有する。方法は、前記未加工名前検出モデルを準構造化データのコレクションに適用して、注釈付準構造化データを形成するステップと、前記未加工名前検出モデルを大規模な注釈のないコーパスに適用して、名前を特定する前記大規模な注釈のないコーパスのn-グラムと、名前を特定しないn-グラムとを特定する大規模な注釈付コーパスデータを形成するステップとを含み、前記注釈付準構造化データは、名前を特定するn-グラムと名前を特定しないn-グラムとを特定する。方法は、名前検出モデルを生成するステップを含む。
(もっと読む)
辞書管理装置、辞書管理方法、辞書管理プログラム

【課題】オンライン辞書について辞書管理の負担を軽減させた高品質な類似検索機能を提供する。
【解決手段】類似検索部3は、辞書管理者の入力表記に基づき全体辞書を検索し、入力表記に類似する表記を特定する。主要部特定部4は、類似検索手段で特定された類似表記と入力表記との共通部分を特定し、特定された共通部分が主要部辞書に存在すれば、該共通部分を主要部候補と判定する。この主要部候補を類似表記から除外した付加部候補が付加部辞書に存在するか否かを判定し、判定結果に応じて主要部候補を主要部と確定する。距離算出部5は、確定された各類似表記の主要部と入力表記の主要部との編集距離を算出する。更新確認部6は、算出された編集距離順に類似表記・主要部・付加部を辞書管理者に提示する。
(もっと読む)
音声合成装置、音声合成プログラムおよび音声合成方法
【課題】テキストの読み上げ精度を向上させ、聞き手が判りやすい自然な読み上げ音声を生成することのできる音声合成装置を提供する。
【解決手段】音声合成装置1は、任意の対象についての情報を示す第1のテキストを形態素解析して第1の解析結果を出力する第1解析部5と、前記第1のテキストが示す情報と同一の対象について表現が異なる情報を示す第2のテキストを形態素解析し、前記第1の解析結果を参照して第2の解析結果を出力する第2解析部6と、前記第2の解析結果に基づいて、前記第2のテキストに関する合成音声を生成するための表音文字列を生成する表音文字列生成部8とを備える。
(もっと読む)
略称検索装置,方法およびプログラム,ならびに略称検索機能を備えるデータパース装置
【課題】 固有の名称が含まれる文字列から,辞書に未登録の略称を検索できるようにする。
【解決手段】 データパース装置1は,検索対象を入力するデータ入力部13と,辞書記憶部11の辞書をもとに検索対象から法人名称を検索する辞書引き部14と,検索対象に辞書に登録されていない文字列がある場合に,略称を検索する略称検索部15を備える。略称検索部15は,辞書の登録語と部分的に一致する登録語を検索し,検索した登録語から,部分一致する範囲が長く一致の割合が高いものを特定し,特定した登録語と一致する範囲を略称とし,特定した登録語をその正式名称とする。
(もっと読む)
FAQ候補抽出システムおよびFAQ候補抽出プログラム
【課題】談話データの特性に強く、文章構造の枠組みを規定せずに談話セマンティックに基づいて談話データからFAQの候補となる質問文を抽出するFAQ候補抽出システムを提供する。
【解決手段】談話データ101および談話セマンティクス200を入力とし、談話データ101からFAQ候補となる質問文を抽出して出力するFAQ候補抽出システム1であって、談話セマンティクス200は各ステートメントのフロー情報21を含み、談話データ101から、顧客によって発話され、質問文もしくは要求文であることを示すフローが設定された質問・要求ステートメントを抽出する質問抽出部60と、質問・要求ステートメントから指定されたキーワードを含むものを抽出する候補抽出部80と、質問・要求ステートメントについてクラスタリングし、各クラスタの代表となる質問・要求ステートメントをFAQ候補300として出力するクラスタリング部90とを有する。
(もっと読む)
関係情報抽出装置、その方法及びプログラム
【課題】複数の固有表現間の関係情報を高精度で抽出可能な装置、方法及びプログラムを提供する。
【解決手段】入力された複数の固有表現に関係する情報を抽出する装置であって、前記各固有表現を含むテキストが入力されると、入力テキストを形態素解析するとともに入力テキストを構成する文節の係り受けを解析する解析処理部10と、解析処理部による解析結果を取得すると、入力テキストに含まれる少なくとも一つの自立語を関係情報候補として抽出するとともに、該各固有表現の関係情報として過去に用いられた過去関係情報が該関係情報候補に経時変化したと推定される度合を表す変化情報を、抽出された関係情報候補毎に取得し、解析結果及び変化情報に基づいて関係情報候補から関係情報を抽出する関係情報抽出処理部20とを備えた。
(もっと読む)
関係情報抽出装置、その方法及びプログラム
【課題】あらゆるテキストにおいて、複数の固有表現間の関係情報を抽出可能な装置、その方法及びプログラムを提供する。
【解決手段】入力された複数の固有表現の関係情報を抽出する装置であって、各固有表現を含むテキストが入力されると、入力テキストを形態素解析するとともに入力テキストを構成する文節の係り受けを解析する解析処理部10と、入力テキストを構成する複数の文のうち各固有表現を含む文とは異なる他の文から自立語を含む文節を関係情報候補として抽出した後に、各固有表現及び関係情報候補の全てが抽出されるまで入力テキストの文頭から順に抽出された名詞文節を、該名詞文節に伴う助詞に対応付けられた記憶領域に記憶させ、各固有表現及び関係情報候補の全てが抽出されると記憶領域における名詞文節の格納状態を表す格納情報を取得して、解析結果及び格納情報に基づいて関係情報を抽出する関係情報抽出処理部20とを備えた。
(もっと読む)
固有表現抽出装置、文字列−固有表現クラス対データベース作成装置、固有表現抽出方法、文字列−固有表現クラス対データベース作成方法、プログラム
【課題】固有表現を正しくかつ詳細に分類することを可能とする固有表現抽出装置、固有表現抽出方法、固有表現抽出プログラムを提供する。
【解決手段】テキストを入力とし、形態素と係り受け解析結果と固有表現を出力するテキスト解析部1100と、形態素と固有表現を入力とし、トピックを抽出するトピック抽出部1210と、係り受け解析結果を入力とし、文構造を出力する文構造抽出部1220と、固有表現クラスを判定して出力するクラス判定部1230と、シソーラス1240と、文字列−固有表現クラス対データベース1250と、トピックと文構造と固有表現クラスを入力とし、ラベルスコアを出力とするラベルスコア計算部1300と、ラベルごとのラベルスコア計算に用いられるラベル判定モデル1310と、ラベルスコア最大値からラベルを判定するラベル判定部1400と、前記判定されたラベルと固有表現の組を出力する出力部1500とを備える。
(もっと読む)
スパムブログ判定装置及び方法
【課題】管理者による作業を容易にしてスパムブログを判定するスパムブログ判定装置及び方法を提供する。
【解決手段】スパムブログ判定装置1は、登録指定を受け付けた所定キーワードを所定キーワードDB21に記憶する所定キーワード記憶制御手段12と、判定対象のブログ記事を受け付けたことに応じて、所定キーワードDB21に記憶した所定キーワードを素性として用いてブログ記事がスパムブログであるか否かを機械学習により判定する機械学習手段14と、機械学習手段14による判定対象のブログ記事のうち、所定キーワードDB21に記憶された所定キーワードを含むブログ記事と、スパムブログであるか否かの機械学習による判定結果とを対応付けて出力するスパム判定結果出力手段15と、所定キーワードの削除指定を受け付けたことに応じて、所定キーワードDB21に記憶された所定キーワードを削除する調整戻し手段17とを備える。
(もっと読む)
情報処理装置、情報処理方法、およびプログラム
【課題】「近傍の単語は互いに関係がある」という仮定に基づきながらも、その仮定が成立していない可能性をも考慮した、文脈情報を利用した統計的自然言語処理を確立する。
【解決手段】ステップS1で、処理対象の文書が特徴量抽出部に入力され、ステップS2で、特徴量抽出部が、処理対象の文書に含まれる文脈情報毎に特徴量を抽出する。ステップS3で、特徴量解析部は、処理対象の文書の各文脈情報の特徴量に対応する潜在変数をギブスサンプリングにより推定する。ステップS4で、クラスタリング処理部は、各文脈の文脈トピック比を新たな特徴量ベクトルとみなし、この特徴量ベクトルに基づいて、文脈情報(の固有名詞ペア)のクラスタリングを行う。ステップS5で、基本情報生成部は、解析結果DBに保持されているクラスタリング結果に基づいて基本情報を生成する。本発明は、文書の統計的自然言語処理に適用することができる。
(もっと読む)
情報抽出システム及び情報抽出プログラム
【課題】構文解析技術を用いることなく、自然文から構造化された情報を抽出する技術の提供。
【解決手段】企業名、企業活動、活動対象物を示す具体的な表現文字列毎にその種類を示す抽象化文字列を登録した辞書記憶部26と、文を形態素単位に分解し、各形態素に対応の抽象化タグを関連付ける形態素解析処理部12と、企業活動の抽象化タグが付与された形態素を文の述語と認定すると共に、主語に付属する助詞毎及び目的語に付属する助詞毎に対応語の格納欄が設けられた格スロットに、文の述語単位で対応語を充填し、述語を関連付ける格スロット充填処理部20と、抽出すべき主語の抽象化タグ及び助詞を特定する条件と、抽出すべき述語の抽象化タグを特定する条件と、抽出すべき目的語の抽象化タグ及び助詞を特定する条件が規定された抽出フレーム定義を、対応語充填済みの格スロットに適用し、文の主語、述語、目的語に該当する情報要素を抽出する情報抽出処理部22を備えた情報抽出システム10。
(もっと読む)
株価影響企業検知システム及びプログラム
【課題】株価に影響を与えるイベントの有無を自動的に検知すると共に、このイベントによって株価に影響を受ける具体的な企業名を提示可能な技術の実現。
【解決手段】イベント情報を格納するイベント情報記憶部38と、各企業の属性情報を登録しておくオントロジ記憶部42と、イベントの属性と当該イベントによって株価に影響を受ける企業の属性との組合せパターン毎に、株価に与える影響がプラスかマイナスかを定義した推論ルールを格納する推論ルール記憶部40と、各イベント情報に対して推論ルールを適用し、当該イベントによって株価に影響が及ぶ企業の属性を特定すると共に、オントロジ記憶部42を参照して当該属性を備えた企業を株価影響企業として抽出し、株価影響企業のリストを生成してWebサーバ44に出力する株価影響企業抽出部26を備えた株価影響企業検知システム10。
(もっと読む)
FAQ候補抽出システムおよびFAQ候補抽出プログラム
【課題】話し言葉やノイズといった談話データの特性に強く、談話の文章構造の枠組みを規定せずに、談話データの構造を解析した結果からQ&A対を抽出するFAQ候補抽出システムを提供する。
【解決手段】談話データ101および談話セマンティクス200を入力とし、談話データ101からFAQ候補300となる質問−回答対を抽出して出力するFAQ候補抽出システム1であって、談話セマンティクス200は各ステートメントのフロー情報21を含み、質問文であることを示すフローが設定された第1のステートメントを同定し、さらに第1のステートメントの後に最初に現れ、かつ話者が異なり、談話に固有の事項について具体的な内容を述べているものであることを示すフローが設定された第2のステートメントを同定し、第1のステートメントと第2のステートメントとを質問−回答対として抽出するQ&A対抽出部60を有する。
(もっと読む)
談話要約生成システムおよび談話要約生成プログラム
【課題】話し言葉やノイズといった談話データの特性に強く、談話データの構造を解析した結果から、所望の項目や内容が含まれる形で要約を生成する談話要約生成システムを提供する。
【解決手段】談話データ101および談話構造の解析結果である談話セマンティクス200を入力とし、談話についての要約を生成して出力する談話要約生成システム1であって、要約の項目および記載内容を規定し、記載内容の一部または全部をプレースホルダとして指定した要約テンプレートと、プレースホルダを置換する内容を、談話セマンティクス200に基づいて特定するためのルールを指定したマッピングルール72と、要約テンプレート74の各プレースホルダに対して、マッピングルールの指定内容に従って、談話データ101における対応する内容の文字列を取得して、プレースホルダを取得した文字列によって置換して要約300を生成する談話要約部70とを有する。
(もっと読む)
用語間の対応関係抽出システム及び対応関係抽出プログラム
【課題】テキストデータに基づいて各企業の商品名を抽出し、対応する製品分類に自動的に関連付ける技術を提供する。
【解決手段】一般名称としての製品分類を複数格納した製品分類辞書16と、入力されたテキスト文を形態素単位に分解すると共に、製品分類辞書16を参照し、各形態素の中で製品分類に該当するものに対して対応のタグを付する形態素解析処理部12と、タグを含む文字列パターンと、この文字列パターン中からタグを付された製品分類に属する具体的商品名として抽出すべき文字列の位置とを規定する抽出ルールを、複数格納しておく抽出ルール記憶部18と、テキスト文の中の抽出ルールにマッチする文字列パターン中の所定の位置に存する文字列をタグが付された製品分類に属する商品名として抽出し、この製品分類と商品名との組合せを関係情報記憶部20に格納する関係情報抽出部14とを備えた用語間の対応関係抽出システム10。
(もっと読む)
姓名による属性解析方法、プログラム及びシステム
【課題】会員情報として登録された名義データに基づいて、会員情報としては登録されていない当該会員の属性の判別を行う。
【解決手段】入力された名義データにつき、(1)予め記録されている苗字辞書との前方一致検索、(2)予め記録されている名前辞書との後方一致検索、及び(3)予め定義された特徴情報の該当判別を順次行う。(1)(2)において一致が存在すれば対象と判定して処理を終了する。(1)(2)に該当しなかった場合(3)の判別を行い、その結果に応じて対象/対象外を判定する。
(もっと読む)
自然言語処理装置及びプログラム
【課題】固有名詞の換喩表現の抽出精度の向上を図ること。
【解決手段】自然言語処理装置は、所与の固有名詞又は所与の固有名詞と同格の語、を主語とし、且つ、動詞リストに記憶される、固有名詞の換喩表現である語を目的語とする文に用いられ得る動詞を含む文を検索する文検索部20と、文検索部20により検索された文に含まれる、動詞リストの動詞の目的語を取得する目的語取得部22と、目的語取得部22により取得された目的語を上記所与の固有名詞の換喩表現として辞書に登録する登録部24と、を含む。
(もっと読む)
抽出規則作成システム、抽出規則作成方法及び抽出規則作成プログラム
【課題】指定された位置に対応する情報と同等の概念を有する情報を効率よく抽出可能な抽出規則を作成できる抽出規則作成システムを提供する。
【解決手段】組合せ位置情報作成手段81は、タグ付きテキストと、文字列またはタグの位置を示す3個以上の位置情報と、キー情報とをもとに組合せ位置情報を作成する。単語タグ文字列作成手段82は、その組合せ位置情報に含まれる位置情報が示す位置の単語またはタグを組み合わせた単語タグ文字列をその組合せ位置情報ごとに作成する。単語タグ文字列選択手段83は、評価値を算出して単語タグ文字列を選択する。付属文字列抽出手段84は、タグ付きテキストを文節ごとに分割した単語のうち、位置情報が示す位置の文字列を含む文節分割単語を抽出し、その文節分割単語から、位置情報が示す位置に含まれない付属文字列を抽出する。抽出規則作成手段85は、単語タグ文字列と付属文字列とをもとに抽出規則を作成する。
(もっと読む)
抽出規則作成システム、抽出規則作成方法及び抽出規則作成プログラム
【課題】ユーザが欲する情報を抽出するための規則を効率よく作成する抽出規則作成システムを提供する。
【解決手段】抽出規則作成手段82は、タグ付きテキスト及びそのタグ付きテキスト中の文字列の位置を示す情報である文字列位置情報が与えられたときに、その文字列位置情報が示す位置に対応する単語又はタグと、その単語又はタグの前後の単語又はタグとを組み合わせて、タグ付きテキストから情報を抽出するための規則である抽出規則を作成する。適合文位置情報抽出手段83は、タグ付きテキスト記憶手段81に記憶されたタグ付きテキストごとに、抽出規則に適合する単語又はタグを含む適合文の位置を示す情報である適合文位置情報を抽出する。評価値算出手段84は、1つのタグ付きテキスト内に現れる適合文がより少ないほど評価値を高く算出し、より多くのタグ付きテキスト内に適合文が現れるほど評価値を高く算出する。
(もっと読む)
語句抽出ルール生成装置、語句抽出システム、語句抽出ルール生成方法、及びプログラム
【課題】学習データが意味的に類似するクラスを含む場合、及びそうでないクラスを含む場合のいずれであっても、語句のクラスを正しく分類可能な抽出ルールを学習し得る、語句抽出ルール生成装置、語句抽出ルール生成方法、及びプログラムを提供する。
【解決手段】語句抽出ルール生成装置2は、特徴量とクラス情報とを含む学習データから、特定のクラスの語句を抽出するための語句抽出ルールを生成する装置である。語句抽出ルール生成装置2は、特徴量の種類と、特徴量の種類別に付与されている特徴量の重みとによって予め設定された各クラスの定義を用いて、学習データの特徴空間を変換する特徴空間変換部20と、特徴空間変換部20によって特徴空間が変換された学習データから語句抽出ルールを学習する、抽出ルール学習部21とを備えている。
(もっと読む)
1 - 20 / 79
[ Back to top ]