
Fターム[5B091AB17]の内容
Fターム[5B091AB17]に分類される特許
1 - 20 / 144
情報表示装置及びプログラム
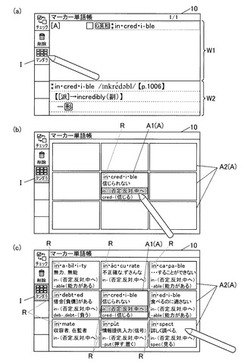
【課題】語源の共通する同語源単語を効率良く学習することを可能とする。
【解決手段】電子辞書1は表示部40と、語源付き辞書データベース821と、語源付き辞書データベース821に記憶された何れかの単語を指定する入力部30と、CPU20とを備える。CPU20は、指定単語に含まれる各単語構成部分と同じ語源の単語構成部分を含む単語を、語源付き辞書データベース821により記憶された単語の中から同語源単語として抽出し、指定単語及び同語源単語を表示部40に一覧表示させるとともに、当該指定単語と当該同語源単語の双方に共通して含まれる単語構成部分を識別表示させる。
(もっと読む)
自然言語処理装置、自然言語処理方法及び自然言語処理プログラム

【課題】本発明の実施形態が解決する課題は、複数の形態素単位で同義語変換を行なう自然言語処理装置を提供することである。
【解決手段】
実施形態の自然言語処理装置は、同義語と同義語変換対象語とが対応付けられた同義語辞書を記憶する記憶部と、文書データを形態素解析する形態素解析部と、形態素解析の結果と同義語辞書とを用いて、形態素解析の結果に含まれる形態素のうち、連続する複数の形態素が同義語変換対象語と一致するかを判定し、一致すると判定した同義語変換対象語を対応する同義語に変換する同義語変換部と、を備える。
(もっと読む)
単語属性推定装置及び方法及びプログラム
【課題】 他の単語データを利用して、属性が未知である単語に対し、付与すべき属性を推定する。
【解決手段】 本発明は、入力単語と共起する単語のパターンを特徴パターンとして抽出し、入力された単語共起データから特徴パターンと合致する共起語を入力単語の同類語候補として抽出し、入力単語及び各同類語に対し、共起する単語のパターンを特徴パターンとして抽出し、その特徴パターンを要素とし、その共起頻度を値とするベクトルを作成する。入力単語と各同類語候補との関連度を算出し、関連度の高いものを同類語として抽出する。同類語のカテゴリの重複数を調べて、重複数が多いカテゴリを入力単語のカテゴリとして推定し、当該カテゴリを属性として付与した単語を属性付単語として出力する。
(もっと読む)
コーパス変換装置、コーパス変換方法、およびプログラム
【課題】大規模な書き言葉コーパスを相槌を含む大規模なコーパスに変換すること。
【解決手段】コーパス変換装置100は、相槌を含む学習コーパス10の文を取得する学習コーパス取得部110と、コーパス取得部110で取得した文に基づいて、文長毎に、文中の各位置の相槌の出現確率を算出する出現位置確率算出部120と、算出した出現確率を文長および文中の位置に対応つけて記憶する出現位置確率記憶部130と、学習コーパス取得部110で取得した文に基づいて、相槌の種別毎に、文中の各位置の相槌の出現確率を算出する出現種別確率算出部140と、算出した出現確率を相槌の種別および文中の位置に対応つけて記憶する出現種別確率記憶部150と、出現位置確率記憶部130と出現種別確率記憶部150とに基づいて、大規模コーパス30の文に相槌を挿入し、相槌を含む大規模なコーパスを構築する変換手段と、を備える。
(もっと読む)
多義語抽出システム、多義語抽出方法、およびプログラム
【課題】情報システム構築に関する提案書や仕様書といった特定の案件に関する文書群で一般的な意味と異なる意味を有して使用されている多義語を判別してその文章の曖昧さを改善する。
【解決手段】多義語抽出システムとして、入力を受けた所定の文章中の各単語を抽出する単語分析部と、任意の単語を基軸単語として選択し、該基軸単語と共起関係とみなされる基軸単語共起語とその共起数とで表される基軸単語共起ベクトルを抽出する基軸単語共起ベクトル抽出部と、基軸単語共起ベクトルの各基軸単語共起語の共起語概念を一般概念から推定する共起語概念推定部と、推定した共起語概念群について、対応する共起語概念間の類似性に基づき、選択した基軸単語に関する各基軸単語共起語のクラスタリングを行う共起語分類部と、複数のクラスタが存在した際に多義語候補として抽出する多義語候補推定部と、抽出した候補を出力する多義語候補出力部とを設ける。
(もっと読む)
同義語抽出システム、方法およびプログラム
【課題】情報システム構築に関する提案書や仕様書等、所定の案件に関する文書で、意義は同じで語形が異なる同義語のある文章の曖昧さを改善する。
【解決手段】文章に使用されている各単語毎の品詞や格、組み合される助詞、単語間の係り受け関係に関する単語情報の抽出を行う単語分析部と、任意の単語を基軸単語として選択し、基軸単語と共起関係にある共起語とその共起数に基づく基軸単語共起ベクトルを全基軸単語についてまとめた基軸単語共起表を作成する基軸単語共起表作成部と、単語の一般概念情報を概念データベースに問い合わせ、各基軸単語共起ベクトルの各共起語を概念に変換した基軸単語概念ベクトルを全基軸単語についてまとめた基軸単語概念表を作成する単語概念推定部と、各基軸単語概念ベクトル間の類似性を判定し、類似性が高い基軸単語の組合せを同義語候補として抽出する同義語候補推定部と、同義語候補を出力する同義語候補出力部とを備える。
(もっと読む)
同義語辞書生成装置、その方法、及びプログラム
【課題】文書テキストだけではなく音声テキストに基づいても、精度の高い同義語辞書を作成することができる同義語辞書生成技術を提供する。
【解決手段】同義語辞書を作成する際に基準となる基準語彙を含む文脈と、基準語彙に関連する関連語彙を含む文脈の類似性を算出し、基準語彙の表記と関連語彙の表記の類似性を算出し、基準語彙の読みと関連語彙の読みの類似性を算出し、算出された文脈、表記及び読みの類似性を用いて基準語彙及び関連語彙についての同義指標を求め、その同義指標の大きさに基づき関連語彙が基準語彙の同義語であるか否かを判定する。
(もっと読む)
辞書管理装置、辞書管理方法、辞書管理プログラム
【課題】オンライン辞書について辞書管理の負担を軽減させた高品質な類似検索機能を提供する。
【解決手段】類似検索部3は、辞書管理者の入力表記に基づき全体辞書を検索し、入力表記に類似する表記を特定する。主要部特定部4は、類似検索手段で特定された類似表記と入力表記との共通部分を特定し、特定された共通部分が主要部辞書に存在すれば、該共通部分を主要部候補と判定する。この主要部候補を類似表記から除外した付加部候補が付加部辞書に存在するか否かを判定し、判定結果に応じて主要部候補を主要部と確定する。距離算出部5は、確定された各類似表記の主要部と入力表記の主要部との編集距離を算出する。更新確認部6は、算出された編集距離順に類似表記・主要部・付加部を辞書管理者に提示する。
(もっと読む)
商品名同一性判定装置および商品名同一性判定プログラム
【課題】商品名の記載において特徴的に出てくる販売促進目的の語句を考慮した商品名の同一性判定を行うことができる商品名同一性判定装置を提供する。
【解決手段】商品名表記ペア110を入力とし、商品名情報が蓄積された商品表記データベース120中に含まれる語句それぞれに対して、特定の商品を識別するのに有用な語句に対して高い値となり、複数の商品に含まれる語句に対して低い値となる商品スコアを算出し、商品スコアデータベース150に蓄積する商品スコア算出手段140と、商品名表記ペア110を解析して、それぞれの商品名表記に含まれる語句の共通部分と差異部分を取得し、前記データベース150にアクセスして前記語句の商品スコアを取得し、前記共通して出現する語句の商品スコアが高く、片側のみに出現する語句の商品スコアが低い場合に、入力された商品名表記ペア110は同一性が高いと判定する同一性判定手段と、を備える。
(もっと読む)
要求文書分析システム、方法およびプログラム
【課題】情報システム構築の上流工程に用いられる要求関連文書の曖昧さを改善すること。
【解決手段】情報システム構築の上流工程に用いられる要求関連文書に含まれる曖昧ポイントについて、要求関連文書に特有の評価基準に基づく曖昧性の優先順位を付け、誤った係り受けを行う可能性の高い曖昧ポイントに絞り込んで曖昧ポイントを提示することで、情報システム構築の上流工程に用いられる要求関連文書の曖昧さを改善する。
(もっと読む)
文書処理装置およびプログラム
【課題】類義語として適切な用語を文書から抽出することが可能な文書処理装置およびプログラムを提供することにある。
【解決手段】用語抽出手段は、文書格納手段に格納されている複数の文書から第1および第2の用語を抽出する。クラスタ生成手段は、複数の文書の各々が属するクラスタを生成する。特徴度算出手段は、複数の文書および生成されたクラスタに属する文書における第1の用語の出現頻度に基づいて当該クラスタに対する第1の用語の特徴度を算出し、複数の文書およびクラスタ生成手段によって生成されたクラスタに属する文書における第2の用語の出現頻度に基づいて当該クラスタに対する第2の用語の特徴度を算出する。類義語抽出手段は、算出された類似度、算出された第1の用語の特徴度および第2の用語の特徴度に基づいて当該第1および第2の用語を類義語として抽出する。
(もっと読む)
機械翻訳装置、方法およびプログラム
【課題】翻訳結果を得るまでの時間を短縮できるとともに、信頼度の高い機械翻訳結果を得ることができる機械翻訳装置を提供する。
【解決手段】言い換え文生成手段81は、入力されたテキスト文と同一の言語でそのテキスト文の内容を示す別の表現へ言い換えた1つまたは複数の言い換え文を生成する。機械翻訳手段82は、言い換え文を翻訳後の言語である目的言語へと機械翻訳する。翻訳信頼度決定手段83は、目的言語へ翻訳された言い換え文の信頼度を示す翻訳信頼度を決定する。言い換え文特定手段84は、言い換え文生成手段81が生成した言い換え文の中から、翻訳信頼度に基づいて言い換え文の候補を抽出し、候補の中から翻訳の対象とする言い換え文である翻訳対象言い換え文を特定する。
(もっと読む)
同義語判定装置、同義語判定方法およびプログラム
【課題】文書を収集せずに同義語を判定する。
【解決手段】ユーザが端末装置10に入力したキーワードの検索結果は、検索サーバ装置30から端末装置10へ送られる。端末装置10において、検索結果として表示されたリンクがクリックされると、ユーザが入力したキーワードと、キーワードに関連するWebページのアドレスが同義語判定装置40に送られ、ログとして記憶される。同義語判定装置40は、キーワードとアドレスの組の中から、キーワードが異なるものの対となっているアドレスが同じである組を選び、選んだ各組のキーワードの類似度を各組のログにおける登場回数を基に計算する。同義語判定装置40は、類似度が閾値以上の場合、各組のキーワードが同義語であるとし、ログにおいて記憶されている数の多い方を正表記語、記憶されている数が少ない方を同義語として記憶する。
(もっと読む)
類義性尺度用パラメタ学習装置およびそのプログラム、並びに、類義性尺度計算装置
【課題】本発明は、正解データの作成コストを低減でき、正確性が高い類義性尺度を計算可能なパラメタを学習する類義性尺度用パラメタ学習装置を提供する。
【解決手段】類義性尺度学習装置100は、対訳コーパスを用いて、後記する類義関係単語対一覧および非類義関係単語対一覧を正解データとして作成する正解データ作成装置1と、正解データ作成装置1が作成した類義関係単語対一覧および非類義関係単語対一覧を用いて、単語間の類義性尺度を算出するためのパラメタを学習するパラメタ学習装置3と、パラメタ学習装置3が学習したパラメタを用いて、類義性尺度を計算する類義性尺度計算装置5とを備える。
(もっと読む)
同義語辞書生成装置、データ解析装置、データ検出装置、同義語辞書生成方法及び同義語辞書生成プログラム
【課題】異なる複数の文章に含まれる単語を用いて同義語を検出することが可能であって、汎用性を有し、幅広く同義語を定義することが可能な同義語辞書生成装置等を提供する。
【解決手段】文書解析システム100は、入力インターフェース110を介して取得した各アンケートデータに対して、評価表現を示す評価表現テキストと当該評価テキストが修飾する被修飾語テキストのセットをテキストセットとして抽出しつつ、評価表現テキスト、カテゴリ情報及び被修飾語テキストの出現頻度数に基づいて同義語を定義するようになっている。
(もっと読む)
上位概念出力プログラム及び上位概念出力装置
【課題】対象とする語句が見出し語となっている概念が概念辞書中に存在しない場合において、対象とする語句の上位概念を出力する上位概念出力プログラム及び上位概念出力装置を提供する。
【解決手段】上位概念出力装置1は、語句を受け付ける表現受付手段100と、表現受付手段100により受け付けられた語句と関連する語句との関連度を計算し、当該関連度に基づいて関連する語句から関連語を検索する関連語検索手段101と、概念辞書111に基づいて、関連語を見出し語として持つ概念を抽出し、抽出された概念の上位概念を概念辞書111に基づいて抽出し、関連語と上位概念とこれらの概念の繋がりとから構成される部分木20を作成する部分木作成手段102と、概念の繋がりの形態に対応付けられた係数基づいて、関連度から上位概念のスコアを計算する関連度計算手段103と、上位スコアを有する上位概念を出力する概念出力手段104とを有する。
(もっと読む)
類似度算出装置、類似度算出方法、及びプログラム
【課題】文脈ベクトルの値が不確実であるという事実を考慮した適切な意味的類似度を算出する類似度算出装置を提供する。
【解決手段】意味的類似度の算出の対象となる第1の言語表現w1及び第2の言語表現w2を受け付ける受付部11、コーパスにおける第1の言語表現w1の出現に関する情報である第1の文脈ベクトルと、コーパスにおける第2の言語表現w2の出現に関する情報である第2の文脈ベクトルとを取得する取得部13、2個の文脈ベクトルφ1、φ2の類似度を計算する類似関数g(φ1、φ2)と、第1及び第2の文脈ベクトルからベイズ推定を用いて得られた確率分布とを用いて、第1の言語表現に対応する文脈ベクトルと、第2の言語表現に対応する文脈ベクトルとの類似度の期待値である意味的類似度を算出する算出部14、算出された意味的類似度を出力する出力部15を備える。
(もっと読む)
プログラムおよび情報処理装置
【課題】評価を表す表現について関連性の高い表現の候補を正確に特定する。
【解決手段】情報処理装置10が備える評価表現辞書114は、評価対象を評価するための評価項目を表す語と当該評価項目に対する評価値を表す語とを含む評価表現と、当該評価表現が肯定的な表現であるか否かを表す極性と、を関連付けて記憶する。評価表現抽出部130は、評価表現辞書114を参照し、処理対象の文字列に含まれる評価表現を処理対象の文字列から抽出し、抽出した評価表現それぞれの極性を特定する。評価表現分類部140は、抽出された評価表現の間で評価対象および極性が共通するか否かに基づいて、前記抽出された評価表現を1以上のグループに分類する。出力処理部170は、同一のグループに分類された評価表現が複数ある場合に、これら複数の評価表現を互いに関連付けて関連表現記憶部180に対して出力する。
(もっと読む)
プログラム及び同義語生成装置
【課題】文又は節に含まれる主語と述語の組合せと同義の、接頭辞付きの単語を生成する。
【解決手段】接頭辞・述語表現対照表20は、接頭辞ごとに、接頭辞の意味を表す述語表現のリストを有する。構文意味解析部12は、対象文入力部10に入力された対象文に対して構文意味解析を実行し、主語と述語の組を抽出する。単語候補生成部14は、抽出された述語に対応する接頭辞を接頭辞・述語表現対照表20から求め、求めた各接頭辞をその主語に連結することで、主語と述語の組と同義である単語の候補を生成する。同義語判定部16は、生成された候補の中から、標準辞書22の語彙に含まれるものを選別し、これをその主語と述語の組に対応する接頭辞付き同義語として出力する。
(もっと読む)
感性辞書編集支援システム及びプログラム
【課題】自然文からユーザの価値判断が示されている表現を抽出する際に参照する感性辞書を効率的に編集できるように支援する技術の実現。
【解決手段】事物に対する肯定/否定の価値判断を表す感性用語と、肯定/否定の何れであるかを示す極性との組合せを格納しておく感性辞書記憶部18と、複数の用語について、各用語の類義語を定義したデータが格納された類義語辞書記憶部34と、起点語が入力された場合に、この起点語をキーに類義語辞書記憶部34を検索して起点語の類義語を抽出し、各類義語をキーに類義語辞書記憶部34を検索して各類義語の類義語を抽出し、抽出された用語のリストを含む感性用語登録画面80を生成してクライアント端末58に送信し、この画面80を介してリスト中の1または複数の用語を選択する情報と、各用語の極性を指定する情報が入力された場合に、選択された用語を指定された極性に関連付けて感性辞書記憶部18に格納する辞書編集支援部38を備えた。
(もっと読む)
1 - 20 / 144
[ Back to top ]