
Fターム[5B091CA02]の内容
Fターム[5B091CA02]の下位に属するFターム
最長一致法 (1)
Fターム[5B091CA02]に分類される特許
1 - 20 / 352
形態素の構成文字種を利用して文書の対象者を判定する情報処理装置及びプログラム
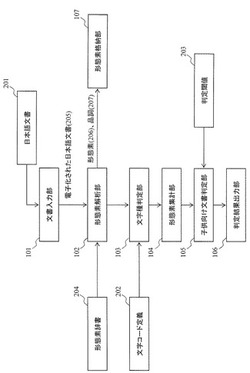
【課題】日本語で記述された文書を、その記述形態に依存することなく、文書の対象者(例えば子供向けか大人向けか)を判定できるようにする。
【解決手段】日本語で記述された文書を形態素で分割する。次に、各形態素を平仮名のみで構成される形態素と平仮名以外を含む形態素に分類し、各分類の出現頻度を集計する。その後、平仮名のみで構成される形態素の出現割合に基づいて、前記文書の対象者を判定する。
(もっと読む)
自然言語処理装置、自然言語処理方法及び自然言語処理プログラム

【課題】本発明の実施形態が解決する課題は、複数の形態素単位で同義語変換を行なう自然言語処理装置を提供することである。
【解決手段】
実施形態の自然言語処理装置は、同義語と同義語変換対象語とが対応付けられた同義語辞書を記憶する記憶部と、文書データを形態素解析する形態素解析部と、形態素解析の結果と同義語辞書とを用いて、形態素解析の結果に含まれる形態素のうち、連続する複数の形態素が同義語変換対象語と一致するかを判定し、一致すると判定した同義語変換対象語を対応する同義語に変換する同義語変換部と、を備える。
(もっと読む)
意味ラベル付与モデル学習装置、意味ラベル付与装置、意味ラベル付与モデル学習方法、及びプログラム
【課題】会話の流れによって疑問表現になったり、断定表現になったりする述部の機能表現に対しても、適切な意味ラベルを付与する。
【解決手段】学習用発話対作成部22で、形態素解析結果に対して、機能表現及び応対表現の正解ラベルが付与された正解コーパスに基づいて、学習用発話対を作成する。パラメータテーブルに、素性として、発話対の前の発話の終わりに表れる機能表現の意味ラベルと、それに対する後の発話の初めに表れる応対表現の意味ラベルとの並びの素性を用い、複数種類の素性各々について、重みの初期値を設定する。パラメータテーブル作成部24で、発話対の形態素情報と機能表現辞書30とを用いて、各形態素について候補となる意味ラベルを全て含んだラティスを構築し、ラティス構造からパラメータテーブルの素性毎の重みに基づいて最尤パスとして探索する。最尤パスが正解の意味ラベル列となるようにパラメータテーブルの重みを学習する。
(もっと読む)
テキストセグメンテーション装置及び方法及びプログラム及びコンピュータ読取可能な記録媒体
【課題】学習データを必要とせずにテキストセグメンテーションが可能なWeb検索を利用したテキストセグメンテーションを実現する。
【解決手段】本発明は、入力されたテキストを文単位に分割し、分割された文を形態素解析し、形態素解析された助詞を除く全ての単語を検索語として抽出し、活用形のある単語を終止形に変換し、検索語に基づいてウェブ検索し、検索されたテキストを形態素解析し、助詞を除く全ての単語を関連語として抽出し、活用形のある単語を終止形に変換し、検索語と関連語記憶手段に格納されている関連語との組み合わせであるキーワード集合を用いて、文同士の連結性に基づいて意味段落を求め、分割候補を作成し、分割候補を評価して一つの分割結果を選択して出力する。
(もっと読む)
テキストセグメンテーション装置及び方法及びプログラム及びコンピュータ読取可能な記録媒体
【課題】学習データを必要とせずにテキストセグメンテーションが可能なWeb検索を利用したテキストセグメンテーションを実現する。
【解決手段】本発明は、入力されたテキストを文単位に分割し、分割された文を形態素解析し、形態素解析された名詞、副詞、動詞、形容詞、形容動詞を検索語として抽出し、検索語に基づいてウェブ検索したテキストを形態素解析し、解析された形態素のうちで、名詞、副詞、動詞、形容詞、形容動詞を関連語として取得し、検索語と関連語との組み合わせであるキーワード集合を用いて、入力テキストを分割した複数の文同士の連結性を判定し、該連結性の谷と谷の間にある文同士である意味段落を抽出することによって入力テキストを分割する。
(もっと読む)
形態素解析装置、方法、プログラム、音声合成装置、方法、プログラム
【課題】解析対象のテキスト上で隣接し、単語辞書に分けて登録された名詞類の単語の組の読みの解析精度を向上させる。
【解決手段】第1単語辞書18には形態素解析の解析精度を考慮して選択された単語が登録され、第2単語辞書20には第1単語辞書18に未登録の単語が追加登録される。単語連接可能性判定部16は、学習用テキストコーパス34に含まれるテキスト上で、「の」等の特定単語を挟んでその前後に存在している名詞類の単語で、一方が第2単語辞書20に登録された単語の組を単語連接可能性テーブル24に登録し、前記単語の組と第1単語辞書18に登録された単語が相違する別の単語の組に対する減点値も算出・登録する。形態素解析部14は解析対象テキスト32の形態素解析にあたり、解析対象テキスト32上で隣接する名詞類の単語の組で、一方が第2単語辞書20に登録され、単語連接可能性テーブル24に登録されていない単語の組の接続評価値から前記減点値を減算する。
(もっと読む)
情報処理装置及びプログラム
【課題】解析対象となる単語列において、ある単語と単語との間で単語列が区切れる確からしさを求めるために必要な教師データ量が少ない情報処理装置及びプログラムを提供する。
【解決手段】単語列取得部410が解析対象となる単語列を取得すると、判別部420が教師データ記憶部4730にその単語列を含む教師データが十分に記憶されているか否か判別する。そして、教師データが十分でないと判別すると、(n−1)グラム生成部430が、単語列の部分列である(n−1)グラムを生成する。(n−1)グラム生成部430が生成した部分列のそれぞれについて、確率係数取得部440がその単語列の単語と単語との間である語間のそれぞれで、単語列が区切れる確からしさを示す確率係数を取得し、取得した確率係数から確率係数算出部450が単語列の確率係数を算出する。
(もっと読む)
形態素解析装置、方法、プログラム、音声合成装置、方法、プログラム
【課題】解析対象のテキスト上で隣接し、単語辞書に分けて登録された名詞類の単語の組の読みの解析精度を向上させる。
【解決手段】第1単語辞書18には形態素解析の解析精度を考慮して選択された単語が登録され、第2単語辞書20には第1単語辞書18に未登録の単語が追加登録される。単語連接可能性判定部16は、学習用テキストコーパス34に含まれるテキスト上で、「の」等の特定単語を挟んでその前後に存在している名詞類の単語で、一方が第2単語辞書20に登録された単語の組を単語連接可能性テーブル24に登録する。形態素解析部14は解析対象テキスト32の形態素解析にあたり、解析対象テキスト32上で隣接する名詞類の単語の組で、一方が第2単語辞書20に登録され、単語連接可能性テーブル24に登録されていない単語の組を接続不可と判定する。
(もっと読む)
情報処理装置およびプログラム
【課題】第1言語および第2言語で記述されたテキストと、フレーズが第1言語で記述された場合の語の位置と、第2言語で記述された場合の語の位置と、の対応関係を示す情報と、に基づいて、第1テキストの一部の翻訳テキストを決定する情報処理装置を提供する。
【解決手段】情報処理装置100は、第1言語および第2言語のテキストを取得するテキストデータ取得部122と、フレーズが第1言語で記述された場合の語の位置と、フレーズが第2言語で記述された場合の語の位置と、の対応関係を示す情報を取得する文パターン候補検索部124と、テキストを複数のサブテキストに区切る形態素解析部123と、フレーズにおける語の配置と、テキストにおけるサブテキストの配置と、を比較する文パターンマッチング部125と、比較の結果と位置対応情報とに基づいて、翻訳テキストを決定する単語アライメント抽出部129と、を有する。
(もっと読む)
自然言語処理装置、自然言語処理方法および自然言語処理プログラム
【課題】解析対象となる文書の言語およびドメインを考慮して、その文書に適した解析器を作成する自然言語処理装置を提供する。
【解決手段】自然言語処理装置100は、対訳記憶手段と対訳検索手段と単語抽出手段と正解作成手段と解析器生成手段とを備える。対訳記憶手段は、未知言語の文書と一又は複数の既知言語の文書とからなる複数の対訳文書、およびそのドメインを記憶する。対訳検索手段は、ドメインを指定して、対訳記憶手段から対訳文書を検索する。単語抽出手段は、対訳検索手段で検索された対訳文書から、未知言語の単語と既知言語の単語とを対応付けた単語ペアを抽出する。正解作成手段は、単語ペア、および検索された対訳文書における既知言語の文書の解析結果を用いて、検索された対訳文書における未知言語の文書の解析結果を推定する。解析器生成手段は、未知言語の文書の解析結果を用いて、未知言語の解析器を生成する。
(もっと読む)
FAQ作成支援システム及びプログラム
【課題】FAQ作成支援システムを提供する。
【解決手段】実施形態のFAQ作成支援システムは、問合せ代表文(問合せ文とその回答文を含む文書の文書集合において各文書それぞれの問合せ文から抽出される複数の問合せ代表文のうち同一の問合せ代表文に基づいて、一の問合せ代表文に複数の抽出元の問合せ文に対応する文書が関連付けられた文)と、回答代表文(各文書それぞれの回答文から抽出される複数の回答代表文のうち同一の回答代表文に基づいて、一の回答代表文に複数の抽出元の回答文に対応する文書が関連付けられた文)との対を、問合せ代表文に関連付く各文書が回答代表文それぞれに関連付いている各文書とマッチングする文書数で評価し、問合せ代表文と回答代表文との対に基づくFAQの作成環境を提供する。
(もっと読む)
情報処理装置、プログラム、および翻訳テンプレート生成方法
【課題】構文構造が異なった対訳文対から翻訳テンプレートを生成できるようにする。
【解決手段】取得手段1aは、第1の言語文と第2の言語文とを取得する。分割手段1bは、取得した第1および第2の言語文それぞれを、複数の形態素に分割する。カウント手段1cは、取得した第1および第2の言語文から分割された各形態素の出現頻度をカウントする。検出手段1eは、取得した第1の言語文から出現頻度が2以上の形態素を検出し、該検出された形態素の第2の言語における訳語であり、出現頻度が1の形態素を、取得した第2の言語文から検出する。生成手段1fは、取得した第1および第2の言語文それぞれから検出された形態素を変数に置き換える置換処理を行い、該置換処理後の第1および第2の言語文を含む翻訳テンプレートを生成する。
(もっと読む)
辞書作成装置、辞書作成方法、およびプログラム
【課題】効率的に言語解析用の辞書を作成する辞書作成装置等を提供する。
【解決手段】未知語判定プログラム25は、記憶部から書籍のOCRデータを入力し、書誌情報データベース21と照合して作者及びジャンルを特定するとともに、処理対象の語句が、未知語か否かを判定する。未知語の語句については、辞書登録プログラム26に処理を引き渡す。辞書登録プログラム26は、作者別辞書登録プログラム26A、ジャンル別辞書登録プログラム26Bを含み、作者別辞書データベース22、ジャンル別辞書データベース23、および標準辞書データベース24に未知語を登録する。
(もっと読む)
複合語概念分析システム、方法およびプログラム
【課題】専門領域での複合語の多い文書中の複合語の概念を推定すること。
【解決手段】複合語を構成語に分割し、同一の構成語を持つ複合語間の共起ベクトルの距離に基づく集約度を構成語支配度として算出し、構成語支配度に基づき各構成語の概念に重み付けを行った合成概念として未知の複合語の概念を抽出することで、専門領域での複合語の多い文書中の複合語の概念を推定する。
(もっと読む)
解析モデル学習装置、方法、及びプログラム
【課題】計算コストの増大を抑制しつつ、高精度な分類精度を得られる解析モデルを学習する。
【解決手段】ベースライン解析部2で、解析対象、基本特徴量、及び正解を含む複数の訓練用サンプル各々に対して、解析結果の予測値を解析し、ルール候補作成部4で、解析誤りのある訓練用サンプルからルールテンプレート5に従って変換ルール候補を作成し、ルール選択部6で、変換ルール候補各々を適用した場合に、正味の正解増加数が最大となる変換ルール候補を選択し、ルール適用部8で、選択した変換ルールを全訓練用サンプルに適用し、解析誤りが0になるまでルールの生成及び適用を繰り返す。インデクス作成部10で、各訓練用サンプルに適用されたルールの履歴及び基本特徴量のインデクスを格納し、訓練ベクトル作成部12で、インデクスに基づいて訓練ベクトルを作成し、学習部14で、訓練ベクトルに基づいて解析モデルを学習する。
(もっと読む)
電子メール情報表示システムおよび電子メールクライアント
【課題】膨大な量の電子メールの中から、必要としている情報を迅速に探し出すことができる電子メール情報表示システムを提供する。
【解決手段】電子メール情報表示システムのクライアントPC101は、ヘッダ情報に基づき、任意の電子メールに対して、送信、受信、返信、および転送を含む電子メールの一連のやり取りの流れを構築し、表示する手段と、一連のやり取りの流れが構築された任意の電子メールを含んだ、一連のやり取りの流れに含まれる全ての電子メールに対して、本文に含まれる文章の各行に対し、引用符「>」の抽出と文章の形態素解析を行う手段と、その結果により、各電子メール本文に含まれるキーワード群と各キーワードに付与されていた引用符数を抽出し、電子メールの一連のやり取りの中での重要キーワードを決定する手段と、電子メールの一連のやり取りの流れと、当該重要キーワードとを表示する手段等を備える。
(もっと読む)
怒り感情推定装置、怒り感情推定方法およびそのプログラム
【課題】感情語辞書を事前に用意する必要がなく、怒り感情を頑健に推定可能とする。
【解決手段】対話テキストを話者別のテキストに分割する話者分割処理部11と、分割された話者別のテキストの形態素を解析し、各話者別のテキストを形態素単位に分割した形態素解析結果を出力する形態素解析処理部12と、形態素解析結果を用い、話者別のテキスト中の同じ内容語の出現頻度を表す指標である発話内容冗長性特徴量を、各話者別のテキストに対して求める発話内容冗長性特徴量抽出部13と、形態素解析結果を用い、話者別のテキスト中の内容語の出現頻度を表す指標である発話内容情報性特徴量を、各話者別のテキストに対して求める発話内容情報性特徴量抽出部14と、予め学習した感情識別器30を用い、発話内容冗長性特徴量及び発話内容情報性特徴量の少なくとも一方を用いて対話テキストの対話が怒り対話か否かを推定する感情識別部20とを具備する。
(もっと読む)
入力文の細部意味を表示する文作成支援自然文処理法。
【課題】入力自然文の意味を表現する意味構造を構築し、その意味構造を細分化し、その細分化した意味構造から自然文を生成し、自然文の細部の意味を提示する。
【解決手段】
入力自然文に形態素解析や構文解析を行い、その解析結果に意味構築処理を行って、部分的な意味構造を構築し、部分的な意味構造を意味根で結合しながら、入力自然文の全体の意味構造を構築する。その意味構造を意味根で細分化して、細分化した当該意味構造から自然文を生成して明示すると入力自然文の意味が細部にまで検証できる。
書き手は、文法と知識を用いて文を作成するが、読み手も書き手と同じ知識を共有するとはかぎらない。本発明では、知識を持たない読み手の立場に立ち、主に文法情報だけで意味解析する。それによって、知識を持たない読み手でも精確に理解できる文を書き手が作成できるように支援する。そのような文作成支援自然文処理法。
(もっと読む)
述部正規化装置、方法、及びプログラム
【課題】単純かつ文法的に正しい述部の言い換えを行う。
【解決手段】形態素解析結果に対して、機能表現に意味ラベルを付与すると共に、述部を抽出し、意味ラベル「NULL」の機能表現の削除、同一の意味ラベルの機能表現の1つ以外を削除した後、Ngram文法性判断部22の候補生成部22aで、周辺に存在する単語によって文法的な必要性が異なることを示す「Grammar」に属する意味ラベルが付与された機能表現を含む場合、除いた場合の全ての組み合わせについて、述部の形態素列の候補を生成し、Ngramスコア計算部22dで、機能語については形態素の表層形を要素とし、機能語以外の単語については表層形を要素としない形態素Ngramモデル22b、及び品詞Ngramモデル22cに基づいて、Ngramスコアを計算し、選択部22eでNgramスコアが最も高い形態素列を選択して、正規化した述部を出力する。
(もっと読む)
単語抽出装置、単語抽出方法及びプログラム
【課題】辞書を用いずに、テキストに頻出する単語を精度良く抽出する。
【解決手段】単語抽出装置1は、文字数が所定文字数以上の文字列であって、テキストに所定回数以上出現する文字列を対象文字列として前記テキストから抽出する対象文字列抽出部と、他の対象文字列の部分文字列であって、前記テキストにおいて前記他の対象文字列に包含される位置以外に出現する回数が前記所定回数より小さい文字列を前記対象文字列抽出部により抽出された対象文字列の集合から削除する第1の削除部と、前記第1の削除部により文字列を削除した後の対象文字列の集合に含まれる文字列を単語とする単語抽出部とを備える。
(もっと読む)
1 - 20 / 352
[ Back to top ]