
Fターム[5B091CA12]の内容
Fターム[5B091CA12]に分類される特許
1 - 20 / 324
意味ラベル付与モデル学習装置、意味ラベル付与装置、意味ラベル付与モデル学習方法、及びプログラム
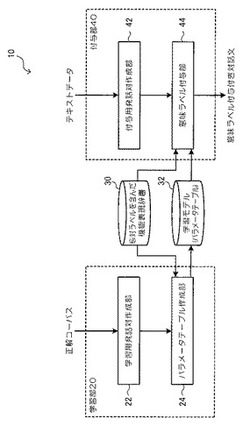
【課題】会話の流れによって疑問表現になったり、断定表現になったりする述部の機能表現に対しても、適切な意味ラベルを付与する。
【解決手段】学習用発話対作成部22で、形態素解析結果に対して、機能表現及び応対表現の正解ラベルが付与された正解コーパスに基づいて、学習用発話対を作成する。パラメータテーブルに、素性として、発話対の前の発話の終わりに表れる機能表現の意味ラベルと、それに対する後の発話の初めに表れる応対表現の意味ラベルとの並びの素性を用い、複数種類の素性各々について、重みの初期値を設定する。パラメータテーブル作成部24で、発話対の形態素情報と機能表現辞書30とを用いて、各形態素について候補となる意味ラベルを全て含んだラティスを構築し、ラティス構造からパラメータテーブルの素性毎の重みに基づいて最尤パスとして探索する。最尤パスが正解の意味ラベル列となるようにパラメータテーブルの重みを学習する。
(もっと読む)
単語属性推定装置及び方法及びプログラム

【課題】 他の単語データを利用して、属性が未知である単語に対し、付与すべき属性を推定する。
【解決手段】 本発明は、入力単語と共起する単語のパターンを特徴パターンとして抽出し、入力された単語共起データから特徴パターンと合致する共起語を入力単語の同類語候補として抽出し、入力単語及び各同類語に対し、共起する単語のパターンを特徴パターンとして抽出し、その特徴パターンを要素とし、その共起頻度を値とするベクトルを作成する。入力単語と各同類語候補との関連度を算出し、関連度の高いものを同類語として抽出する。同類語のカテゴリの重複数を調べて、重複数が多いカテゴリを入力単語のカテゴリとして推定し、当該カテゴリを属性として付与した単語を属性付単語として出力する。
(もっと読む)
テキストセグメンテーション装置及び方法及びプログラム及びコンピュータ読取可能な記録媒体
【課題】学習データを必要とせずにテキストセグメンテーションが可能なWeb検索を利用したテキストセグメンテーションを実現する。
【解決手段】本発明は、入力されたテキストを文単位に分割し、分割された文を形態素解析し、形態素解析された助詞を除く全ての単語を検索語として抽出し、活用形のある単語を終止形に変換し、検索語に基づいてウェブ検索し、検索されたテキストを形態素解析し、助詞を除く全ての単語を関連語として抽出し、活用形のある単語を終止形に変換し、検索語と関連語記憶手段に格納されている関連語との組み合わせであるキーワード集合を用いて、文同士の連結性に基づいて意味段落を求め、分割候補を作成し、分割候補を評価して一つの分割結果を選択して出力する。
(もっと読む)
テキストセグメンテーション装置及び方法及びプログラム及びコンピュータ読取可能な記録媒体
【課題】学習データを必要とせずにテキストセグメンテーションが可能なWeb検索を利用したテキストセグメンテーションを実現する。
【解決手段】本発明は、入力されたテキストを文単位に分割し、分割された文を形態素解析し、形態素解析された名詞、副詞、動詞、形容詞、形容動詞を検索語として抽出し、検索語に基づいてウェブ検索したテキストを形態素解析し、解析された形態素のうちで、名詞、副詞、動詞、形容詞、形容動詞を関連語として取得し、検索語と関連語との組み合わせであるキーワード集合を用いて、入力テキストを分割した複数の文同士の連結性を判定し、該連結性の谷と谷の間にある文同士である意味段落を抽出することによって入力テキストを分割する。
(もっと読む)
俳句公開サーバ、端末装置、コミュニケーションシステム、季語推薦方法、付け句生成方法、プログラム
【課題】付け句に適切な季語の候補を提示できるようにして、付け句の創作を有効に支援する。
【解決手段】俳句公開サーバは、端末装置からの推薦季語要求の受信に応じて、発句として指定された俳句を解析して季語、自立語、切れ字を抽出し、これらの抽出した語句を利用して、季語データベースから、付け句の制約を満たし、かつ、発句の内容に対応する季語を選択する。そして、このように選択した季語を推薦季語として推薦季語要求元の端末装置に送信する。端末装置は、付け句創作支援として、受信した推薦季語を表示してユーザに提示する。
(もっと読む)
FAQ作成支援システム及びプログラム
【課題】FAQ作成支援システムを提供する。
【解決手段】実施形態のFAQ作成支援システムは、問合せ代表文(問合せ文とその回答文を含む文書の文書集合において各文書それぞれの問合せ文から抽出される複数の問合せ代表文のうち同一の問合せ代表文に基づいて、一の問合せ代表文に複数の抽出元の問合せ文に対応する文書が関連付けられた文)と、回答代表文(各文書それぞれの回答文から抽出される複数の回答代表文のうち同一の回答代表文に基づいて、一の回答代表文に複数の抽出元の回答文に対応する文書が関連付けられた文)との対を、問合せ代表文に関連付く各文書が回答代表文それぞれに関連付いている各文書とマッチングする文書数で評価し、問合せ代表文と回答代表文との対に基づくFAQの作成環境を提供する。
(もっと読む)
文書分析補助装置及び方法及びプログラム
【課題】 ブログやチャット等の短い文書の文書解析における曖昧性を解消する。
【解決手段】 本発明は、テキスト及び時刻を含む文書情報とユーザ情報を取得し、該文書情報を文書情報記憶手段に格納し、ユーザ情報に基づいてマイクロブログサービスから関係ユーザ情報を取得し、関係ユーザ情報に基づいてマイクロブログサービスから文書情報の時刻の任意の期間範囲の関係文書情報を取得して、文書情報記憶手段に格納し、文書情報記憶手段に格納されている文書情報と関係文書情報を時刻順にソートして1文として結合した解析対象文書を生成する。その上で解析対象文書を解析する。
(もっと読む)
多義語抽出システム、多義語抽出方法、およびプログラム
【課題】情報システム構築に関する提案書や仕様書といった特定の案件に関する文書群で一般的な意味と異なる意味を有して使用されている多義語を判別してその文章の曖昧さを改善する。
【解決手段】多義語抽出システムとして、入力を受けた所定の文章中の各単語を抽出する単語分析部と、任意の単語を基軸単語として選択し、該基軸単語と共起関係とみなされる基軸単語共起語とその共起数とで表される基軸単語共起ベクトルを抽出する基軸単語共起ベクトル抽出部と、基軸単語共起ベクトルの各基軸単語共起語の共起語概念を一般概念から推定する共起語概念推定部と、推定した共起語概念群について、対応する共起語概念間の類似性に基づき、選択した基軸単語に関する各基軸単語共起語のクラスタリングを行う共起語分類部と、複数のクラスタが存在した際に多義語候補として抽出する多義語候補推定部と、抽出した候補を出力する多義語候補出力部とを設ける。
(もっと読む)
複合語概念分析システム、方法およびプログラム
【課題】専門領域での複合語の多い文書中の複合語の概念を推定すること。
【解決手段】複合語を構成語に分割し、同一の構成語を持つ複合語間の共起ベクトルの距離に基づく集約度を構成語支配度として算出し、構成語支配度に基づき各構成語の概念に重み付けを行った合成概念として未知の複合語の概念を抽出することで、専門領域での複合語の多い文書中の複合語の概念を推定する。
(もっと読む)
同義語辞書生成装置、その方法、及びプログラム
【課題】文書テキストだけではなく音声テキストに基づいても、精度の高い同義語辞書を作成することができる同義語辞書生成技術を提供する。
【解決手段】同義語辞書を作成する際に基準となる基準語彙を含む文脈と、基準語彙に関連する関連語彙を含む文脈の類似性を算出し、基準語彙の表記と関連語彙の表記の類似性を算出し、基準語彙の読みと関連語彙の読みの類似性を算出し、算出された文脈、表記及び読みの類似性を用いて基準語彙及び関連語彙についての同義指標を求め、その同義指標の大きさに基づき関連語彙が基準語彙の同義語であるか否かを判定する。
(もっと読む)
情報処理装置、情報処理方法、およびプログラム
【課題】大量の文書の中から薀蓄文を抽出する。
【解決手段】本開示の情報処理装置は、収集された1以上の文章から成る文書をトピック解析することにより、前記文書を成す各文章に対して、ローカルトピックの各項目に対する適合の程度を示す確率を算出し、収集された前記文書を言語解析することにより、ローカルトピックの項目毎に特有の言い回しパターンを検出し、収集された前記文書を成す各文章に対する評価者の評価に基づいて各文章に対するトピック有用度を設定し、トピック解析結果と前記トピック有用度に基づき、ローカルトピックの各項目に対して合計評価値を設定し、前記合計評価値に基づいてローカルトピックの項目を選別し、選別したローカルトピックの項目に特有の言い回しパターンに適合する文章を、収集された文書から薀蓄文候補として抽出する。
(もっと読む)
文書処理方法、プログラム及び装置
【課題】作業内容を説明した文書から、実際に作業者が行う作業のうち適切な作業を抽出する。
【解決手段】文書処理方法は、作業内容を説明した第1文書データを格納する第1DBから、動詞又はサ変名詞を含む自立語のうち、当該自立語に係る主語が無いという条件を満たす自立語を抽出し第1データ格納部に格納する工程と、作業内容を第1文書データより詳細に説明した第2文書データを格納する第2DBから、動詞又はサ変名詞を含む自立語のうち、上記条件を満たす自立語を抽出し第2データ格納部に格納する工程と、第1データ格納部に格納されておらず且つ第2データ格納部に格納されている自立語と、抽出すべきでない自立語を格納する第3データ格納部に格納されている自立語とを、第1及び第2データ格納部に格納されている自立語の集合から除外し、当該自立語の集合における残余の自立語を第4データ格納部に格納する工程とを含む。
(もっと読む)
怒り感情推定装置、怒り感情推定方法およびそのプログラム
【課題】感情語辞書を事前に用意する必要がなく、怒り感情を頑健に推定可能とする。
【解決手段】対話テキストを話者別のテキストに分割する話者分割処理部11と、分割された話者別のテキストの形態素を解析し、各話者別のテキストを形態素単位に分割した形態素解析結果を出力する形態素解析処理部12と、形態素解析結果を用い、話者別のテキスト中の同じ内容語の出現頻度を表す指標である発話内容冗長性特徴量を、各話者別のテキストに対して求める発話内容冗長性特徴量抽出部13と、形態素解析結果を用い、話者別のテキスト中の内容語の出現頻度を表す指標である発話内容情報性特徴量を、各話者別のテキストに対して求める発話内容情報性特徴量抽出部14と、予め学習した感情識別器30を用い、発話内容冗長性特徴量及び発話内容情報性特徴量の少なくとも一方を用いて対話テキストの対話が怒り対話か否かを推定する感情識別部20とを具備する。
(もっと読む)
入力文の細部意味を表示する文作成支援自然文処理法。
【課題】入力自然文の意味を表現する意味構造を構築し、その意味構造を細分化し、その細分化した意味構造から自然文を生成し、自然文の細部の意味を提示する。
【解決手段】
入力自然文に形態素解析や構文解析を行い、その解析結果に意味構築処理を行って、部分的な意味構造を構築し、部分的な意味構造を意味根で結合しながら、入力自然文の全体の意味構造を構築する。その意味構造を意味根で細分化して、細分化した当該意味構造から自然文を生成して明示すると入力自然文の意味が細部にまで検証できる。
書き手は、文法と知識を用いて文を作成するが、読み手も書き手と同じ知識を共有するとはかぎらない。本発明では、知識を持たない読み手の立場に立ち、主に文法情報だけで意味解析する。それによって、知識を持たない読み手でも精確に理解できる文を書き手が作成できるように支援する。そのような文作成支援自然文処理法。
(もっと読む)
商品名同一性判定装置および商品名同一性判定プログラム
【課題】商品名の記載において特徴的に出てくる販売促進目的の語句を考慮した商品名の同一性判定を行うことができる商品名同一性判定装置を提供する。
【解決手段】商品名表記ペア110を入力とし、商品名情報が蓄積された商品表記データベース120中に含まれる語句それぞれに対して、特定の商品を識別するのに有用な語句に対して高い値となり、複数の商品に含まれる語句に対して低い値となる商品スコアを算出し、商品スコアデータベース150に蓄積する商品スコア算出手段140と、商品名表記ペア110を解析して、それぞれの商品名表記に含まれる語句の共通部分と差異部分を取得し、前記データベース150にアクセスして前記語句の商品スコアを取得し、前記共通して出現する語句の商品スコアが高く、片側のみに出現する語句の商品スコアが低い場合に、入力された商品名表記ペア110は同一性が高いと判定する同一性判定手段と、を備える。
(もっと読む)
知識獲得装置、知識取得方法、及びプログラム
【課題】より迅速に結果を出力可能な知識獲得装置を提供すること。
【解決手段】特定の関係を有する単語の対と、該単語の対を含む文に関する形態素の構造とを関連付けて持つ単語対テーブルを格納した第1の記憶手段と、前記第1の記憶手段から抽出した単語の対と形態素の構造に、検索対象を限定する特定の事象を加えた検索キーを作成し、該検索キーで検索対象の文書群を格納した第2の記憶手段を検索して該検索キーの出現数を求め、求めた出現数を前記単語の対と前記形態素の構造に関連付けて前記単語対テーブルに格納する出現数情報取得手段と、前記単語対テーブルを参照し、各単語の対に関する形態素の構造毎の出現数傾向と、全単語の対に関する形態素の構造毎の出現数傾向との合致程度に基づいて、前記各単語の対と前記特定の事象との関連性を評価した評価値を出力する評価手段と、を備える知識獲得装置。
(もっと読む)
要求文書分析システム、方法およびプログラム
【課題】情報システム構築の上流工程に用いられる要求関連文書の曖昧さを改善すること。
【解決手段】情報システム構築の上流工程に用いられる要求関連文書に含まれる曖昧ポイントについて、要求関連文書に特有の評価基準に基づく曖昧性の優先順位を付け、誤った係り受けを行う可能性の高い曖昧ポイントに絞り込んで曖昧ポイントを提示することで、情報システム構築の上流工程に用いられる要求関連文書の曖昧さを改善する。
(もっと読む)
関連語抽出装置、関連語抽出方法、及び関連語抽出プログラム
【課題】意味の曖昧性のある対象語から特定の意味の関連語を抽出する。
【解決手段】関連語抽出装置100が、テキスト集合から共起単語データを作成し、共起単語データを用いて、所定の各単語について、その単語と共起する単語を求めてグループ化し、単語グループデータから、対象語400に対するグループデータを抽出し、単語グループデータから、支持語リスト500に記載の支持語毎にグループデータを抽出し、支持語リスト500と、支持語グループデータから、支持語との関係の深いグループに属する共起語(支持共起語)と支持語との共起頻度を求めて、全ての支持語に対してその共起頻度を集計し、支持共起語データとし、関連語グループデータと支持共起語データから、対象語の各関連語グループに属する共起語と一致する支持共起語の支持度を求め、対象語の関連語グループ毎に集計し、支持共起語と関係の深い共起語を関連語として選択する。
(もっと読む)
情報処理装置、データベース更新方法およびデータベース更新用プログラム
【課題】ユーザがデータベースの構造を意識することなくデータベースの更新を行うことを可能とし、ユーザの負担を軽減することを課題とする。
【解決手段】文書データを解析するための解析キーを含む解析用データが蓄積されるデータベースに接続される情報処理装置に、データベースの更新に用いられる解析キーである更新用解析キーを取得する更新用解析キー取得部21と、解析用データに含まれる情報と、更新用解析キーに関連付けられた情報との適合程度を判定する適合程度判定部23と、適合程度判定部23による判定結果に応じて、更新用解析キーを用いてデータベースを更新する際の更新処理の内容を決定する更新処理内容決定部24と、更新処理内容決定部24によって決定された更新処理の内容に従って、更新用解析キーおよび当該更新用解析キーに関連付けられた情報をもって、データベースを更新するデータベース更新部29と、を備えた。
(もっと読む)
情報処理装置、データベース更新方法およびデータベース更新用プログラム
【課題】データベースの最適化に係る作業を効率化し、ユーザの負担を軽減することを課題とする。
【解決手段】文書データを解析するための解析キーを含む解析用データが蓄積されるデータベースに接続される情報処理装置に、データベースから、解析キーの構成を把握するための基準となる1または複数の解析キーを、単位解析キーとして抽出する単位解析キー抽出部25と、単位解析キーを用いて、データベースに含まれる解析キーの構成を把握する構成把握部26と、構成把握部26によって把握された構成に従って、単位解析キーに関連づけられた情報を用いて、データベースに含まれる解析キーに関連づけられる情報を更新するデータベース更新部29と、を備えた。
(もっと読む)
1 - 20 / 324
[ Back to top ]