
Fターム[5B091CC04]の内容
Fターム[5B091CC04]の下位に属するFターム
共起関係辞書 (79)
Fターム[5B091CC04]に分類される特許
1 - 20 / 113
文書分析システム、文書分析方法およびプログラム
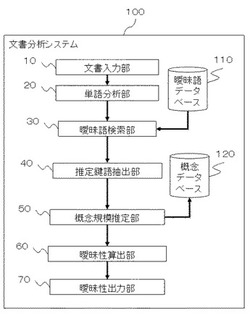
【課題】 曖昧語を含む文書について、各使用場面で曖昧語が文書の品質に与える影響の大きさを考慮して、精度よく文書の優先的な修正点や品質を推定する技術を提供する。
【解決手段】 本発明における文書分析システムは、外部から入力された文書を構成する文章に使用されている各単語の単語情報に基づいて、文書中における曖昧語を検索し、曖昧語が有る場合は当該曖昧語を抽出する曖昧語検索部と、推定鍵語を抽出するための推定鍵語抽出ルールに基づいて、文書から各曖昧語に対するそれぞれの推定鍵語を抽出する推定鍵語抽出部と、概念規模推定ルールに基づいて、推定鍵語抽出部で抽出された推定鍵語の概念の規模である概念規模指標を推定する概念規模推定部と、概念規模指標に基づいて、各曖昧語と推定鍵語との組合せ毎に曖昧性情報を算出する曖昧性算出部と、を含む。
(もっと読む)
対話装置、対話方法および対話プログラム

【課題】予め記憶した文に含まれないキーワードが入力された場合でもユーザの意図に即した応答文を生成する対話装置を実現する。
【解決手段】実施形態の対話装置におけるキーワード取得手段は、ユーザからのキーワードを取得する。概念検索手段は、概念辞書から前記キーワードの概念を検索する。応答文検索手段は、応答文テンプレート辞書から前記概念検索手段で検索された概念を含む応答文テンプレートを検索する。組み合わせ生成手段は、前記応答文検索手段で検索された応答文テンプレート中の自立語と前記キーワードとの組み合わせを生成する。共起スコア付与手段は、共起辞書を利用して前記組み合わせ生成手段で生成された組み合わせに共起スコアを付与する。応答文生成手段は、前記キーワードと、前記応答文検索手段で検索された応答文テンプレートと、前記共起スコア付与手段で付与された共起スコアとを利用して、ユーザに提示する応答文を生成する。
(もっと読む)
多義語抽出システム、多義語抽出方法、およびプログラム
【課題】情報システム構築に関する提案書や仕様書といった特定の案件に関する文書群で一般的な意味と異なる意味を有して使用されている多義語を判別してその文章の曖昧さを改善する。
【解決手段】多義語抽出システムとして、入力を受けた所定の文章中の各単語を抽出する単語分析部と、任意の単語を基軸単語として選択し、該基軸単語と共起関係とみなされる基軸単語共起語とその共起数とで表される基軸単語共起ベクトルを抽出する基軸単語共起ベクトル抽出部と、基軸単語共起ベクトルの各基軸単語共起語の共起語概念を一般概念から推定する共起語概念推定部と、推定した共起語概念群について、対応する共起語概念間の類似性に基づき、選択した基軸単語に関する各基軸単語共起語のクラスタリングを行う共起語分類部と、複数のクラスタが存在した際に多義語候補として抽出する多義語候補推定部と、抽出した候補を出力する多義語候補出力部とを設ける。
(もっと読む)
同義語抽出システム、方法およびプログラム
【課題】情報システム構築に関する提案書や仕様書等、所定の案件に関する文書で、意義は同じで語形が異なる同義語のある文章の曖昧さを改善する。
【解決手段】文章に使用されている各単語毎の品詞や格、組み合される助詞、単語間の係り受け関係に関する単語情報の抽出を行う単語分析部と、任意の単語を基軸単語として選択し、基軸単語と共起関係にある共起語とその共起数に基づく基軸単語共起ベクトルを全基軸単語についてまとめた基軸単語共起表を作成する基軸単語共起表作成部と、単語の一般概念情報を概念データベースに問い合わせ、各基軸単語共起ベクトルの各共起語を概念に変換した基軸単語概念ベクトルを全基軸単語についてまとめた基軸単語概念表を作成する単語概念推定部と、各基軸単語概念ベクトル間の類似性を判定し、類似性が高い基軸単語の組合せを同義語候補として抽出する同義語候補推定部と、同義語候補を出力する同義語候補出力部とを備える。
(もっと読む)
複合語概念分析システム、方法およびプログラム
【課題】専門領域での複合語の多い文書中の複合語の概念を推定すること。
【解決手段】複合語を構成語に分割し、同一の構成語を持つ複合語間の共起ベクトルの距離に基づく集約度を構成語支配度として算出し、構成語支配度に基づき各構成語の概念に重み付けを行った合成概念として未知の複合語の概念を抽出することで、専門領域での複合語の多い文書中の複合語の概念を推定する。
(もっと読む)
関連語グラフ作成装置、関連語グラフ作成方法、関連語提供装置、関連語提供方法及びプログラム
【課題】概念階層を定義するシソーラスにコーパスに含まれる単語間の関係を定義するトピックグラフを組み合わせることができるようにする。
【解決手段】検索装置20は、単語の概念階層を定義するシソーラス11を記憶するシソーラスデータベース231、コーパスに含まれる単語間の関係を定義するトピックグラフ12を記憶するトピックグラフデータベース232、ディレクトリ検索に用いられるカテゴリの階層を定義するカテゴリグラフを記憶するカテゴリグラフデータベース233を備える。検索装置20は、カテゴリグラフ13に含まれるノードと、シソーラス11に含まれるノードとがリンクされ、カテゴリグラフ13に含まれるノードと、トピックグラフ12に含まれるノードとがリンクされるように、シソーラス11、カテゴリグラフ13、及びトピックグラフ12を組み合わせて、グラフ構造の関連語グラフ10を作成する。
(もっと読む)
文生成装置及びプログラム
【課題】文生成に用いるテンプレートの再利用性を向上させ、条件や参照先の値に応じてきめ細かな文を生成することができる文生成装置及びプログラムを提供する。
【解決手段】本発明の文生成装置は、概念や概念間の関係を示すドメイン知識を体系的に表現したオントロジーと、概念及び概念間の関係に関連付けられたものであって、少なくとも、生成する文の変数とする参照先情報の参照先と所定の文字列とを含む1又は複数の可変部を有する文テンプレートとを格納するオントロジー格納手段と、文を生成する際、オントロジー格納手段から生成する文に関する概念に関連する文テンプレートを選択する文テンプレート選択手段と、選択された文テンプレートの各可変部に含まれている参照先に基づいて取得した参照先情報を展開し、参照先情報の直前及び又は直後に文字列を合成して出力文を生成する文生成手段を備える。
(もっと読む)
対話処理装置
【課題】ユーザ感情状態の変化を促すような応答文を作成することができる対話処理装置を提供する。
【解決手段】ユーザの感情の認識と、知識データベースを用いたユーザに対する感情表現とを実行する対話処理装置であって、ユーザ感情の認識結果から、感情の種別及び感情の強さを成分とした座標系における現在点を得るとともに、この座標系において現在点よりも目標とする感情の収束状態に近い経由点を決定する処理を含み、知識データベースは、複数の語彙及び定型文のそれぞれを、感情の種別及び感情の強さに応じたパラメータに関連付けて示すものであり、前記ユーザに対する感情表現は、経由点での感情の種別及び感情の強さに応じたパラメータで知識データベースを検索することで、対話に用いるべき語彙及び定型文の少なくとも一方を得て、その取得結果を用いた応答文を作成することでなされる。
(もっと読む)
上位概念出力プログラム及び上位概念出力装置
【課題】対象とする語句が見出し語となっている概念が概念辞書中に存在しない場合において、対象とする語句の上位概念を出力する上位概念出力プログラム及び上位概念出力装置を提供する。
【解決手段】上位概念出力装置1は、語句を受け付ける表現受付手段100と、表現受付手段100により受け付けられた語句と関連する語句との関連度を計算し、当該関連度に基づいて関連する語句から関連語を検索する関連語検索手段101と、概念辞書111に基づいて、関連語を見出し語として持つ概念を抽出し、抽出された概念の上位概念を概念辞書111に基づいて抽出し、関連語と上位概念とこれらの概念の繋がりとから構成される部分木20を作成する部分木作成手段102と、概念の繋がりの形態に対応付けられた係数基づいて、関連度から上位概念のスコアを計算する関連度計算手段103と、上位スコアを有する上位概念を出力する概念出力手段104とを有する。
(もっと読む)
テキストコーパスにおける2つのエンティティ間の関係抽出方法及び装置
【課題】テキストコーパスから2つのエンティティ間の関係抽出を行う。
【解決手段】
複数のエンティティペア、複数の語彙パターンのいずれか一方を行、他方を列として、各エンティティペアと各語彙パターンとを関連付ける頻度を要素とする第1共起行列を作成するステップと、第1共起行列において、前記複数のエンティティペア、前記複数の語彙パターンをそれぞれ頻度が大きい順にソートして第2共起行列を作成するステップと、第2共起行列において、複数のエンティティペア、複数の語彙パターンをクラスタリングして、エンティティペアのクラスタ、語彙パターンのクラスタを取得し、取得したエンティティペアのクラスタ、語彙パターンのクラスタのいずれか一方を行、他方を列とし、クラスタリングにより加算された頻度を要素とする第3共起行列を作成するクラスタリングステップと、を備える。
(もっと読む)
学習データ収集システム、学習データ収集方法、学習データ収集プログラム
【課題】多義語の曖昧性解消に適した高精度の連想語に基づき連想概念辞書を作成し、件数数や品質方針などのパラメータに応じて学習データを収集可能とする。
【解決手段】連想概念辞書10は、評価語の分類されるべき語義のカテゴリを表す分類ラベル語と該評価語との組合せから被験者が連想する連想語を収集し、収集された連想語を評価語と分類ラベル語と併せて保持する。連想語インデックス作成手段12は、連想概念辞書の評価語および分類ラベル語を含む文を、電子文書群を集積したコーパス11から抽出し、抽出文における連想語の有無を評価語および分類ラベル語のペア毎に示す連想語インデックスを作成し、DB13に保存する。学習データ収集手段14は、前記インデックスに基づき評価語と分類ラベル語と連想語とを含む文をコーパス11から収集し、DB15に保存する。
(もっと読む)
情報処理装置、情報処理方法、およびプログラム
【課題】「近傍の単語は互いに関係がある」という仮定に基づきながらも、その仮定が成立していない可能性をも考慮した、文脈情報を利用した統計的自然言語処理を確立する。
【解決手段】ステップS1で、処理対象の文書が特徴量抽出部に入力され、ステップS2で、特徴量抽出部が、処理対象の文書に含まれる文脈情報毎に特徴量を抽出する。ステップS3で、特徴量解析部は、処理対象の文書の各文脈情報の特徴量に対応する潜在変数をギブスサンプリングにより推定する。ステップS4で、クラスタリング処理部は、各文脈の文脈トピック比を新たな特徴量ベクトルとみなし、この特徴量ベクトルに基づいて、文脈情報(の固有名詞ペア)のクラスタリングを行う。ステップS5で、基本情報生成部は、解析結果DBに保持されているクラスタリング結果に基づいて基本情報を生成する。本発明は、文書の統計的自然言語処理に適用することができる。
(もっと読む)
機械翻訳装置及びプログラム
【課題】翻訳対象原文と翻訳用例原文との差分が翻訳用例訳文に含まれない合成語の場合であっても訳文中の対応する訳語の範囲を確定することである。
【解決手段】入力装置20から入力された翻訳対象の第1言語の文章データを1文単位に分割して翻訳対象原文を求め、翻訳用例検索部30は翻訳対象原文に対して翻訳用例データベース36から翻訳用例原文と翻訳用例訳文との対の翻訳用例を検索し、差分対応付け部31は類似用例原文と翻訳対象原文との差分に対応する類似用例訳文中の語句と翻訳対象原文中の語句とを対応付け、その1対1の対応付けに失敗した語句に対して再対応付け可能判定部32によりそれぞれの語句の範囲を拡大して再度対応付けを行い、これらによって対応付けられた翻訳対象原文中の差分の語句の訳語を取得し、訳語置換部34は対応付けられた類似用例訳文中の語句を、取得した訳語に置き換えて訳文を生成する。
(もっと読む)
知識構築装置およびプログラム
【課題】テキストに関する構成要素情報を得るためのルールを、単語表層にとらわれずに概念レベルで生成して蓄積することのできる、知識構築装置を提供する。
【解決手段】知識構築装置は、テキスト項目と構成要素情報とを、互いに関連付けて記憶するテキストデータ記憶部を備える。そして、単語抽出部は、テキスト項目に含まれる単語の出現頻度に基づき、テキスト項目に特有の単語を抽出する。知識データ取得部は、単語と単語概念との関係を表わす知識データを取得する。概念獲得部は、前記知識データを用いて、テキスト項目から抽出された単語を対応する単語概念に置き換えるとともに、当該テキスト項目に関連付けられた構成要素情報と組み合わせ、事例データとして出力する。機械学習装置は、この事例データを用いて機械学習を行い、単語概念と構成要素情報との関係を表わすルールを生成する。
(もっと読む)
用語間の対応関係抽出システム及び対応関係抽出プログラム
【課題】テキストデータに基づいて各企業の商品名を抽出し、対応する製品分類に自動的に関連付ける技術を提供する。
【解決手段】一般名称としての製品分類を複数格納した製品分類辞書16と、入力されたテキスト文を形態素単位に分解すると共に、製品分類辞書16を参照し、各形態素の中で製品分類に該当するものに対して対応のタグを付する形態素解析処理部12と、タグを含む文字列パターンと、この文字列パターン中からタグを付された製品分類に属する具体的商品名として抽出すべき文字列の位置とを規定する抽出ルールを、複数格納しておく抽出ルール記憶部18と、テキスト文の中の抽出ルールにマッチする文字列パターン中の所定の位置に存する文字列をタグが付された製品分類に属する商品名として抽出し、この製品分類と商品名との組合せを関係情報記憶部20に格納する関係情報抽出部14とを備えた用語間の対応関係抽出システム10。
(もっと読む)
翻訳装置及び翻訳プログラム
【課題】複雑な入力文について、少ない計算量で精度良く翻訳できるようにする。
【解決手段】入力文と候補例文の類似度及びカバー率の関係に基づき候補例文を検索し、前記入力文の示す単語で区切られた文字列を検索した候補例文に対応させ、単語及び節を含む文字列に変換する。変換文字列を、前記候補例文との相違値を算出し、算出した相違値を定める前記変換した入力文と候補の例文との写像としての対応関係を抽出し、抽出した対応関係を選択する。選択された対応関係を、当該入力文に対応する候補の例文に対応して修正し、修正した入力文に基づき、前記相違値の算出と対応関係の抽出を修正し、該修正結果に基づき、前記入力文を翻訳する。
(もっと読む)
同義語展開システム及び同義語展開方法
【課題】文書から抽出された単語を、各単語の出現文脈に適した同じ意味を示す同義語に展開する。
【解決手段】ある単語の係り先となる単語を含む第1文脈情報が格納された第1データベースを参照して、第1単語の第1文脈情報と第2単語の第1文脈情報とを比較することによって、類似度を計算し、類似度が高い第2単語を第1単語の同義語候補に決定し、ある単語から文章中で所定の語数内に出現する単語を含む第2文脈情報が格納された第2データベースを参照して、第1単語の第2文脈情報と少なくとも一以上の同義語候補の第2文脈情報とを比較することによって、文脈適合度を計算し、類似度及び文脈適合度に基づいて、同義語候補の同義語展開スコアを計算し、同義語展開スコアに基づいて、同義語候補から第1単語の同義語を決定する。
(もっと読む)
言語資源情報生成装置、方法、プログラム、および記録媒体
【課題】Web上の文書などの電子化文書に基づいて、高い品質精度の言語資源情報を生成する。
【解決手段】意味クラス制限部13により、意味クラス制限情報DB23Bに登録されている意味クラス制限条件を参照し、対象語の特徴量に基づいて当該対象語が持つ意味の大分類を特定することにより、シソーラスに記述されている各意味クラスのうちから当該対象語に対して付与する意味クラスの種類を制限し、意味クラス選択部14により、意味クラス推定条件DB2Cに登録されている意味クラス推定条件を参照して、大分類に含まれる意味クラスごとに、対象語の特徴量に基づいて当該意味クラスと当該対象語との関係度合いを示す評価値を算出し、これら評価値に基づいて当該対象語との関係度合いが大きい意味クラスを、当該対象語に付与する意味クラスとして選択する。
(もっと読む)
オントロジー作成支援装置及びプログラム
【課題】 状況や条件等に応じて内容が変化するオントロジーを効率良く作成させる。
【解決手段】 条件の組み合わせという次元によって、内容が変化する、同一の概念体系に係る1又は複数の多次元オントロジーの作成、更新を支援するオントロジー作成支援装置に関する。条件なし時用の基本オントロジーを格納しておくと共に、条件存在時の多次元オントロジーと基本オントロジーとの差分情報である次元別オントロジーを格納しておく。指定された条件の組み合わせに従った次元別オントロジーと基本オントロジーとを合成し、表示/編集用オントロジーを生成し、オペレータの操作に応じてこれを編集する。保存指令時には、表示/編集用オントロジーの基本オントロジーからの差分情報を、次元別オントロジーとして格納する。
(もっと読む)
対話制御システム及びプログラム、並びに、多次元オントロジー処理システム及びプログラム
【課題】多次元オントロジーを利用することにより、ユーザの発言に対して対話の流れを円滑に、質問すべき事柄の重要度を刻々と変化させたりすることができる。
【解決手段】本発明は、概念や概念間の関係を示すドメイン知識を体系的に表現したオントロジーを用いてユーザに対する質問を決定して質問を行い、受け取ったユーザ回答に応じた対話を行う対話制御システムであり、1又は複数の次元別オントロジーと、基本オントロジーとを格納し、ユーザ回答の概念が条件として設定されると、この条件に合う1又は複数の次元別オントロジーを取り出し、取り出された各次元別オントロジーのうち、次元優先度に従って次元優先度の低いものから順に、各次元別オントロジーの内容を基本オントロジーに上書きして多次元オントロジーを生成し、この多次元オントロジーを用いて対話を制御することを特徴とする。
(もっと読む)
1 - 20 / 113
[ Back to top ]