
Fターム[5B091EA01]の内容
Fターム[5B091EA01]に分類される特許
1 - 20 / 180
機械翻訳システム、機械翻訳方法および機械翻訳プログラム
並替モデル生成装置、語順並替装置、方法及びプログラム
知識量推定情報生成装置、知識量推定装置、方法、及びプログラム
意味ラベル付与モデル学習装置、意味ラベル付与装置、意味ラベル付与モデル学習方法、及びプログラム
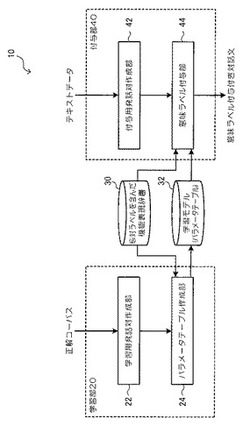
【課題】会話の流れによって疑問表現になったり、断定表現になったりする述部の機能表現に対しても、適切な意味ラベルを付与する。
【解決手段】学習用発話対作成部22で、形態素解析結果に対して、機能表現及び応対表現の正解ラベルが付与された正解コーパスに基づいて、学習用発話対を作成する。パラメータテーブルに、素性として、発話対の前の発話の終わりに表れる機能表現の意味ラベルと、それに対する後の発話の初めに表れる応対表現の意味ラベルとの並びの素性を用い、複数種類の素性各々について、重みの初期値を設定する。パラメータテーブル作成部24で、発話対の形態素情報と機能表現辞書30とを用いて、各形態素について候補となる意味ラベルを全て含んだラティスを構築し、ラティス構造からパラメータテーブルの素性毎の重みに基づいて最尤パスとして探索する。最尤パスが正解の意味ラベル列となるようにパラメータテーブルの重みを学習する。
(もっと読む)
対話モデル構築装置、方法、及びプログラム

【課題】3回以上のやりとりが少ない対話データを学習データとして用いた場合でも、精度の良い対話モデルを構築する。
【解決手段】部分集合抽出部12は、2回のやりとりの対話データを複数取得する。辞書データ20から見出し抽出部14が見出し語を抽出し、カテゴリ抽出部16がカテゴリ情報を抽出して、見出し語・カテゴリ情報のペアを作成する。部分集合抽出部12は、取得した対話データ内の各単語に見出し語・カテゴリ情報に基づいてカテゴリ情報を付与し、入力されたキーワードを単語及びカテゴリ情報に含む対話データを部分集合として抽出する。対話モデル学習部18は、部分集合を用いて、学習過程において2回のやりとりから、内容が近い発話データをクラスタリングすることで2回を超えるやりとりを構成しながらHMMを学習し、学習したHMMを対話モデルとして出力する。
(もっと読む)
最適翻訳文選択装置、翻訳文選択モデル学習装置、方法、及びプログラム
【課題】複数の翻訳器から得られる翻訳候補から、ベイズリスク最小化基準により、所望の翻訳評価尺度を最適化できるような翻訳候補を選択することができるようにする。
【解決手段】第2翻訳制御部48によって、複数の翻訳器43A〜43Cから、入力された翻訳元言語の文に対する複数の翻訳文候補を取得する。第2特徴量算出部49によって、取得された翻訳文候補の各々について、予め定められた翻訳評価尺度と相関する複数の特徴量を算出する。翻訳文スコア計算部50によって、複数の翻訳文候補の各々について、学習された最適翻訳文選択モデルを用いて、翻訳文スコアを計算し、最適翻訳文選択部51によって、複数の翻訳文候補から、最適翻訳文を選択する。
(もっと読む)
意味分析装置およびそのプログラム
【課題】より少ない正解事例からも、意味分析のためのモデルを精度良く構築できるようにする。
【解決手段】正解データ記憶部は、学習用データに対応する正解データを記憶する。拘束条件記憶部は、学習用データに関する潜在変数間の条件を拘束条件データ。解析部は、学習用データを読み込み、学習用データを解析して得られる解析結果データを出力する。モデル生成部は、正解データ記憶部から読み出した正解データと解析部から出力された解析結果データとを用い、解析結果データに潜在変数を対応させるとともに、拘束条件記憶部から読み出した拘束条件データに基づいて、拘束条件データを潜在変数同士の拘束条件として、学習処理を行ってモデルを生成する。
(もっと読む)
選択候補学習装置、訳語学習装置、選択候補学習方法、及びコンピュータ・プログラム
【課題】 少ない計算量で学習データの精度向上を実現する選択候補学習装置等の提供。
【解決手段】 選択候補学習装置において、優先度調整部は、第1情報と、その第1情報に対応する候補である1つ以上の第2情報とが関連付けされた情報の中から、特定の第2情報が選択されるのに応じて、前記第2情報に関する優先度のうち、該特定の第2情報に関する優先度を更新する。これにより、優先度調整部は、前記第1情報と前記第2情報とに関する学習情報を調整する。
(もっと読む)
言語変換において複数の読み方の曖昧性を除去する方法
【課題】同形異音異義語の漢字と関連付けられるピンインに対して望ましくない中国語変換候補を生成しない方法及び装置を提供する。
【解決手段】言語変換において複数の読み方の曖昧性を除去することが開示される。これは、対象記号系での入力データの記号表現を含む文字の集合に変換される入力データを受信することと、対象記号系の同形異音異義語の文字が入力データの対応する一部分を表すために使用されるべきである確率を判定するために文字の第1の読み方と第2の読み方とを区別する言語モデルを使用することとを含む。
(もっと読む)
並べ替え規則学習装置、方法、及びプログラム、並びに翻訳装置、方法、及びプログラム
【課題】文法的な構造を分断してしまうような並べ替えを抑制し、高精度な機械翻訳を行う。
【解決手段】入力文解析部54で、翻訳元言語で記述された入力文が、文節各々及び文節間の係り受け関係を示すノードを含んで構成され、ノードに対応する文節内に存在する機能語を示すラベルがノード各々に付与された構文木で表現されるように、入力文を解析する。並べ替え部56で、解析された構文木に対して並べ替え規則42を適用して、入力文を並べ替える。並べ替え規則42は、構文木における部分木の複数の子ノードを並べ替えるための並べ替え規則であって、子ノードに付与されたラベルで示される文節内の機能語と翻訳先言語の文法とによる制約と、翻訳元言語と翻訳先言語との単語対応及び翻訳先言語の構文解析結果による制約とが考慮されている。翻訳処理部58は、並べ替え部56で並べ替えられた入力文を翻訳モデル46に基づいて、翻訳先言語に翻訳する。
(もっと読む)
翻訳装置、方法、及びプログラム、並びに翻訳モデル学習装置、方法、及びプログラム
【課題】単語対応付けが容易で、高速かつ高精度な翻訳を行う。
【解決手段】学習前処理部22で、翻訳先言語を翻訳元言語に近い語順のまま翻訳先言語の語彙に置き換えた翻訳中間言語を作成し、前翻訳学習部24で、翻訳元言語と翻訳中間言語との並行コーパスを用いて、翻訳元言語を中間翻訳文に翻訳するための前翻訳モデル34を学習し、後翻訳学習部26で、翻訳中間言語と翻訳先言語との並行コーパスを用いて、中間翻訳文を翻訳先言語に翻訳するための後翻訳モデル36を学習する。前翻訳部54で、前翻訳モデル34を参照して、入力文を中間翻訳文に翻訳し、後翻訳部56で、後翻訳モデル36を参照して、中間翻訳文を翻訳先言語の文に翻訳する。
(もっと読む)
単語対応付け装置、方法、及びプログラム
【課題】ベースとなる単語対応付けアルゴリズムに依存することなく、高精度かつ汎用性の高い単語対応付けを行う。
【解決手段】目的分野単語対応付け学習部12により、目的分野の対訳データを用いて目的モデルMinを学習し、一般分野単語対応付け学習部14により、一般分野の対訳データを用いて一般モデルMgenを学習する。目的分野対応付け確率推定部16により、目的モデルMinを用いて目的分野の対訳データを単語対応付けしたときの単語対応行列Ainに相当する確率Tij及びtijを推定し、一般分野対応付け確率推定部18により、一般モデルMgenを用いて同一の目的分野の対訳データを単語対応付けしたときの単語対応行列Agenに相当する確率Gij及びgijを推定する。単語対応行列生成部20により、確率Tij、tij、Gij及びgijを統合することにより、単語対応行列Aを生成する。
(もっと読む)
解析モデル学習装置、方法、及びプログラム
【課題】計算コストの増大を抑制しつつ、高精度な分類精度を得られる解析モデルを学習する。
【解決手段】ベースライン解析部2で、解析対象、基本特徴量、及び正解を含む複数の訓練用サンプル各々に対して、解析結果の予測値を解析し、ルール候補作成部4で、解析誤りのある訓練用サンプルからルールテンプレート5に従って変換ルール候補を作成し、ルール選択部6で、変換ルール候補各々を適用した場合に、正味の正解増加数が最大となる変換ルール候補を選択し、ルール適用部8で、選択した変換ルールを全訓練用サンプルに適用し、解析誤りが0になるまでルールの生成及び適用を繰り返す。インデクス作成部10で、各訓練用サンプルに適用されたルールの履歴及び基本特徴量のインデクスを格納し、訓練ベクトル作成部12で、インデクスに基づいて訓練ベクトルを作成し、学習部14で、訓練ベクトルに基づいて解析モデルを学習する。
(もっと読む)
モデルパラメータ配列装置とその方法とプログラム
【課題】モデルの要素集合Θのパラメータ要素をその重要度順に配列するモデルパラメータ配列装置を提供する。
【解決手段】初期化部は、選択サブセット候補を空集合で初期化して集合Θと選択サブセット候補を出力する。要素選択部は、集合Θと選択サブセット候補を入力として、サブセット候補として選択サブセット候補と他のパラメータ要素との全ての組を出力する。サブセット評価値記憶部は、サブセット候補を入力として、当該サブセット候補のそれぞれのスコアEtの最大値若しくは最小値と、上記集合Θのスコア値である評価値Eとの差分を求め、その差分が最小若しくは最大となるサブセット候補を選択サブセット候補として記憶する。
(もっと読む)
縮約素性生成装置、方法、プログラム、モデル構築装置及び方法
【課題】一般的な教師あり学習に用いられる素性よりも、コンパクトかつ高精度の縮約素性を生成する。
【解決手段】原素性重要度計算部141で、ベースモデル構築部12により正解データから学習して構築されたベースモデル22と未解析データ24とを用いて、未解析データ24の入力に対するベースモデル22の最尤出力に対して、未解析データから抽出された原素性各々が与える影響を示す重要度を、複数の原素性各々について計算する。原素性選択部142で、重要度が0の原素性を排除して、残りの原素性を選択する。原素性融合部143で、選択した原素性集合から、同じ重要度となる原素性を一つの縮約素性としてまとめ上げて、縮約素性集合を生成する。原素性重要度追加部144で、原素性の重要度に関する素性を生成して、縮約素性集合に追加する。
(もっと読む)
翻訳支援装置、翻訳支援方法及びプログラム
【課題】
英語から日本語に人手で翻訳を行う作業者が行う必要のある入力操作を可能な限り少なくすることによって、作業の効率化及び省力化を図ることである。
【解決手段】第1言語文書解析手段は、翻訳辞書部を用いて第1言語文書を解析し形態素解析情報及び係り受け解析情報を求める。第2言語文書解析手段は、翻訳辞書部を用いて第1言語文書のうち翻訳者により第2言語に翻訳された文を解析し形態素解析情報及び係り受け解析情報を求める。訳語リスト作成手段は、第1言語文書の中に含まれる単語のうち内容語を抽出し、翻訳者により翻訳された文中から第1言語の内容語に対応する第2言語の内容語を抽出し、第1言語と第2言語との内容語を対応付けた訳語リストを作成する。訳語予測手段は、翻訳者が翻訳しようとする第1言語の文に含まれる内容語が訳語リストにあるときはそれに対応する第2言語の内容語を導き出し表示装置に表示する。
(もっと読む)
機械翻訳装置、および機械翻訳方法
【課題】従来、精度の高い機械翻訳ができなかった。
【解決手段】係り受け森を構成する各頂点に対して、1以上の各翻訳規則を適用し、頂点ごとに、合致する1以上の翻訳規則を取得する翻訳規則取得部と、係り受け森を構成する各頂点をヘッドとした1以上の超辺であり、各頂点に対応する1以上の翻訳規則の左辺における変数部分に対応する頂点をテイルとした1以上の超辺を取得する超辺取得部と、係り受け森を構成する全頂点と、超辺取得部が取得した1以上の超辺とを有する翻訳森を取得する翻訳森取得部と、翻訳森の各頂点に対応する1以上の各超辺が有する翻訳規則の右辺と単語辞書とを用いて、1以上の翻訳候補を取得する翻訳候補取得部と、1以上の翻訳候補のうちいずれか1以上の翻訳候補である翻訳結果を出力する出力部とを具備する機械翻訳装置により、精度の高い機械翻訳が可能となる。
(もっと読む)
対訳フレーズ学習装置、フレーズベース統計的機械翻訳装置、対訳フレーズ学習方法、および対訳フレーズ生産方法
【課題】種々の粒度のフレーズペアを学習できなかったり、不適切なフレーズペアを学習したりした。
【解決手段】フレーズテーブルと、フレーズペアの取得を試みて、取得できなかった場合、一の記号を取得する記号取得部と、フレーズペアを取得できなかった場合、当該フレーズペアより小さい2つのフレーズペアを生成する部分フレーズペア生成部と、取得した記号に従って、新しいフレーズペアを生成する、または、2つのフレーズペアを順に繋げた新しいフレーズペアを生成する、または、2つのフレーズペアを逆順に繋げたフレーズペアを生成する、のいずれかを行う新フレーズペア生成部とを具備し、上記の処理を再帰的に行い、フレーズテーブルの各フレーズペアに対するスコアを算出し、当該スコアを各フレーズペアに対応付けて蓄積する対訳フレーズ学習装置により、多数の適切なフレーズペアを学習できる。
(もっと読む)
具体主題の有無判定装置、方法、及びプログラム
【課題】文書が具体主題を有するか否かを判定する。
【解決手段】名詞句抽出部12で、具体主題の候補となる名詞句を抽出し、意味カテゴリ付与部18で、名詞句各々に意味カテゴリを付与し、エントロピー算出部20で、付与された意味カテゴリの偏りを示すエントロピーを第1の素性として算出する。また、視覚的特徴算出部24で、入力された文書が縦長か横長かを示す第2の素性を算出する。素性ベクトル生成部26で、第1の素性及び第2の素性を並べた素性ベクトルを生成し、具体主題が既知の学習用文書の素性ベクトルを用いて学習された分類器に入力して、入力された文書が具体主題を有するか否かを判定する。
(もっと読む)
学習装置、判定装置、学習方法、判定方法、学習プログラム及び判定プログラム
【課題】照応解析において先行詞及び照応詞を判定する精度を向上可能な照応解析技術を提供する。
【解決手段】学習装置は、文章と、前記文章内で照応関係を有する各要素の後方境界と、先行詞となる第1の要素及び照応詞となる第2の要素の対応関係とを示す訓練データの入力を受け付け、訓練データに基づいて、任意の文章において照応関係の有無を判定するための判定基準を学習する。判定装置は、文章と、前記文章内で照応関係を有する可能性のある各要素の後方境界とを示すユーザデータの入力を受け付け、ユーザデータに基づいて、学習装置が学習した判定基準に従って、文章において照応関係の有無を判定する。
(もっと読む)
1 - 20 / 180
[ Back to top ]