
Fターム[5D015HH04]の内容
音声認識 (5,191) | パターン照合による認識 (426) | パターン間の類似尺度の計算 (85)
Fターム[5D015HH04]の下位に属するFターム
重み付けをするもの (47)
マルチテンプレート方式 (8)
Fターム[5D015HH04]に分類される特許
1 - 20 / 30
音声認識装置、音声認識方法、及び音声認識プログラム
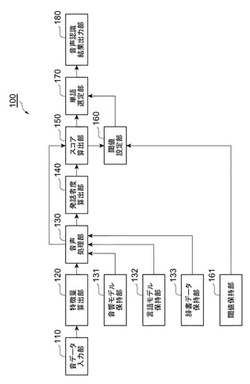
【課題】音声認識精度を向上させる。
【解決手段】本発明に係る音声認識装置100は、音データに含まれる単語を抽出し、各単語の信頼度を算出する音声処理部130と、各単語に対応する音データの発話者の音声らしさを示す各単語の発話者度を算出する発話者度算出部140と、音声処理部130により算出された各単語の信頼度、及び発話者度算出部140により算出された各単語の発話者度に基づいて、各単語のスコアを算出するスコア算出部150と、所定の閾値を設定する閾値設定部160と、各単語のスコアと所定の閾値とに基づいて、音声認識結果として採用する単語を選定する単語選定部170とを備える。
(もっと読む)
音声認識装置、音声認識方法、および音声認識プログラム

【課題】単語共起情報を利用する音声認識において、認識精度の低下を抑える。
【解決手段】音声認識装置は、単語検出部および評価値算出部を備える。単語検出部は、音声データから認識対象単語およびその認識対象単語の共起単語を検出する。評価値算出部は、記認識対象単語が検出された第1の音声区間と共起単語が検出された第2の音声区間との間の時間間隔に基づいて、認識対象単語および共起単語の組合せに対する評価値を算出する。
(もっと読む)
パターン認識方法
【課題】情報の欠落を抑えてパターン認識の判別能力を向上でき、多値離散量や連続量のデータに対して適応可能なRT法によるパターン認識方法を提供する。
【解決手段】複数のサンプルデータから構成される単位空間内に、判別対象のデータが属するか否かを判別するパターン認識方法であって、サンプルデータ及び判別対象のデータを定義する複数の項目を、係数及び切片を有する一次式によって平均値m、感度β及び、標準SN比ηに圧縮し、これらの値を用いて判別対象のデータが単位空間内に属するか否かを判別する。
(もっと読む)
音声認識方法、音声認識装置及び音声認識プログラム
【課題】音声認識処理を行うこと無く短い処理時間で信頼度スコアを計算し、言語モデルに依存しない信頼度スコアを出力する音声認識装置と音声認識方法と、音声認識プログラムを提供する。
【解決手段】フレーム毎の音声特徴量系列を用いて、その音声特徴量系列に対するモノフォンHMMの各状態に属するGMMから得られる出力確率bs(ot)と、その各状態sの出現確率P(s)との積が最も高いものを求め、最も高い積P(s^)bs^(ot)の対数または出力確率bs^(ot)の対数と、その入力に対する音声モデルの状態に属するGMMまたはポーズモデルHMMの各状態に属するGMMから得られる最も高い出力確率bg^(ot)の対数との差を当該フレームの事前信頼度とし、その事前信頼度を平均化して音声ファイル単位の信頼度スコアを求め、音声特徴量系列を用いて、信頼度スコアに基づき音声認識処理を行う。
(もっと読む)
特徴抽出装置及びパターン認識装置
【課題】認識するカテゴリ間の部分空間同士の角度を広げる場合に、同時に同一カテゴリに属する部分空間の間の角度も広げてしまうという問題があった。
【解決手段】2つのパターンの集合の類似性をパターンの集合から主成分分析により生成した線型部分空間同士の角度で定義する手法において、カテゴリ間の差とカテゴリ内の変動を測る基準に部分空間同士の角度を用い、カテゴリ間の差の強調とカテゴリ内の変動の抑制を同時に行う手法を提供する。
(もっと読む)
類似区間検出装置
【課題】類似位置を高速に探索可能であり、過剰検出や探索漏れを抑制可能な類似区間検出技術を提供する。
【解決手段】特徴量抽出部122は、第1入力受付部120が入力を受け付けた映像信号Vxから特徴量列Xを抽出し、第2入力受付部121が入力を受け付けた映像信号Vyから特徴量列Yを抽出する。類似位置検出部123は、特徴量列X及び特徴量列Yを時系列に照合して、その類似度がしきい値記憶部124に記憶された探索しきい値θより大きい位置を類似位置として検出する。検出結果出力部125は、類似位置検出部123の検出結果rを2値化して出力する。類似位置分布算出部126は、検出結果rを用いて、類似位置の数の分布を算出する。しきい値更新部127は、類似位置の分布が所定の分布条件を満たす場合に、しきい値記憶部124に記憶された探索しきい値θを更新する。
(もっと読む)
音声検索装置、音声検索方法及び音声検索プログラム
【課題】入力された音声に類似する音声を音声データベースから精度良く検索することのできる音声検索装置を提供する。
【解決手段】特徴ベクトル算出部100は、入力音声の特徴ベクトル列と、音声DB14から切り出した比較対象の音声の特徴ベクトル列を算出する。ベクトル間距離算出部102は、両特徴ベクトル列をDPマッチングにより照合し、その照合結果に基づいて、両特徴ベクトル列の各ベクトルの組間の距離を算出する。有効特徴間距離取得部103は、DPマッチングによる照合の結果得られた交点の系列に基づいて、距離の長い順に複数のベクトルの組を抽出し、抽出した複数のベクトルの組間の距離の平均を求め、これを有効特徴間距離として取得する。類似判定部104は、有効特徴間距離と閾値とを比較し、その結果に基づいて、入力音声と比較対象の音声が類似しているか否かを判定する。
(もっと読む)
カラレコ装置及びコンピュータプログラム
【課題】新たなエンタテイメント性のあるカラレコ装置及びコンピュータプログラムを提供する。
【解決手段】カラレコ装置1は、画像コンテンツ及び配役の選択を受け付ける選択受付部2Aと、選択受付部2Aにより受け付けられた画像コンテンツの画像に対応する音声のうち、配役に対応する所定の音声を出力しないように設定する音声出力設定部11と、音声出力設定部11の設定に応じて、所定の音声を除く他の音声を出力する音声出力部3と、画像コンテンツの画像と、所定の音声に対応する文字とを表示する表示部4と、表示部4に文字が表示されている間プレイヤの音声を受け付ける音声受付部2Bと、を備える。
(もっと読む)
学習データのラベル誤り候補抽出装置、その方法及びプログラム、その記録媒体
【課題】学習データのラベル誤り候補を効率的に抽出することができるようにする。
【解決手段】学習データベース10から音声データ・ラベル対を読み出す手段21と、読み出した音声データを音声認識し、その認識結果に対するフレーム単位の認識スコアを計算する認識スコア計算手段31と、読み出した音声データを音声認識し、読み出したラベルに対するフレーム単位の学習スコアを計算する学習スコア計算手段32と、認識スコアと学習スコアを比較し、学習スコアが認識スコアより低い区間を誤りとして、ラベルの信頼度を計算する信頼度計算手段33と、信頼度と読み出した音声データ・ラベル対とを組として蓄積する手段35と、その蓄積手段35から信頼度が低い順にラベルの誤り候補を抽出して出力する手段36とを具備する。
(もっと読む)
音を検出するための装置および方法
音を検出するための装置が、複数のマイクロホン、音検査ユニット、方向推定ユニット、暗騒音除去ユニット、および警報ユニットを備えている。マイクロホンは、ユーザの周囲の音を収集するために使用される。音検査ユニットは、所定の時間間隔内の暗騒音の特徴値を計算するため、および最後に収集された音が所定の条件を満足するか否かを判定するために使用される。前記所定の条件が満足される場合、方向推定ユニットが、前記最後に収集された音の発生方向を推定し、発生方向がユーザの背後の所定の範囲にあるか否かを判断するために使用される。前記所定の範囲が満足される場合、暗騒音除去ユニットが、前記最後に収集された音の暗騒音を除去して検出音を得るために使用される。警報ユニットは、前記検出音を警報メッセージによってユーザへと通知するために使用される。音を検出するための方法も開示される。  (もっと読む)
(もっと読む)
高速音声検索の方法および装置
【課題】 高速音声検索の方法および装置を提供する。
【解決手段】 本願で開示されている主題の実施形態によると、ロバスト且つ並列な検索方法に基づいて、マルチプロセッサシステム内の大きい音声データベースを検索してターゲット音声クリップを特定し得る。大きい音声データベースは複数のより小さいグループに分割されて、これら複数の小グループがシステム内の複数の利用可能なプロセッサに対して動的にスケジューリングされ得る。プロセッサは、各グループを複数のより小さいセグメントに分割して、セグメントから音声特徴を抽出して、共通成分ガウス混合モデル(CCGMM)を用いてセグメントをモデル化することによって、スケジューリングされた複数のグループを並列に処理し得る。1つのプロセッサはさらに、ターゲット音声クリップから音声特徴を抽出してCCGMMを用いて抽出した音声特徴をモデル化し得る。ターゲット音声クリップと各セグメントとの間のカルバック・ライブラー(KL)距離をさらに算出し得る。KL距離に基づいて、セグメントがターゲット音声クリップに一致するか否か判断するとしてもよく、および/または、複数の後続のセグメントの処理を省略するとしてもよい。
(もっと読む)
音声データ処理方法
【課題】 TV・CMを、放送手段や、映像フォーマットに関わらずに、自動的に識別するための音声を圧縮したデータを計算する。
【解決手段】 音声信号は、音声帯域通過回路101−10、音声エンベロープ作成回路101−11を経て音声エンベロープ信号としてCPU101−14に供給され、また、エンベローブ信号に基づき、A/Dコンバータ101−9により水平同期でサンプリングされた音声デジタルデータをCPU101−14内部で圧縮して、音声パターン平均化データ、音声パターン偏差を計算する。映像信号は、画像変化信号作成部101−8に導かれ画像変化信号を作成する。CPU101−14では、画像変化信号、フレーム同期信号、音声エンベロープ信号等の各入力信号に基づき、イベント信号の作成、CM切り出しデータ作成等の処理を行う。
(もっと読む)
キーワード選択方法、音声認識方法、キーワード選択システム、およびキーワード選択装置
【課題】様々な発話内容を待ち受けることができるキーワードを選択すること。
【解決手段】音声認識部112は、ディスク151に記録された音声認識対象単語の中から音響的な共通部分をキーワードとして選択し、選択したキーワードを用いてマイク130を介して入力された発話音声を認識する。
(もっと読む)
音声の類似度の評価を行う方法および装置
【課題】 音声の類似度の評価の雑音耐性を高める。
【解決手段】 特徴量比較部36は、1〜Nの各nについて、特徴量抽出部34により生成された入力音声の帯域間相関行列Aと登録情報選択部35により読み出された帯域間相関行列Bの一方の第n行および第n列を他方に代入し、あるいは帯域間相関行列AおよびBの両方から第n行および第n列を間引き、代入後または間引き後の両帯域間相関行列AおよびB間の類似度Dを算出する類似度算出処理を実行する。そして、認証結果出力部37は、各nについて実行された類似度算出処理において類似度Dが閾値th1以上となった回数に基づいて認証を行う。
(もっと読む)
時系列類似度スコアリング方法
【課題】時系列の複素周波数間の距離を求めることによって類似度を評価する方法を提供する。
【解決手段】本発明の一実施例によれば、入力部100にて時系列s1(t),s2(t)を取得し、所定の時間間隔Δtでサンプルする。次に、極解析部102でサンプルされた時系列を所定のモデルに従って極解析を行う。そして、複素周波数算出部104で極解析の結果から複素周波数を得る。この複素周波数間の距離を距離計算部106で計算し、この距離に基づいてスコアリング部108で時系列の類似度を評価する。出力部110は、評価結果を所定のフォーマットで出力する。複素周波数を算出する方法としては、全極モデルや零・極モデルを用いる方法、線形予測を用いる方法などがある。このように複素周波数間の距離によって時系列の類似度を評価することにより、位相変動やレベル変動に強い特徴抽出が可能となる。
(もっと読む)
ローカルモデルを用いた話者認識
音声認識のシステムおよび方法が開示される。システムは登録音声サンプルと識別情報を用いて話者を登録する。抽出モジュールは登録音声サンプルを高次特徴ベクトルまたは話者データポイントと関連付ける。データ構造化モジュールは、データポイント間の類似性がEuclid距離、Minkowski距離またはManhattan距離のような距離を規定するkd-treeのような高次データ構造へ、データポイントを体系化する。システムは未識別音声サンプルを用いて話者を認識する。データ問合せモジュールはデータ構造を検索して、抽出された高次特徴ベクトルに基づいて略最近傍のサブセットを生成する。データモデリングモジュールはParzen窓を用いて、広範な訓練データまたはデータ分布についてのパラメトリックな仮定無しで、未識別の話者の特徴がどの程度良く登録話者に一致するかを表す確率密度関数を実時間で予想する。円滑化パラメータは近傍話者データポイントおよび遠隔話者データポイントの予想密度に対する相対的な寄与を制御する。  (もっと読む)
(もっと読む)
信号探索装置、信号探索方法、信号探索プログラム及び記録媒体
【課題】蓄積信号から得られる蓄積特徴系列に対して情報量の削減を行うことで、探索時のメモリ容量の削減を可能とする信号探索装置を提供する。
【解決手段】信号探索装置100において、蓄積特徴計算部1は、蓄積信号から蓄積特徴系列を算出する。蓄積特徴ヒストグラム系列生成部2は、蓄積特徴系列から蓄積特徴ヒストグラム系列を生成して、蓄積特徴ヒストグラム系列DB3に記録する。入力特徴計算部4は、入力信号について入力特徴系列を算出する。部分蓄積特徴ヒストグラム系列生成部6は、蓄積特徴ヒストグラム系列に基づいて部分蓄積特徴ヒストグラム系列を生成する。特徴照合部7は、注目領域設定部5に設定される注目領域に照合区間を順次設定し、照合区間における入力特徴ヒストグラム系列を生成し、入力特徴ヒストグラム系列及び部分蓄積特徴ヒストグラム系列に基づいて入力信号に含まれる蓄積信号に関連する部分を検出する。
(もっと読む)
音声−数字変換装置および音声−数字変換プログラム
【課題】 話者の音声を数字に変換するための技術において、話者が発した名称から、名称と番号列との対応データを用いずに、その名称に対応する数字列を特定することができるようにする。
【解決手段】 音声−数字変換装置が、音声信号入力回路が取得した音声信号の先頭部の連続する数字に相当する部分を、音声−数字データベース181に基づいて数字列に変換し(ステップ232)、その変換した数字列が無料ダイヤル用の所定のプレフィックス番号列であるか否かを判定し、その判定が肯定なら、音声−文字データベースおよび音声−名称データベース183、取得したプレフィックス番号列に続く音声信号に対応する文字列を特定し(ステップ234)、さらに、文字−数字データベースに基づいてその特定した文字列に対応する数字列を特定し(ステップ235)、その対応する数字列を電話番号として表示する(ステップ236照)。
(もっと読む)
通訳装置、通訳方法、通訳プログラムを記録した記録媒体、および通訳プログラム
【課題】話者の声質にあったより近い合成音声を出力することが可能な通訳装置、通訳方法、通訳プログラムを記録した記録媒体、および通訳プログラムを提供する。
【解決手段】第1の言語で入力された入力音声を音声認識する音声認識部101と、音声認識された結果を第2の言語に翻訳する翻訳部102と、翻訳された第2の言語を音声合成する音声合成部103と、第1の言語の声質を分析する声質分析部104と、第1の言語の声質と第2の言語の声質との類似性を計量する声質類似性計量部105と、声質類似性計量部105で得られた声質類似性計量結果に基づいて、音声合成部103で音声合成される第2の言語の声質を制御する声質制御部106とを備えることにより、第1の言語の声質と第2の言語の声質とが比較的類似したものになり、違和感を生じるのを極力少なくすることができる。
(もっと読む)
情報処理方法、情報処理装置及びデータ処理装置
【課題】 HMM類似度に基づいて動画像を検索する。
【解決手段】 検索が受信される。検索は、時間情報を含むオブジェクトであり得る。静的成分及び時間成分を含む検索モデルが次に、オブジェクトについて判定される。静的成分及び時間成分に対する重み付けも判定される。検索モデルは次に、1つ又は複数のサーチ・モデルと比較される。サーチ・モデルも、静的成分及び時間成分を含む。サーチ結果が次に、比較に基づいて判定される。一実施例では、比較は、検索モデル及びサーチ・モデルの静的成分及び時間成分を比較し得る。静的成分と時間成分との差の重み付けは、サーチ結果のランク付けを判定するのに用い得る。
(もっと読む)
1 - 20 / 30
[ Back to top ]