
Fターム[5D015LL09]の内容
Fターム[5D015LL09]に分類される特許
1 - 13 / 13
音声認識装置とその方法とプログラム
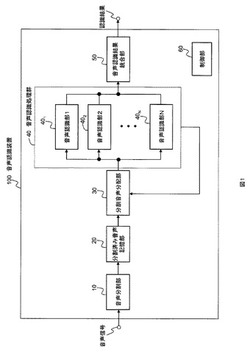
【課題】音声認識処理を並列に行うことで音声認識処理を高速にした音声認識装置を提供する。
【解決手段】この発明の音声認識装置は、音声分割部と、音声記憶部と、分割音声分配部と、音声認識処理群と、音声認識結果統合部と、を具備する。音声分割部は、音声信号を入力として、当該音声信号の音声・非音声判別を行い非音声区間の区間長が非音声分割区間長閾値Tp以上の場合に音声区間を分割し、上記音声信号を発話区間単位に分割した分割済み音声を出力する。そして、分割音声分配部は、分割済み音声記憶部に記憶された発話区間を、複数の音声認識部で構成された音声認識処理群に分配する。音声認識結果統合部は、音声認識処理群が出力する複数の音声認識結果を時間順に結合して、音声信号に対する音声認識結果を出力する。
(もっと読む)
音声処理装置、音声処理方法及び音声処理プログラム

【課題】音声データの認識処理を効率化すること。
【解決手段】入力した音声データを記憶する記憶手段と、前記記憶手段に記憶された音声データを分割する音声分割手段と、前記音声分割手段による分割によって生成された複数の部分音声データを少なくとも2つの音声認識エンジンを用いて認識し、文字データに変換する音声認識手段と、前記音声認識手段による認識結果としての文字データを統合して文書データを生成する統合手段と、を備えたことを特徴とする。
(もっと読む)
格納装置、格納方法、そのプログラム、その記録媒体
【課題】複数の音声認識装置で音声認識を行う際の通信量を削減する。
【解決手段】音声ファイル名カラム411−1、状態カラム411−2、状態更新カラム411−3、ダウンロードカラム411−4、移動失敗カラム411−5からなるエントリー411−6−1〜Nを記録するファイル管理テーブル411と、音声ファイル格納部414と、認識結果格納部415と、音声認識装置420−1〜Pのファイル取得要求を入力とし音声ファイル名を出力するファイル検索部4174と、音声ファイル名を入力とし音声認識装置420−1〜Pに音声ファイル名を送信するファイル名送信部4173と、音声認識装置420−1〜Pのファイルダウンロード要求を入力とし音声ファイルを送信するファイル送信部4172と、音声認識装置420−1〜Pの音声認識結果を入力とし当該音声認識結果を認識結果格納部415へ移動する認識結果受信部4171とを備える。
(もっと読む)
音声自動応答装置、音声自動応答方法および音声自動応答プログラム
【課題】 本発明は音声自動応答に関し、より詳細には音声認識によるCPU負荷を平準化して負荷過大による応答遅延を抑制した音声自動応答装置、音声自動応答方法および音声自動応答プログラムに関するものである。
【解決手段】 本発明の音声自動応答装置は、回線毎に対話シナリオに基づくタスクリストを記憶し、このタスクリストによりタスクを実行するシナリオ実行手段と、タスクリストを基にCPUリソース使用を時系列に表したリソース管理表を作成するリソース管理表作成手段と、リソース管理表を基に重負荷タスクのCPUリソース使用の重複度が所定値を超えるかどうかを判定する重複度判定手段と、重複度が所定値を超えた場合にガイダンスの処理時間を調整して負荷分散を行う負荷平準化手段と、タスクリストを調整されたガイダンスの処理時間に更新するタスクリスト更新手段とを備える、よう構成する。
(もっと読む)
並列認識タスクを用いた音声認識
本明細書の主題はとりわけ、音声信号を受け取ること、および複数の音声認識システム(SRS)で音声認識タスクを開始することを含む方法で実施される。各SRSは、音声信号内に含まれる予想される音声を指定する認識結果と、音声結果の正確さの信頼度を示す信頼値とを生成するように構成される。この方法はまた、1つまたは複数の認識結果、および1つまたは複数の認識結果に関する1つまたは複数の信頼値を生成することを含む音声認識タスクの一部を完了すること、1つまたは複数の信頼値が信頼閾値を満たすかどうかを判定すること、認識結果の生成を完了していないSRSに関する音声認識タスクの残りの部分を停止すること、および生成した1つまたは複数の音声結果のうちの少なくとも1つに基づいて最終的な認識結果を出力することをも含む。  (もっと読む)
(もっと読む)
音声認識における音響尤度並列計算装置及びそのプログラム
【課題】音響尤度計算の処理時間を短縮できる音声認識における音響尤度並列計算装置及びそのプログラムを提供することにある。
【解決手段】音響尤度計算は、音響特徴量保持部14と音響尤度並列計算部15で並列計算により行われる。該音響特徴量保持部14と音響尤度並列計算部15は、それぞれGPUメモリとGPUに相当し、該音響尤度計算は、GPGPUのピクセルシェーダの並列演算をカスケード接続することにより行われる。前記GPGPUのピクセルシェーダでは、データ記憶領域に確保された38次元の各々のμ、χに対し、演算式(2)第二項(χ−μ)の演算を一括実行して38次元の結果zを算出させ、該ピクセルシェーダにおいて、続けて、z、σに対し、演算式(2)第二項(z×z)/(σ×σ)の演算を一括実行し、38次元の結果P’を算出させる。そして、該P’を、38個加算することにより、音響特徴量の合計尤度が算出される。
(もっと読む)
音声対話装置
【課題】システム発話を適切に設定して利用者との対話を円滑に進行させる。
【解決手段】予測文に基づきユーザ発話を認識する予測認識処理が実行され(ステップS2)、大語彙辞書に基づきユーザ発話を認識する大語彙認識処理が実行される(ステップS3)。また、予測認識処理で求められた予測尤度と大語彙認識処理で求められた大語彙尤度とが比較され(ステップS4)、予測尤度が大語彙尤度を上回ると判定された後に、ユーザ発話を認識する部分単語認識処理が実行される(ステップS6)。続いて、予測認識処理で求められた文単位の予測認識結果と部分単語認識処理で求められた単語単位の部分単語認識結果とが比較され、認識結果の一致度(完全一致,部分一致,完全不一致)が判定される(ステップS7)。次いで、判定された一致度に応じてシステム発話の内容が別個に設定される(ステップS8〜10)。
(もっと読む)
音声対話装置
【課題】システム発話を適切に設定して利用者との対話を円滑に進行させる。
【解決手段】予測文に基づきユーザ発話を認識する予測認識処理が実行され、予測認識結果とこの結果の予測尤度とが出力される。また、大語彙辞書に基づきユーザ発話を認識する大語彙認識処理が実行され、大語彙認識結果とこの結果の大語彙尤度とが出力される。さらに、予測認識結果と大語彙認識結果とを比較する一致度算出処理が実行されて認識結果の一致度が算出される。続いて、予測尤度、大語彙尤度および一致度をパラメータとして統計的モデルを用いることにより、ユーザ発話の認識状況(予測内認識状況,予測内誤認識状況,予測外状況)が判別される。そして、判別された認識状況に応じてシステム発話の内容が設定されるとともに音声合成処理が実行される。これにより、適切にシステム発話の内容を設定することができ、利用者との対話を円滑に進行させることが可能となる。
(もっと読む)
音声認識装置、音声認識方法及び音声認識プログラム
【課題】使用者との対話の遷移状態を適切に反映して、使用者の発話を精度良く認識することができる音声認識装置、音声認識方法及び音声認識プログラムを提供する。
【解決手段】音声認識装置1は、入力音声の認識結果に基づいて制御対象に対する制御処理を行う。言語モデル16を用いて入力音声を言語的な特徴に基づいて認識する第1の音声認識手段31と、入力音声を認識対象語彙と比較して認識する第2の音声認識手段32,33と、制御処理の状態の遷移を検知する状態遷移検知手段34と、状態遷移検知手段34の検知結果に基づいて第1の音声認識手段31の処理に対する第1の重みと、第2の音声認識手段32,33の処理に対する第2の重みとを、それぞれ決定する重み決定手段35と、第1,第2の音声認識手段31,32,33による音声認識処理と第1,第2の重みとを用いて、最終的な認識結果を決定する認識結果決定手段36とを備える。
(もっと読む)
音声認識装置及びナビゲーションシステム
【課題】音声認識辞書の更新を行わなくても認識性能の低下を抑えることのできる音声認識技術を提供する。
【解決手段】電話番号に関する音声認識に際して、固定電話の電話番号として実際に存在する番号に対応する辞書である電話番号辞書312a及び数字フリー且つ桁数フリーの数字列辞書312bの両方を用いる。認識率が相対的に高い電話番号辞書312aだけであれば、市外局番、市内局番などが変更されると、変更されるたびに音声認識辞書の更新が必要となる。さらに、携帯電話の番号なども認識可能とするのであれば、頻繁に追加・変更される番号を認識可能にするため音声認識辞書の更新も頻繁に行わなければならなくなってしまう。このような更新作業は非常に煩わしい。しかし、数字列辞書312bを用いた音声認識を行うことができるため、更新作業が不要である。
(もっと読む)
音声認識装置及びプログラム
【課題】音声認識装置及びプログラムを提供する。
【解決手段】
単語認識部201は音声の単語認識を行い単語列候補と対数ゆう度を求める。音節認識部211は音声の音節認識を行い音節列候補と対数ゆう度を求める。音素認識部221は音声の音素認識を行い音素列候補と対数ゆう度を求める。単語正規化ゆう度計算部203は正規化ゆう度を求め、単語条件付確率計算部207は単語条件付確率を求める。音節正規化ゆう度計算部213は正規化ゆう度を求め、音節条件付確率計算部217は音節条件付確率を求める。音素正規化ゆう度計算部223は正規化ゆう度を求め、音素条件付確率計算部227は音素条件付確率を求める。対話管理部208は単語条件付確率と音節条件付確率と音素条件付確率とに基づいて信頼度を求め、単語列候補を受理又は棄却する。
(もっと読む)
音声入力された複合名詞の検索装置、検索方法およびデータベース
【課題】対話処理実時間内で処理可能な検索語数を超える数の複合名詞が検索データベースに登録され、しかも、互いに似通った候補が数多く存在する複合名詞が検索データベースに登録されている場合、利用者が音声入力した検索語を、短時間で効率良く検索することができるようにする。
【解決手段】先頭拍を認識した結果、利用者が入力した拍である可能性が高い有力先頭拍であると判断した場合、有力先頭拍に繋がり、使用頻度が高い拍から、優先的に認識処理し、有力2番目拍を抽出し、検索情報を構成する最後の拍まで、認識処理を繰り返す認識処理繰り返し、全ての拍に対する認識処理が終了した時点で、出力された検索情報毎に、トータルスコアを計算し、ユーザが確認処理するのみで検索情報を特定できる条件を、トータルスコアが満たす場合、利用者との間で対話を実行する。
(もっと読む)
ベクトルコードブック生成方法、データ圧縮方法及び装置、並びに分散型音声認識システム
Q個の特徴を有する入力ベクトルにより表されるデータの圧縮方法であって、ここで、Qは1より大きな整数であり、1)インデックス付きQ特徴基準ベクトルからなる部分集合、及び所定の特徴について前記部分集合に関連付けられたしきい値を含んだベクトルコードブックを得る工程と;2)前記所定の特徴に対応する入力ベクトルの特徴の値を前記部分集合に関連付けられた前記しきい値と漸次比較することによって、前記部分集合から基準ベクトルの部分集合を特定する工程と;3)工程2)で特定した部分集合内で前記入力ベクトルに対して最小歪みを与える基準ベクトルを特定する工程と;を含む方法。  (もっと読む)
(もっと読む)
1 - 13 / 13
[ Back to top ]