
国際特許分類[G10L13/02]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 音声の合成;テキストを音声に変換するシステム (2,199) | 合成音作成の方法;音声合成器 (464)
国際特許分類[G10L13/02]の下位に属する分類
国際特許分類[G10L13/02]に分類される特許
101 - 110 / 365
カラオケ装置及びその制御方法並びにその制御プログラム

【課題】歌唱者の歌唱を妨げることなく、歌詞と主旋律の両方を歌唱者に音声で教示できるカラオケ装置及びその制御方法並びにその制御プログラムを提供する。
【解決手段】楽曲の伴奏音楽データと、前記楽曲の主旋律と、前記楽曲の歌詞とを取得し、前記歌詞と、前記歌詞の各音韻に割り当てられる前記主旋律のピッチと、前記主旋律を構成する音符と休符とがそれぞれ表す時間長さを任意の変更率をかけて短縮した前記音律の継続時間長とから韻律情報を生成し、前記歌詞を発声するためのリード音声を前記韻律情報から音声合成し、前記楽曲の伴奏音楽データから生成された前記楽曲の伴奏音の演奏を行うと共に、前記歌詞に対応する前記伴奏音が演奏される前に前記リード音声を出力し始める。
(もっと読む)
音声再生装置、集積回路装置及び電子機器

【課題】音声メッセージを単語や文節に基づいて分割した音声データを組み合わせて音声メッセージを再生する場合において、音声再生コマンドにより分割した音声データの再生順序を指定せずに音声再生を行う音声再生装置、集積回路装置、電子機器を提供すること。
【解決手段】少なくとも1つの入力ピンを有する音声再生装置10は、前記入力ピンからの入力情報に基づいてフレーズの音声情報の再生順序に関するシーケンス情報44を選択するシーケンス情報選択部20と、選択された前記シーケンス情報44に従って前記フレーズに対応する音声情報に基づいて音声を再生する音声再生部30とを含む。
(もっと読む)
信号経路を分離する方法及び電気喉頭を使用して音声を改良するための使用方法
音声信号が適当な手段によってデジタル化される電気喉頭(EL)話者の音声品質を向上させるために、次の工程を実施する:
a)時間領域から離散周波数領域へ単一チャネル音声信号を転送することによって、前記単一チャネル音声信号を一連の周波数チャネルに分割する工程;
b)各周波数チャネルにおいてハイパスフィルタ又はノッチフィルタを用いてELの変調周波数をフィルタ処理して除去する工程;及び
c)フィルタ処理音声信号を周波数領域から時間領域に逆変換し、そして、それを単一チャネル出力信号に結合する工程。 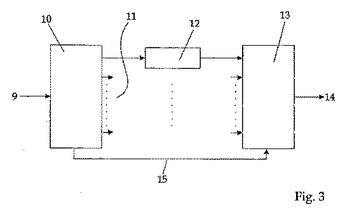 (もっと読む)
(もっと読む)
経路情報案内装置及び方法並びにプログラム
【課題】経路上の案内地点付近において、ユーザの再音声要求に基づき、ユーザに分かり易い再音声出力を行なうことのできる経路情報案内装置及び方法並びにプログラムを提供する。
【解決手段】再出力受付部31が、再音声出力要求を受付けると、案内位置・時刻記憶部32が現在時刻を記憶し、再出力カウント部33が音声再出力要求の回数をカウントする。案内速度設定部35は、再出力カウント部33において検出された再音声出力要求の回数に応じて、案内速度を設定する。案内速度設定部35において設定された案内速度に基づいて音声案内出力部36が、スピーカ9を介して、再音声出力を行なう。
(もっと読む)
音声処理装置、チャットシステム、音声処理方法、ならびに、プログラム
【課題】ユーザ同士の声による意思疎通をある程度可能としつつ、不適切な会話がなされないようにする音声処理装置等を提供する。
【解決手段】チャットシステム211は、2つの音声処理装置201から構成され、各音声処理装置201において、入力受付部202は、ユーザが発する声の入力を受け付け、抽出部203は、受け付けられた声の特徴パラメータを抽出し、生成部204は、所定の音声データから合成音声を生成し、出力部205は、生成された合成音声を出力し、典型的には、特徴パラメータとして、波形の振幅もしくは音量、基本周波数成分の大きさ、または、所定の代表周波数成分の大きさの時間変化を用い、所定の音声データの特徴パラメータを、抽出された特徴パラメータに置き換えることによって、合成音声を生成する。
(もっと読む)
情報処理装置、情報処理方法および情報処理プログラム
【課題】空間内でのユーザーの手などの動きに応じた操作入力(ジェスチャー)に応じて、音声情報などの情報信号を効果的に処理できるようにする。
【解決手段】センサ部10を通じて、例えばユーザーの手などの検出対象物により指定される所定の空間内における三次元座標を検出する。センサ部10を通じて検出した当該三次元座標が含まれる予め指定された領域が、空間位置検出部406により判断される。空間位置検出部405が判断した検出対象物により指定された三次元座標が含まれる領域に基づいて、当該三次元座標のうち少なくとも二次元座標に対応する位置(二次元座標に応じた位置)のスピーカから音声情報に応じた音声を出力するように、音声処理部410を制御する。
(もっと読む)
情報処理装置及びテキスト読み上げ方法
【課題】情報の一部が欠けていても自然な音声フレーズの組み立てにより自然なトークバックをすることが可能な「情報処理装置及びテキスト読み上げ方法」を提供すること。
【解決手段】楽曲を再生する情報処理装置100は、音声読み上げ手段6と、ユーザの質問に対する回答の定型文及び定型文の変換規則が格納された記憶手段10と、ユーザからの質問を入力する入力手段2と、楽曲データを格納した機器から楽曲データ及び楽曲データに付随した楽曲情報を取得する制御手段1とを有する。制御手段1は、ユーザからの楽曲に対する質問を解析して質問に応じた回答文の定型文を選択し、楽曲の楽曲情報から定型文に含まれる置換記号部分を置換する文字を検出して文字が音声再生可能か否かに応じて定型文を変換し、変換した定型文を用いて音声読み上げ用のテキストを生成し、テキストを音声読み上げ手段を介して読み上げさせる。
(もっと読む)
音声合成装置、およびプログラム
【課題】素片接続方式の音声合成において、データベース化する素片の数が従来よりも少なくしても自然な音声を合成できるようにする。
【解決手段】曲を構成する音符とその歌詞を示す歌詞データとを示す曲データに基づき、その曲の歌唱音声を合成するのに用いる複数の音声素片、それらの発生時刻、その歌唱音声のピッチを指定する歌唱合成スコア(音声合成指示)を生成する。そして、データベース化された音声素片のうちから歌唱合成スコアにより指定されるものを選択する際に、無声摩擦音から無音への遷移部分を示す音声素片については、無音から当該無声摩擦音への遷移部分の音声素片を選択し、その音声素片の波形に時間反転を施して歌唱音声の合成に使用する。
(もっと読む)
応答生成装置及びプログラム
【課題】ユーザからの入力内容に対応した適切な応答文を生成して、自然な対話を行う。
【解決手段】マイク12から入力された第1のユーザ発話を音声認識し、音声認識された第1のユーザ発話に対して形態素解析を行った解析結果に基づいて、事態判別部22で、第1のユーザ発話に事態が含まれているか否かを判別し、事態が含まれている場合に、感情極性推定部24で、第1のユーザ発話が表す感情極性を推定し、質問生成部26で、ユーザに感情を尋ねる質問文を生成して出力する。感情極性抽出部28が、質問文に対する第2のユーザ発話の解析結果から感情極性を抽出し、極性一致判別部30が、推定された感情極性と抽出された感情極性とが一致するか否かを判別する。応答生成部32は、感情極性が一致する場合は、「同意」を示す応答文を生成し、一致しない場合は、「驚き」を示す応答文を生成、または相槌や促しの定型応答文から応答文を選択する。
(もっと読む)
音声合成装置および音声処理システム
【課題】音声側の帯域を制限する必要がなく、聴感上の違和感が皆無である変調信号を重畳することができる音声合成装置を提供する。
【解決手段】音源13のうち、ノイズ音の音色を示す波形メモリ131Nは、PN符号のような自己相関性の高い疑似雑音符号列(疑似ノイズ音の波形)として波形が記憶されている。この波形メモリ131Nの疑似雑音符号列の極性を制御部14が制御することで、データ通信を行うことができる。送信データ141のビットデータが「1」の場合、PN符号をそのままの極性で出力し、送信データ141のビットデータが「0」の場合、PN符号の極性を逆(逆位相)にして出力する。
(もっと読む)
101 - 110 / 365
[ Back to top ]