
国際特許分類[G10L15/04]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 音声認識 (6,879) | セグメンテーション,または語区切れ検出 (272)
国際特許分類[G10L15/04]に分類される特許
101 - 110 / 272
録画録音情報処理装置及び録画録音情報処理方法並びにそのプログラム、録画録音情報処理システム
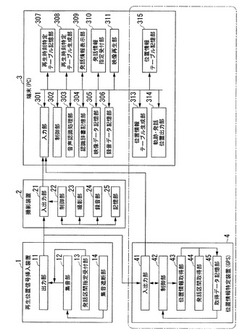
【課題】調査報告のデータを作成する効率化を図り、ビデオ映像を有効利用することのできる録画録音情報処理装置を提供する。
【解決手段】再生位置信号挿入装置がユーザの発話区間の信号を発信し、撮影装置が発話区間の信号を受け付けて、撮影時の音と発話区間の信号の音とを録音する。端末は撮影装置から映像データと録音データを受信して、発話区間の文字列を認識し、発話区間毎に認識した文字列と、当該発話区間の発話区間開始時刻と、その発話区間のIDとを少なくとも対応付けた再生時刻特定テーブルを生成し、認識した文字列とその文字列を発話した発話区間の識別情報とを発話区間毎に表示する。発話区間のIDの指定を受け付け、発話区間の識別情報に対応する発話区間開始時刻を再生時刻特定テーブルから特定して、発話区間開始時刻からの録画した映像と録音した音を再生する。
(もっと読む)
音楽音響信号と歌詞の時間的対応付けを自動で行うシステム及び方法

【課題】従来よりもアラインメント精度を高めることができる音楽音響信号と歌詞の時間的対応付けを自動で行うシステムを提供する。
【解決手段】非摩擦音区間抽出部4は、音楽音響信号から摩擦音が存在しない区間を抽出する。アラインメント部17は、時間的対応付け用特徴量に対応する音素を推定する歌声用音響モデル15を備える。アラインメント部17は、時間的対応付け用特徴量抽出部11から得た時間的対応付け用特徴量と、歌声区間推定部9から得た歌声区間と非歌声区間に関する情報と、音素ネットワークSNとを入力として、少なくとも非歌声区間には音素が存在しないという条件及び摩擦音が存在しない区間には摩擦音となる音素が存在しないという条件の下で、アラインメント動作を実行する。
(もっと読む)
音声認識装置、プログラム、及び発話信号抽出方法
【課題】発話期間全体での音響信号(即ち、発話信号)を抽出する発話信号抽出方法、その発話信号抽出方法を実行する音声認識装置、及びプログラムの提供。
【解決手段】音声認識装置が実行する発話期間抽出処理では、音響信号の信号レベルPが、時間閾値T1以上継続して音声判定閾値Pt以上となる期間を音声期間として特定して、第二メモリに格納する(S260〜S320)。音声期間の開始時点である基準開始時点よりも前の時間閾値T3分の音響信号(S250)、及び音声期間の終了時点である基準終了時点よりも後の時間閾値T4分の音響信号(S340)も、音声保存期間の一部として第二メモリに格納する。音声保存期間を含む期間(時間閾値T5から時間閾値T6)の間に、予め設定されたキーワードが検出されると、第二メモリに格納された音声保存期間での音響信号を発話信号として、その発話信号に対して音声認識処理を実行する。
(もっと読む)
音処理装置およびプログラム
【課題】音声/非音声を高精度に判定する。
【解決手段】変調スペクトル特定部32は、複数の単位区間TUの各々について入力音VINの変調スペクトルMSを特定する。指標算定部34は、変調スペクトルMSのうち変調周波数が10Hz以下の強度L1と変調周波数の全範囲にわたる強度L2とに応じた指標値D1(D1=1−(L1/L2))を算定する。判定部42は、指標値D1が閾値THd1を上回る単位区間TUの入力音VINを非音声と判定し、指標値D1が閾値THd1を下回る単位区間TUの入力音VINを音声と判定する。
(もっと読む)
音声認識装置、プログラム、及び発話信号抽出方法
【課題】発話期間全体での音響信号(即ち、発話信号)を抽出する発話信号抽出方法、その発話信号抽出方法を実行する音声認識装置、及びプログラムの提供。
【解決手段】音声認識装置が実行する発話期間抽出処理では、音響信号の信号レベルPが、時間閾値T1以上継続して音声判定閾値Pt以上となる期間を音声期間として特定して、第二メモリに格納する(S260〜S320)。音声期間の開始時点である基準開始時点よりも前の時間閾値T3分の音響信号(S250)、及び音声期間の終了時点である基準終了時点よりも後の時間閾値T4分の音響信号(S340)も、音声保存期間の一部として第二メモリに格納する。音声保存期間を含む期間(時間閾値T5から時間閾値T6)の間に、ユーザからの指令が入力されると、第二メモリに格納された音声保存期間での音響信号を発話信号として、その発話信号に対して音声認識処理を実行する。
(もっと読む)
音処理装置およびプログラム
【課題】音声/非音声を高精度に判定する。
【解決手段】変調スペクトル特定部32は、複数の単位区間TUの各々について入力音VINの変調スペクトルMSを特定する。指標算定部34は、変調スペクトルMSのうち変調周波数が10Hz以下の強度L1に応じた指標値D1を算定する。記憶装置24は、母音の音声から生成された音響モデルMを記憶する。指標算定部54は、入力音VINと音響モデルMとの類否を示す指標値D2を単位区間TU毎に算定する。判定部42は、各単位区間TUの入力音VINが音声か非音声かを当該単位区間TUの指標値D1と指標値D2とに基づいて判定する。
(もっと読む)
音声認識装置
【課題】音声認識された文字列の正誤を容易に判別できるように、トークバック音声を出力する「音声認識装置」を提供する。
【解決手段】マイクロフォン1から入力する、ユーザの発声「024 636 0123」に対して、音声認識部32は間合いの無音区間で区切られた有音区間毎に音声認識を行って、各認識部分文字列「024」、「636」、「0123」を得る。トークバック音声データ生成部34は、各認識部分文字列「024」、「636」、「0123」を間にスペース文字を挿入した形態で連結し、文字列「024 636 0123」を生成する。そして、生成した文字列「024 636 0123」をトークバック音声データとして、音声生成装置35に出力する。音声生成装置35は、トークバック音声データを読み上げた音声を表す音声信号を生成し、スピーカ2から出力する。
(もっと読む)
音信号処理装置およびプログラム
【課題】発音区間の特定の精度を向上する。
【解決手段】特徴量算定部54は、音解析装置80が音信号Sの解析に使用する特徴量Cを音信号Sの各フレームFについて順次に算定する。フレーム情報生成部56は、音信号Sの各フレームFについてフレーム情報F_HISTを生成して記憶部64に格納する。第1区間特定部30は、音信号Sについて発音区間P1を特定する。出力制御部62は、発音区間P1の各フレームFの特徴量Cを順次に音解析装置80に出力する。第2区間特定部40は、発音区間P1を短縮した発音区間P2を、記憶部64に格納されたフレーム情報F_HISTに基づいて特定して音解析装置80に通知する。
(もっと読む)
雑音抑圧装置、音声認識装置、雑音抑圧方法、及びプログラム
【課題】複数種類の変動する雑音や未知の雑音の重畳された音声から、雑音を除去する雑音抑圧装置を提供する。
【解決手段】訓練用の音声や雑音の音響モデルである音声雑音音響モデルが複数記憶される音声雑音音響モデル記憶部14、二種以上の音声や雑音が合成された音響モデルである合成音響モデルが記憶される合成音響モデル記憶部15、音声と雑音の種類のラベルと音響モデルを対応付ける辞書情報が記憶される辞書情報記憶部17、雑音重畳音声データを受け付ける受付部19、音響モデル、辞書情報を用いて、雑音重畳音声データに対応するラベルを認識するラベル認識部20、認識されたラベルに応じた音響モデルからパーティクルをサンプリングし、そのサンプリングしたパーティクルを更新することによってクリーン音声データを生成するパーティクルフィルタ雑音抑圧部21を備える。
(もっと読む)
音声処理装置、音声処理システム及び音声処理プログラム
【課題】同時発話が発生しても、話者毎に発話内容を明確に再生すること。
【解決手段】信号処理部4は、複数の音声データより話者を特定する話者特定部42と、話者特定部42によって少なくとも第1及び第2の話者を特定した場合に、特定された第1及び第2の話者が発話した発話区間を特定し、第1及び第2の話者が同時に発話した区間を同時発話区間として判定する同時発話区間判定部43と、を備える。また、信号処理部4は、同時発話区間判定部43で判定された同時発話区間の第1の話者の音声データと第2の話者の音声データとを分離し、分離された各話者の音声データをそれぞれ時間的に異なるタイミングとして出力させる整列部45と、を備える。
(もっと読む)
101 - 110 / 272
[ Back to top ]